

Revealing the structure of pharmacobehavioral space through motion sequencing
- PMID: 32958923
- PMCID: PMC7606807
- DOI: 10.1038/s41593-020-00706-3
Revealing the structure of pharmacobehavioral space through motion sequencing
Abstract
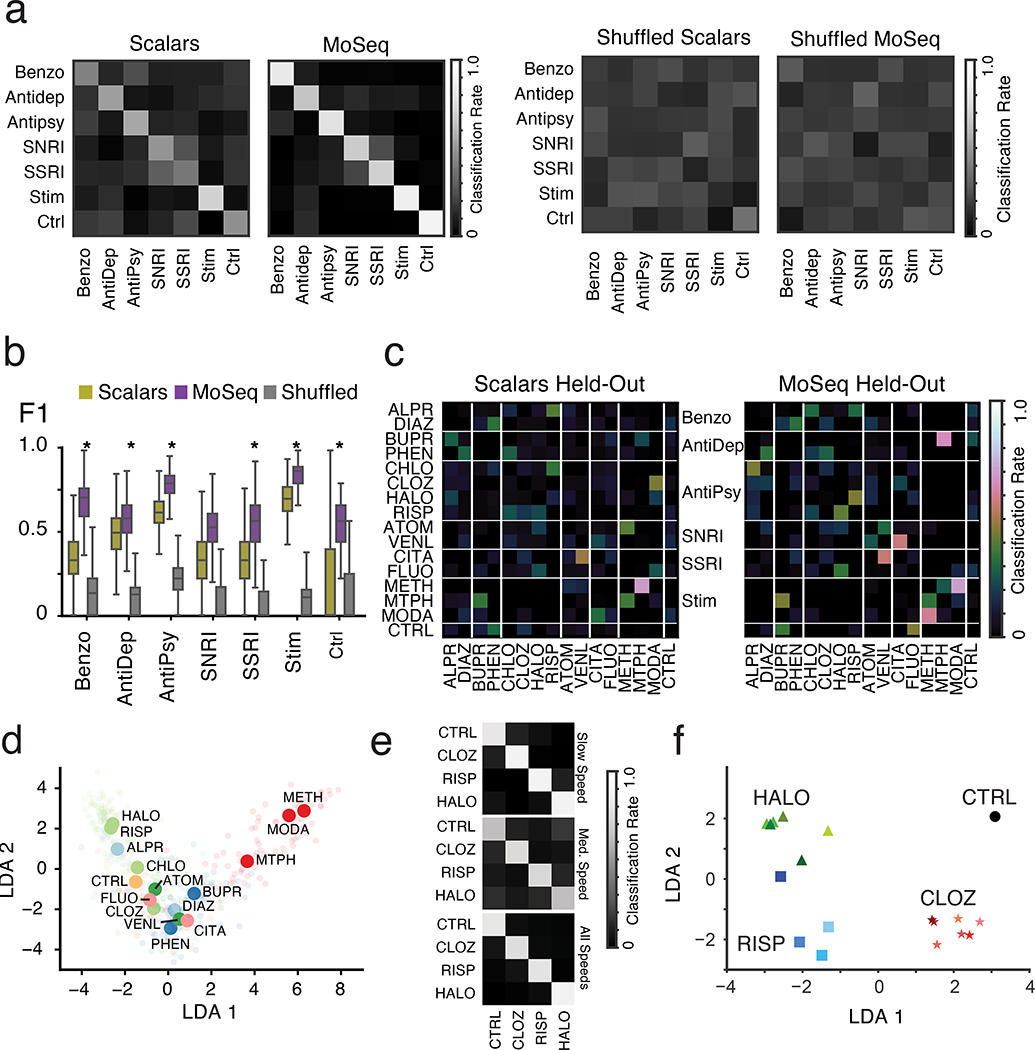
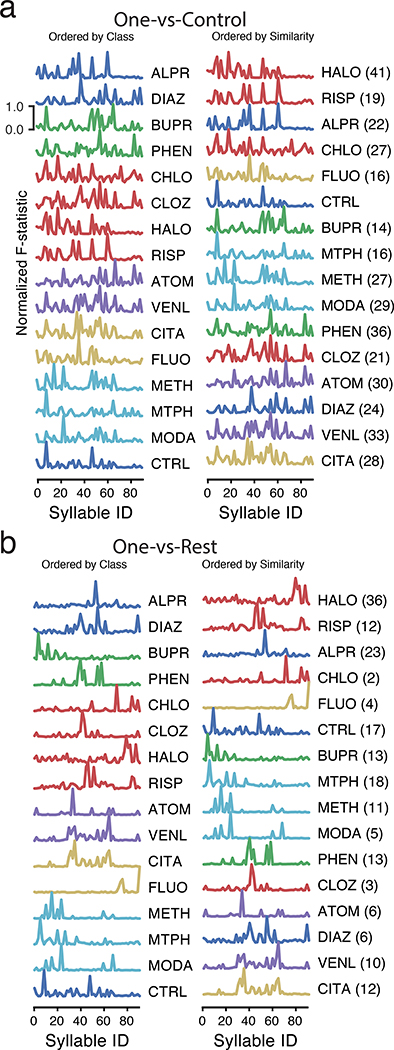
