

MassIVE.quant: a community resource of quantitative mass spectrometry-based proteomics datasets
- PMID: 32929271
- PMCID: PMC7541731
- DOI: 10.1038/s41592-020-0955-0
MassIVE.quant: a community resource of quantitative mass spectrometry-based proteomics datasets
Abstract
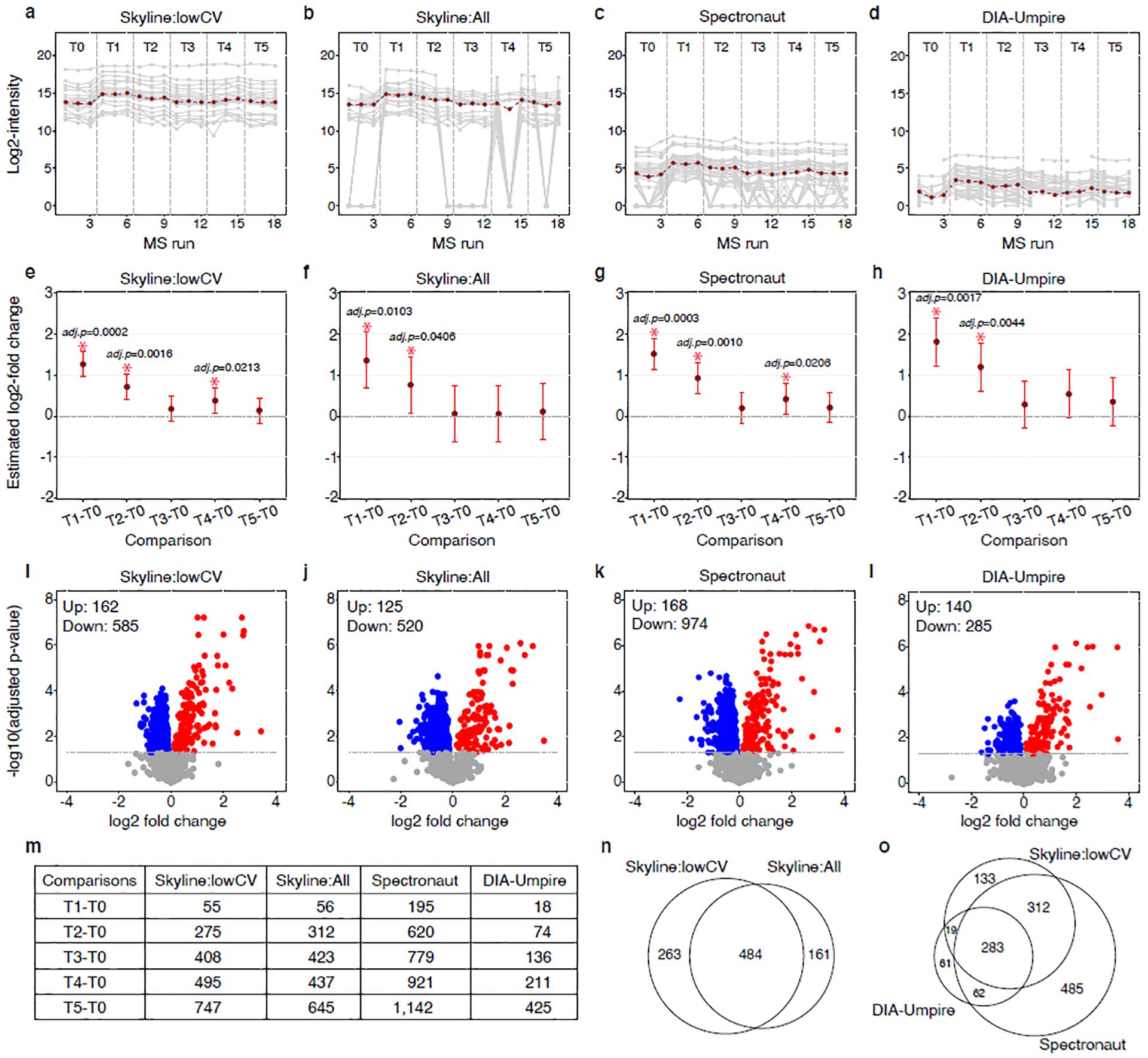
MassIVE.quant is a repository infrastructure and data resource for reproducible quantitative mass spectrometry-based proteomics, which is compatible with all mass spectrometry data acquisition types and computational analysis tools. A branch structure enables MassIVE.quant to systematically store raw experimental data, metadata of the experimental design, scripts of the quantitative analysis workflow, intermediate input and output files, as well as alternative reanalyses of the same dataset.
Conflict of interest statement
Competing financial interests
O.M.B., J.M. and L.R. are employees of Biognosys AG. Spectronaut is a trademark of Biognosys AG. M.T. and T.D. are employees of Hoffmann-La Roche Ltd. All other authors declare no competing financial interests.
Figures

References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
