

Effect of removing outliers on statistical inference: implications to interpretation of experimental data in medical research
- PMID: 32923665
- PMCID: PMC7485938
- DOI: 10.18590/mjm.2018.vol4.iss2.9
Effect of removing outliers on statistical inference: implications to interpretation of experimental data in medical research
Abstract
Background: Data editing with elimination of "outliers" is commonly performed in the biomedical sciences. The effects of this type of data editing could influence study results, and with the vast and expanding amount of research in medicine, these effects would be magnified.
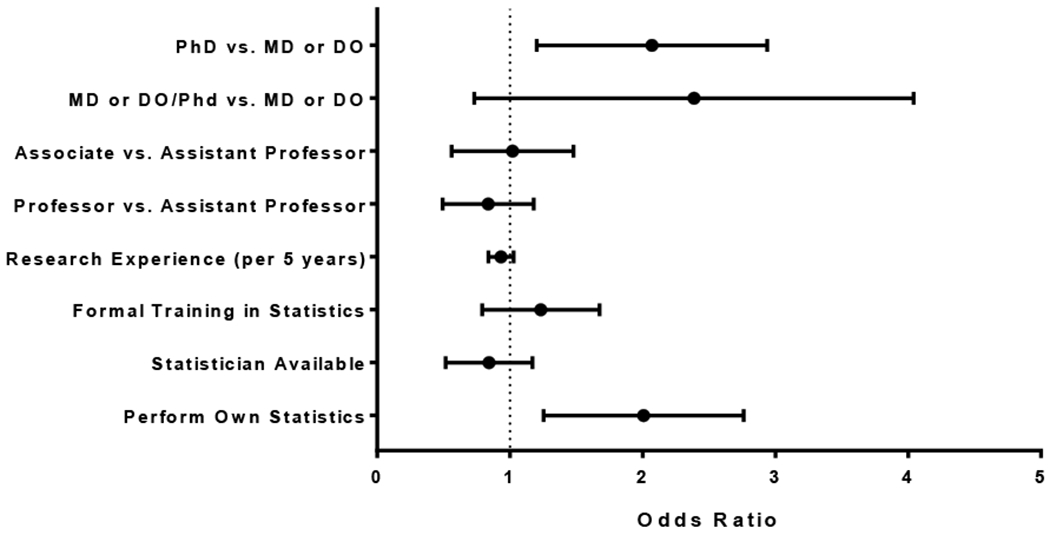
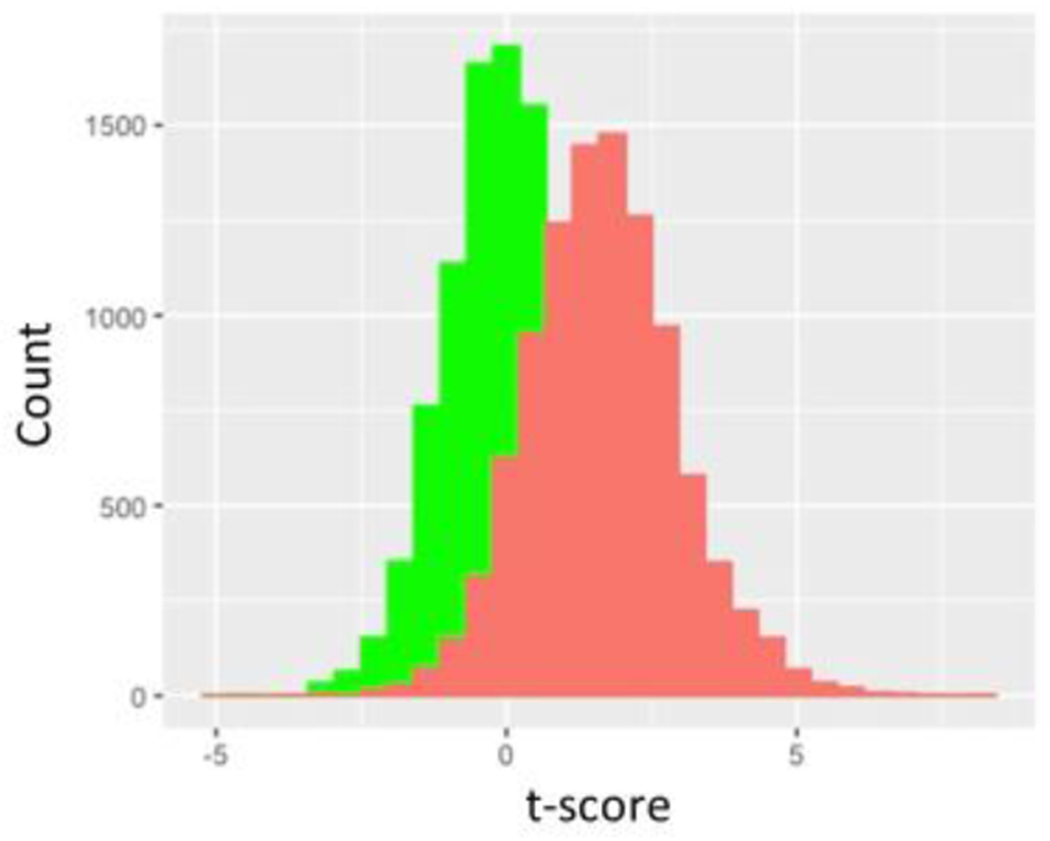
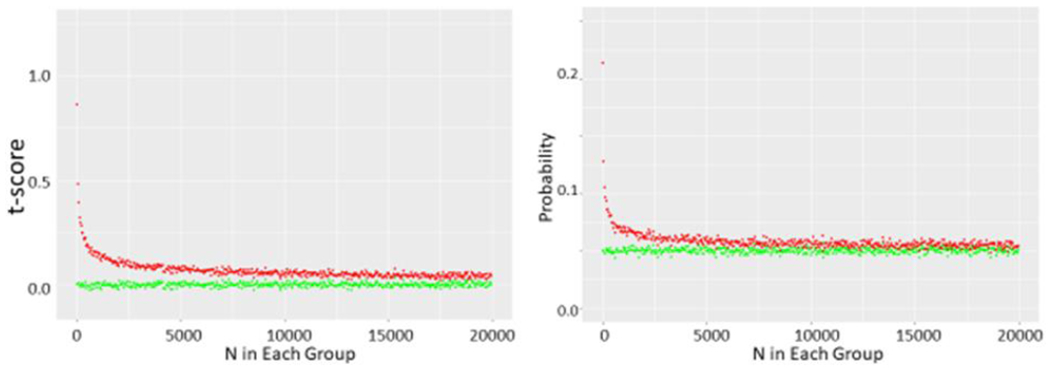
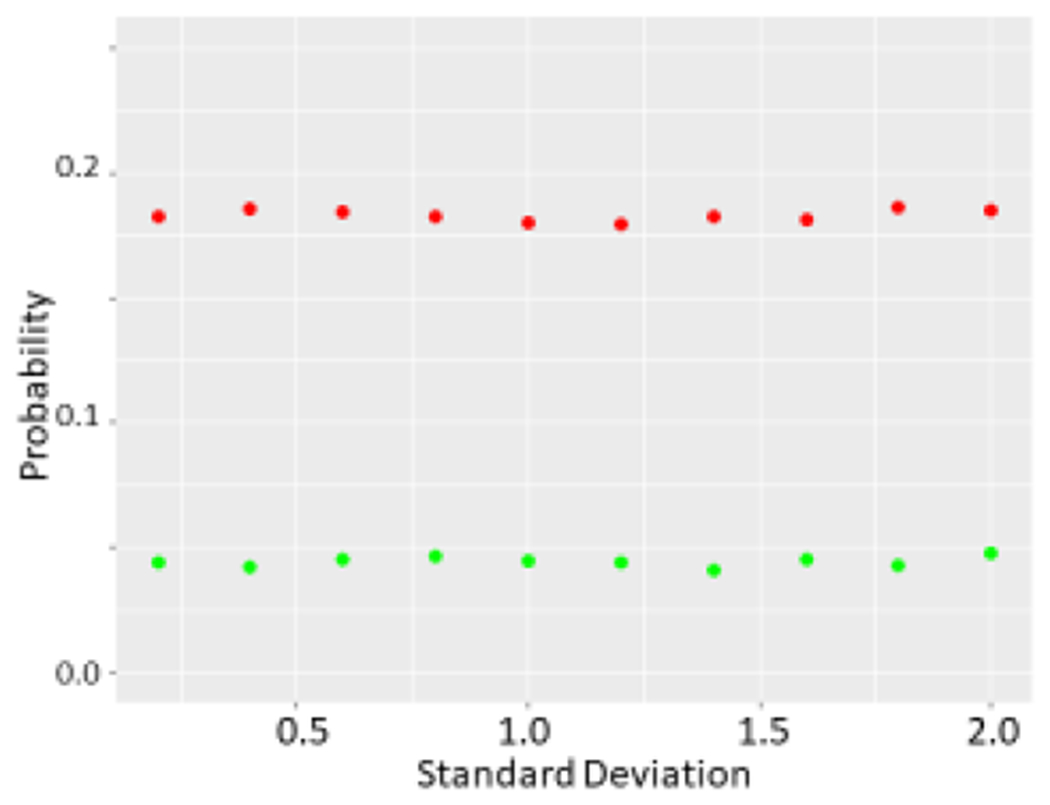
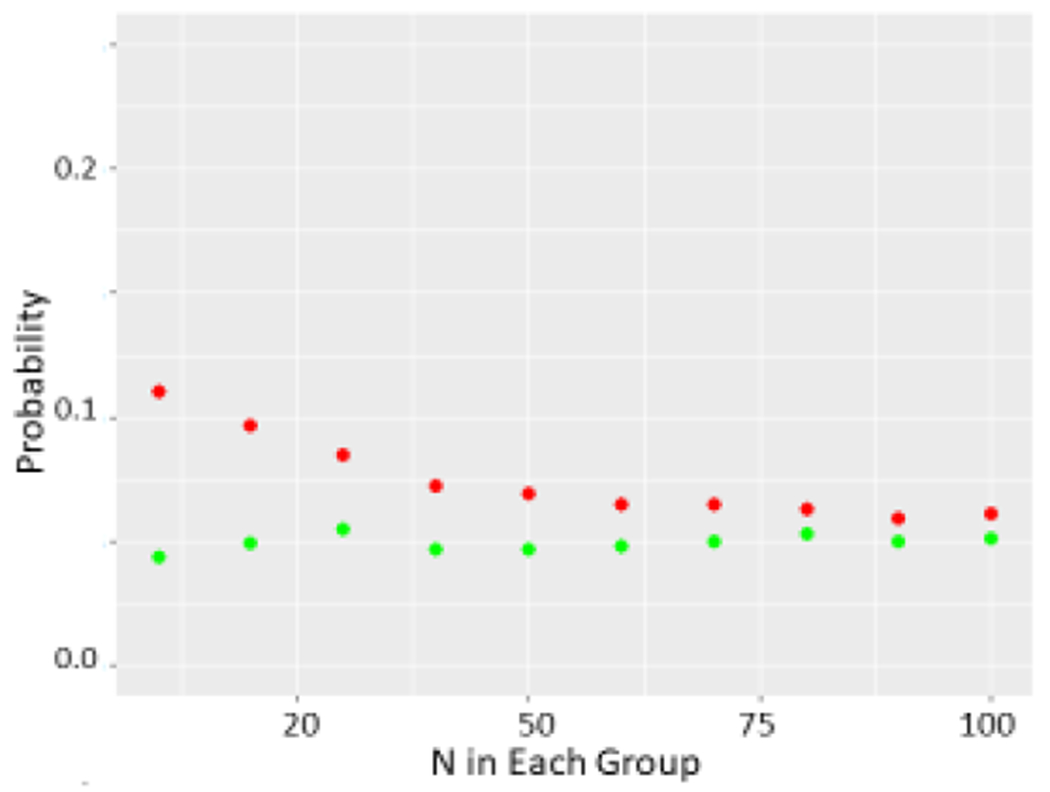
Methods and results: We first performed an anonymous survey of medical school faculty at institutions across the United States and found that indeed some form of outlier exclusion was performed by a large percentage of the respondents to the survey. We next performed Monte Carlo simulations of excluding high and low values from samplings from the same normal distribution. We found that removal of one pair of "outliers", specifically removal of the high and low values of the two samplings, respectively, had measurable effects on the type I error as the sample size was increased into the thousands. We developed an adjustment to the t score that accounts for the anticipated alteration of the type I error (tadj=tobs-2(log(n)^0.5/n^0.5)), and propose that this be used when outliers are eliminated prior to parametric analysis.
Conclusion: Data editing with elimination of outliers that includes removal of high and low values from two samples, respectively, can have significant effects on the occurrence of type 1 error. This type of data editing could have profound effects in high volume research fields, particularly in medicine, and we recommend an adjustment to the t score be used to reduce the potential for error.
Keywords: experimental design; non-parametric; normal distribution; outliers; parametric.
Conflict of interest statement
The authors have no financial disclosures to declare and no conflicts of interest to report.
Figures



References
-
- Wade N, Broad WJ. Betrayers of the truth. First ed: New York: Simon and Schuster; 1983.
Grants and funding
LinkOut - more resources
Full Text Sources