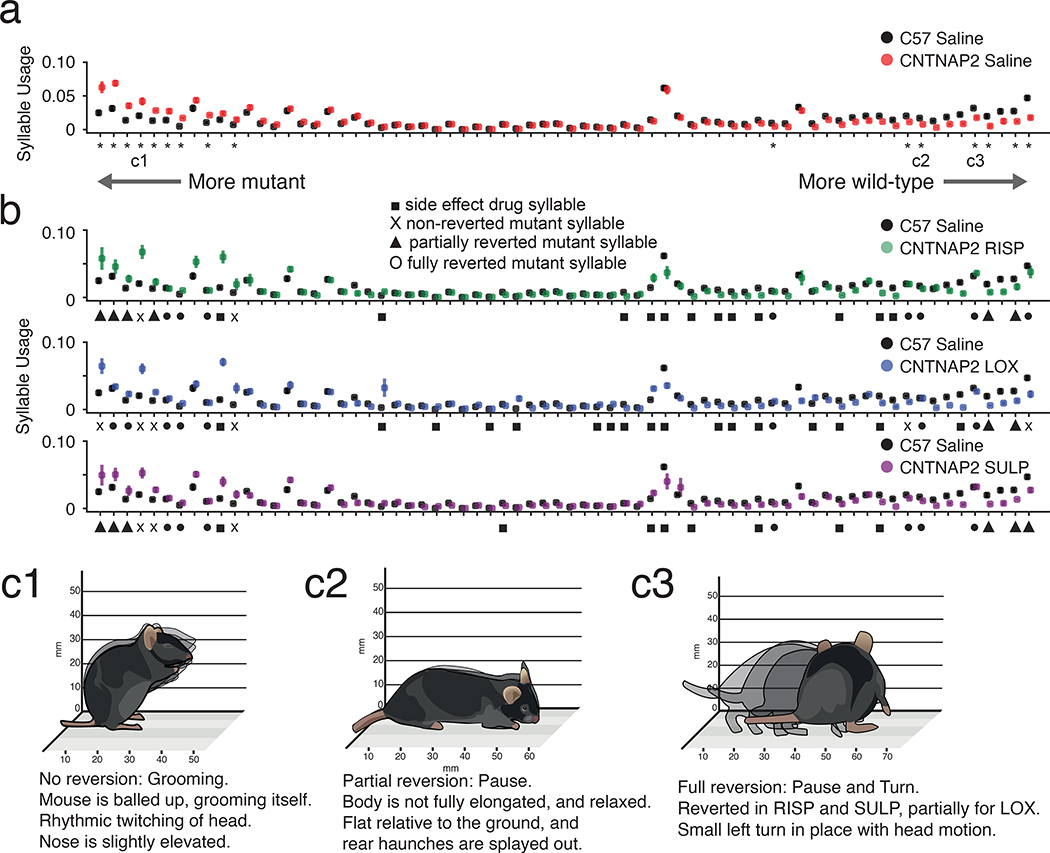
Understanding how genes, drugs and neural circuits influence behavior requires the ability to effectively organize information about similarities and differences within complex behavioral datasets. Motion Sequencing (MoSeq) is an ethologically inspired behavioral analysis method that identifies modular components of three-dimensional mouse body language called 'syllables'. Here, we show that MoSeq effectively parses behavioral differences and captures similarities elicited by a panel of neuroactive and psychoactive drugs administered to a cohort of nearly 700 mice. MoSeq identifies syllables that are characteristic of individual drugs, a finding we leverage to reveal specific on- and off-target effects of both established and candidate therapeutics in a mouse model of autism spectrum disorder. These results demonstrate that MoSeq can meaningfully organize large-scale behavioral data, illustrate the power of a fundamentally modular description of behavior and suggest that behavioral syllables represent a new class of druggable target.
Conflict of interest statement
Competing Interest Statement
The authors declare the following competing interests: ABW, MJJ and SRD are co-founders of Syllable Life Sciences, Inc. ABW and SRD are co-authors on awarded patents WO2013170129A1 and US10025973B2, which describe behavioral methods used herein.
Figures

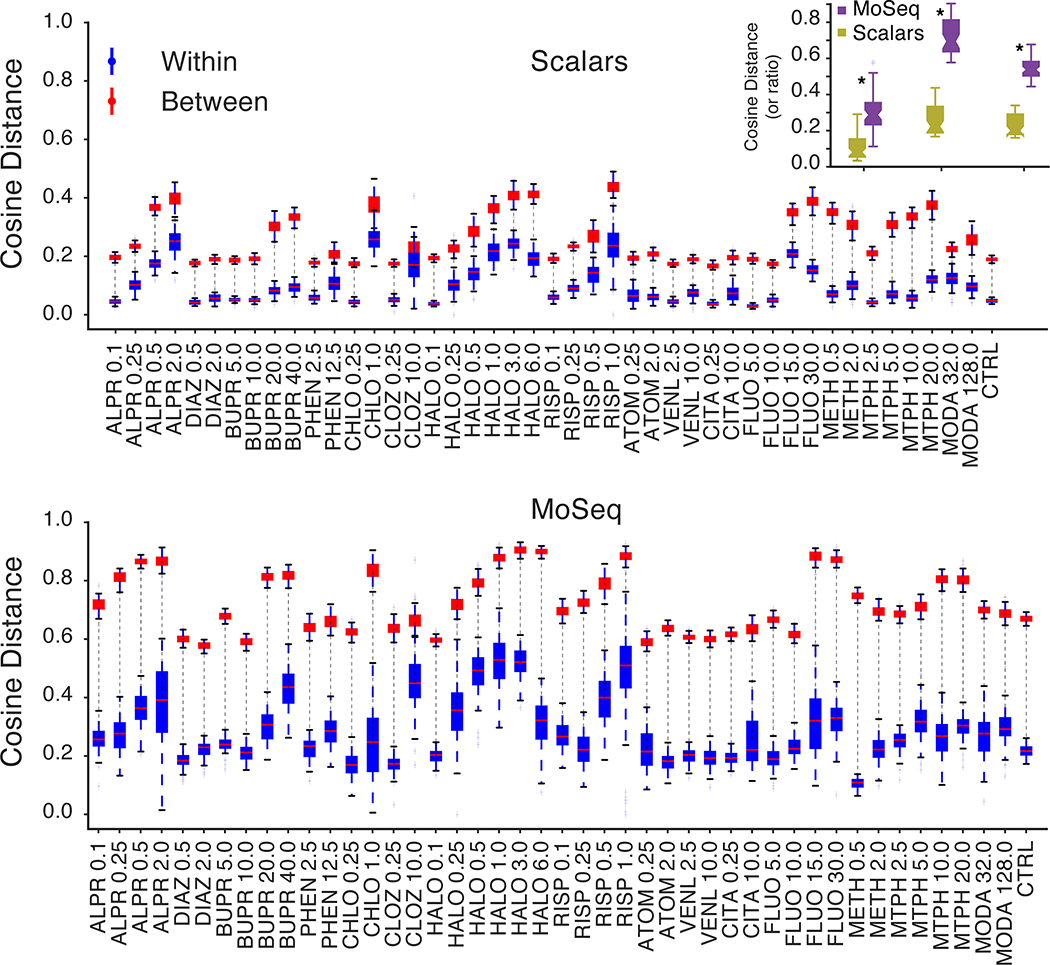
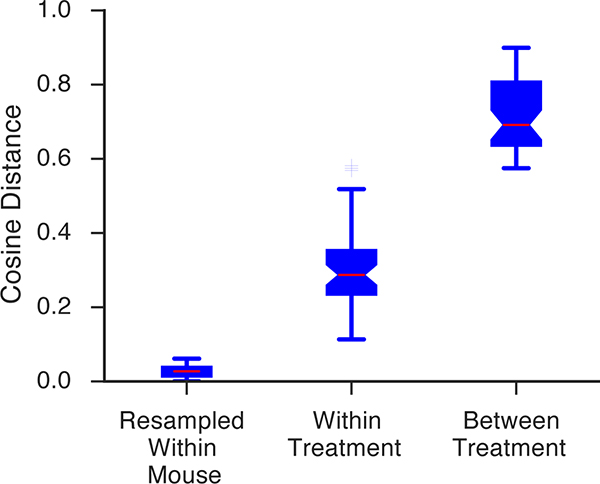
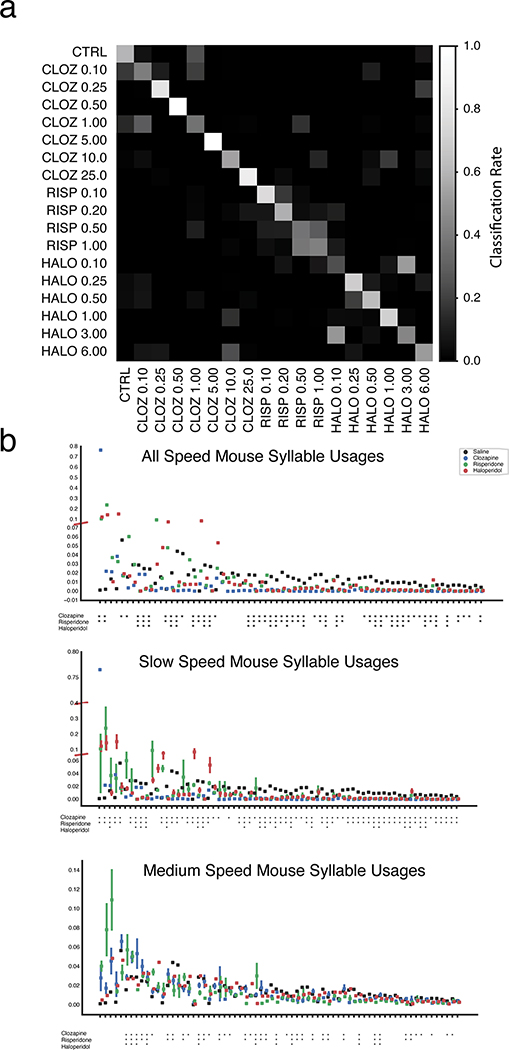
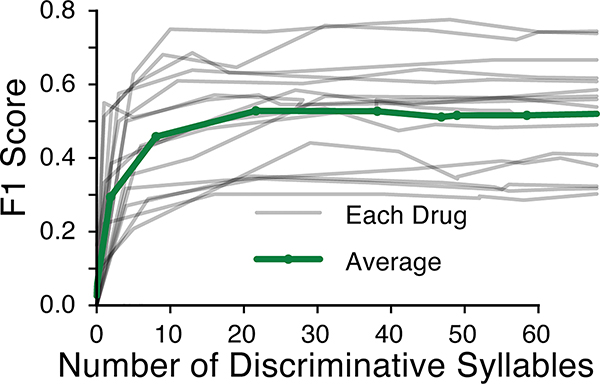
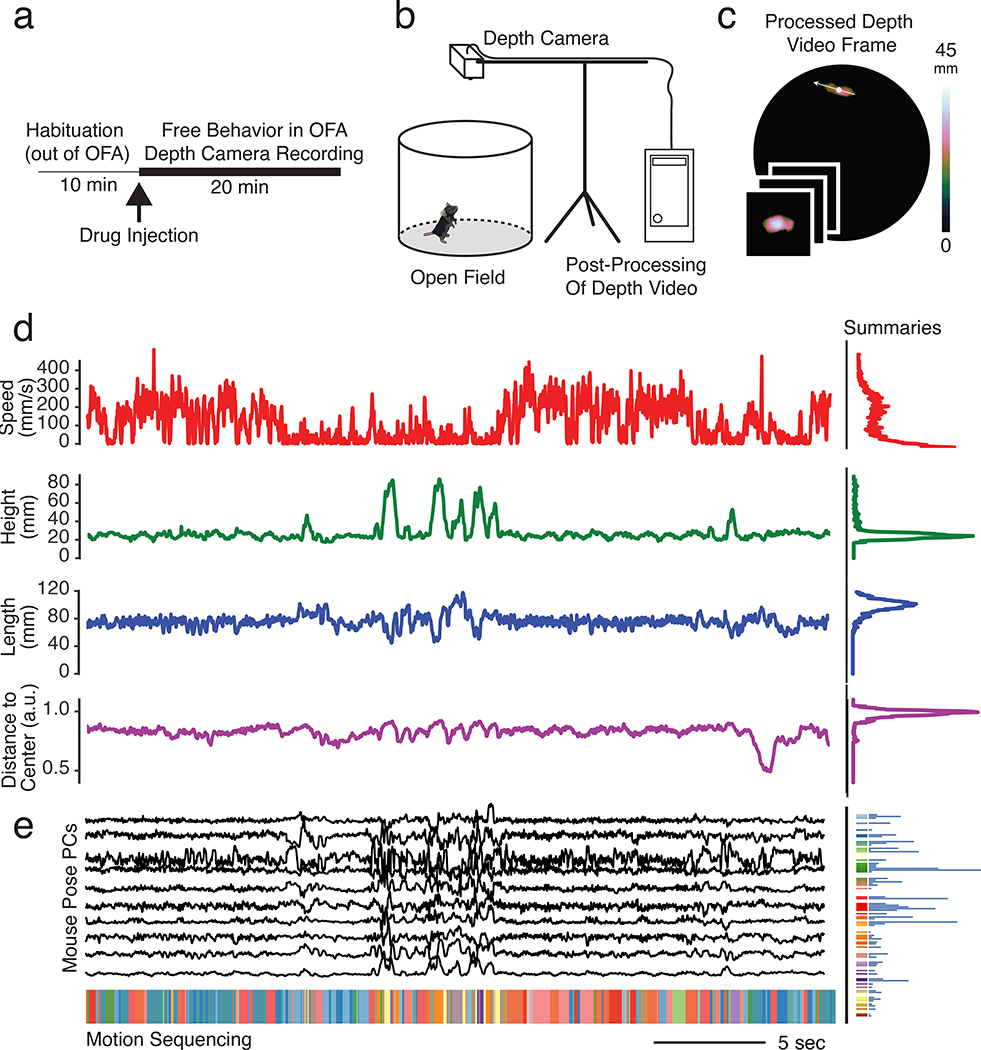
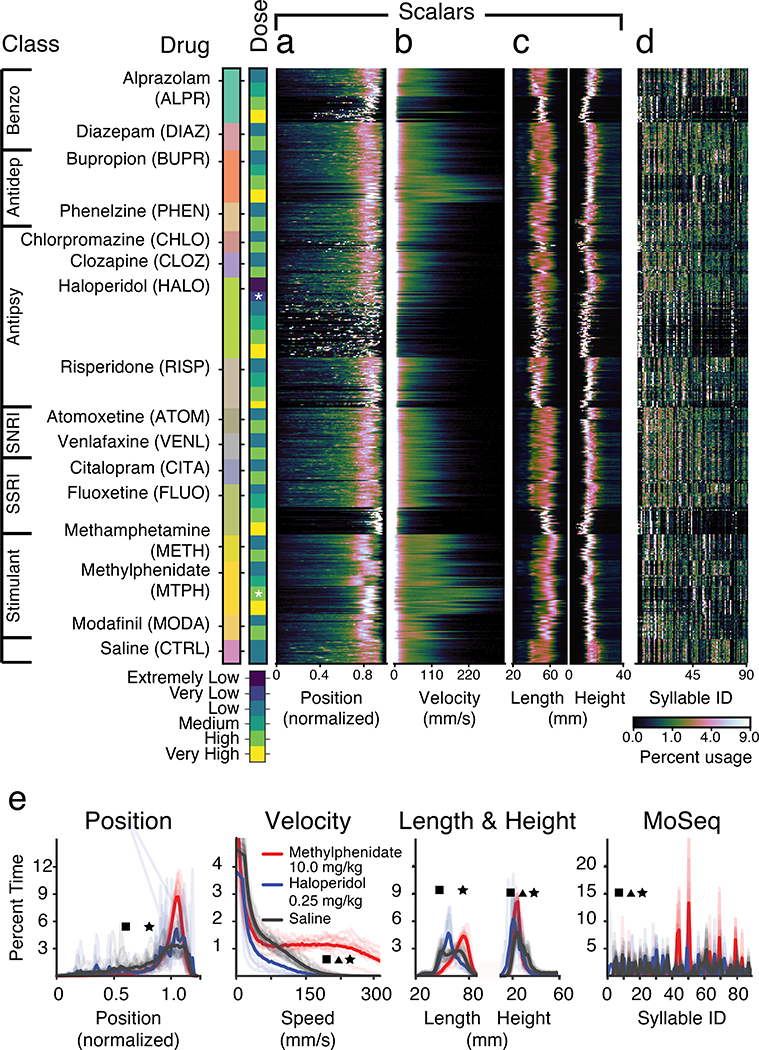
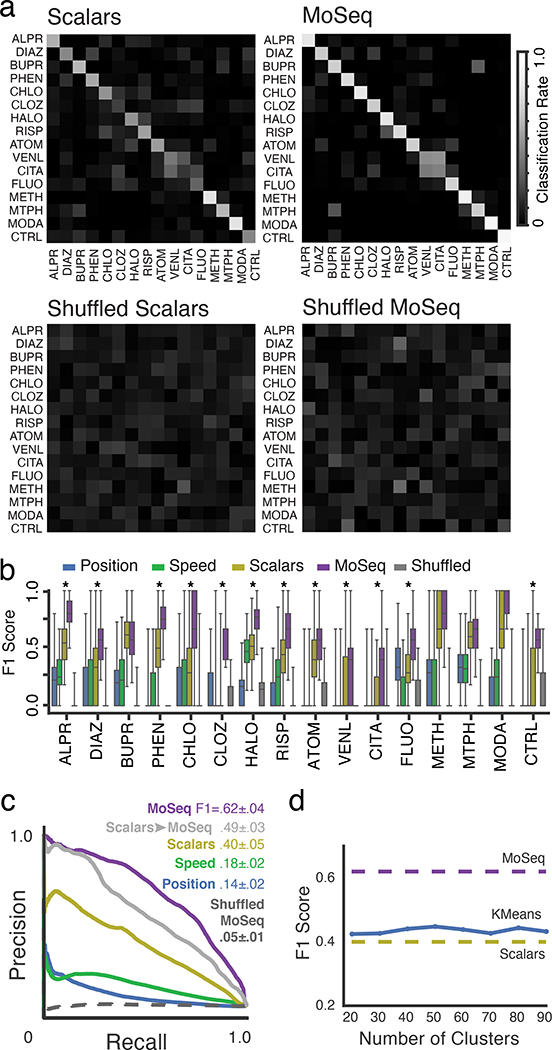
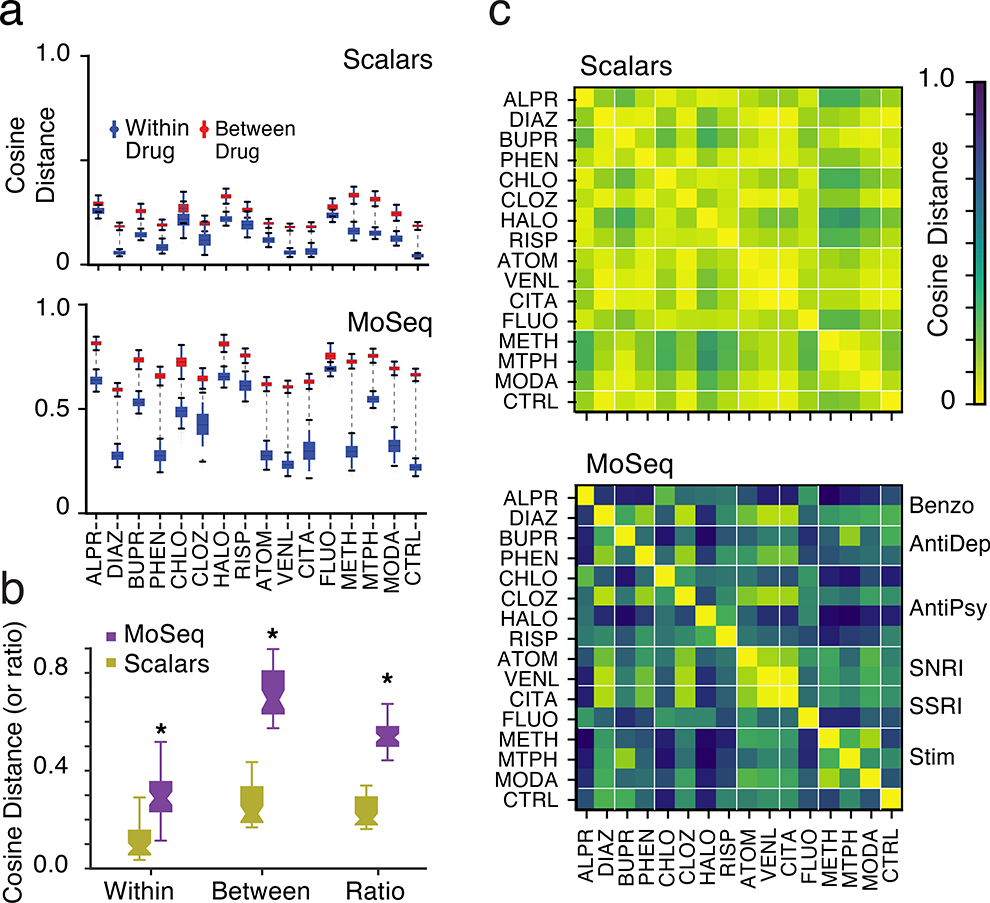
Comment in
-
Computational behavior analysis takes on drug development.Nat Neurosci. 2020 Nov;23(11):1314-1316. doi: 10.1038/s41593-020-00722-3. Nat Neurosci. 2020. PMID: 32999472 No abstract available.
Similar articles
-
Keypoint-MoSeq: parsing behavior by linking point tracking to pose dynamics.bioRxiv [Preprint]. 2023 Dec 23:2023.03.16.532307. doi: 10.1101/2023.03.16.532307. bioRxiv. 2023. Update in: Nat Methods. 2024 Jul;21(7):1329-1339. doi: 10.1038/s41592-024-02318-2. PMID: 36993589 Free PMC article. Updated. Preprint.
-
Keypoint-MoSeq: parsing behavior by linking point tracking to pose dynamics.Nat Methods. 2024 Jul;21(7):1329-1339. doi: 10.1038/s41592-024-02318-2. Epub 2024 Jul 12. Nat Methods. 2024. PMID: 38997595 Free PMC article.
-
Q&A: Understanding the composition of behavior.BMC Biol. 2019 May 29;17(1):44. doi: 10.1186/s12915-019-0663-3. BMC Biol. 2019. PMID: 31142307 Free PMC article.
-
Mouse Behavior Tracker: An economical method for tracking behavior in home cages.Biotechniques. 2017 Nov 1;63(5):215-220. doi: 10.2144/000114607. Biotechniques. 2017. PMID: 29185921 Free PMC article.
-
IntelliCage as a tool for measuring mouse behavior - 20 years perspective.Behav Brain Res. 2020 Jun 18;388:112620. doi: 10.1016/j.bbr.2020.112620. Epub 2020 Apr 14. Behav Brain Res. 2020. PMID: 32302617 Review.
Cited by
-
Mouse Exploratory Behaviour in the Open Field with and without NAT-1 EEG Device: Effects of MK801 and Scopolamine.Biomolecules. 2024 Aug 15;14(8):1008. doi: 10.3390/biom14081008. Biomolecules. 2024. PMID: 39199395 Free PMC article.
-
Assessing Cerebellar Disorders with Wearable Inertial Sensor Data Using Time-Frequency and Autoregressive Hidden Markov Model Approaches.Sensors (Basel). 2022 Dec 3;22(23):9454. doi: 10.3390/s22239454. Sensors (Basel). 2022. PMID: 36502155 Free PMC article.
-
MouseVenue3D: A Markerless Three-Dimension Behavioral Tracking System for Matching Two-Photon Brain Imaging in Free-Moving Mice.Neurosci Bull. 2022 Mar;38(3):303-317. doi: 10.1007/s12264-021-00778-6. Epub 2021 Oct 12. Neurosci Bull. 2022. PMID: 34637091 Free PMC article.
-
Brain circuits for pain and its treatment.Sci Transl Med. 2021 Nov 10;13(619):eabj7360. doi: 10.1126/scitranslmed.abj7360. Epub 2021 Nov 10. Sci Transl Med. 2021. PMID: 34757810 Free PMC article. Review.
-
Keypoint-MoSeq: parsing behavior by linking point tracking to pose dynamics.bioRxiv [Preprint]. 2023 Dec 23:2023.03.16.532307. doi: 10.1101/2023.03.16.532307. bioRxiv. 2023. Update in: Nat Methods. 2024 Jul;21(7):1329-1339. doi: 10.1038/s41592-024-02318-2. PMID: 36993589 Free PMC article. Updated. Preprint.
References
-
- Tinbergen N The study of instinct. (Clarendon Press, 1951).
-
- Dawkins R in Growing points in ethology. (Cambridge U Press, 1976).
Methods References
-
- Fukunaga K & Olsen DR An algorithm for finding intrinsic dimensionality of data. IEEE Transactions on Computers 20, 176–183, doi:(null) (1971).
-
- Bishop CM Pattern Recognition and Machine Learning. (Springer, 2006).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
