

A machine learning Automated Recommendation Tool for synthetic biology
- PMID: 32978379
- PMCID: PMC7519645
- DOI: 10.1038/s41467-020-18008-4
A machine learning Automated Recommendation Tool for synthetic biology
Abstract
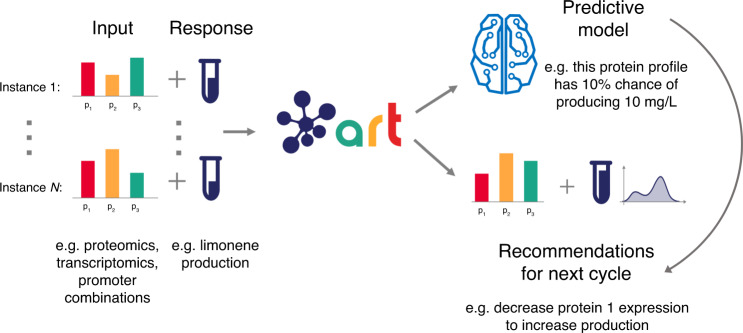
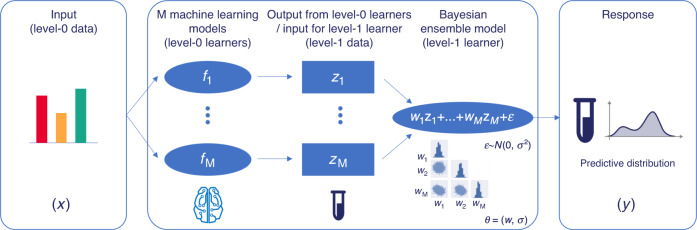
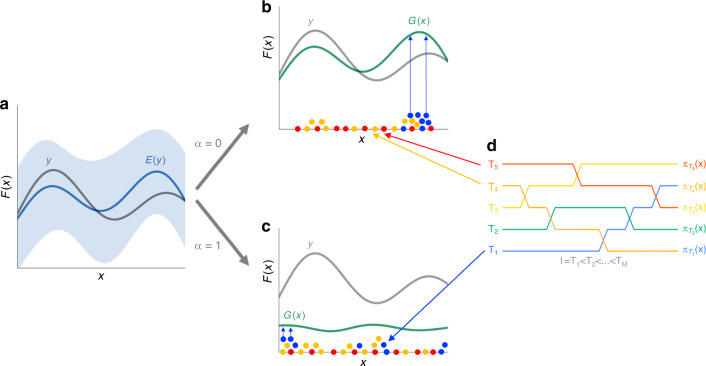
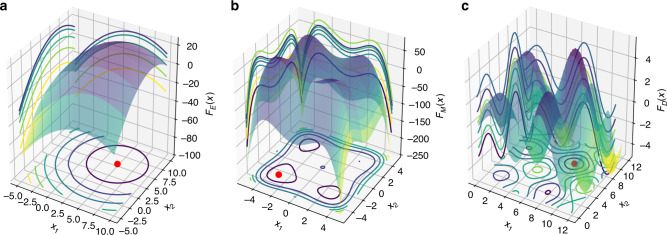
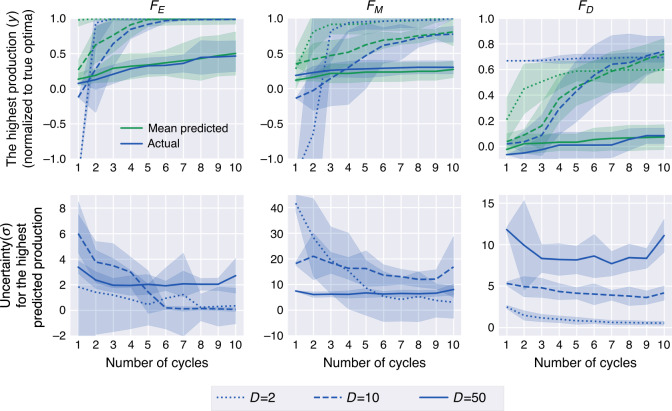
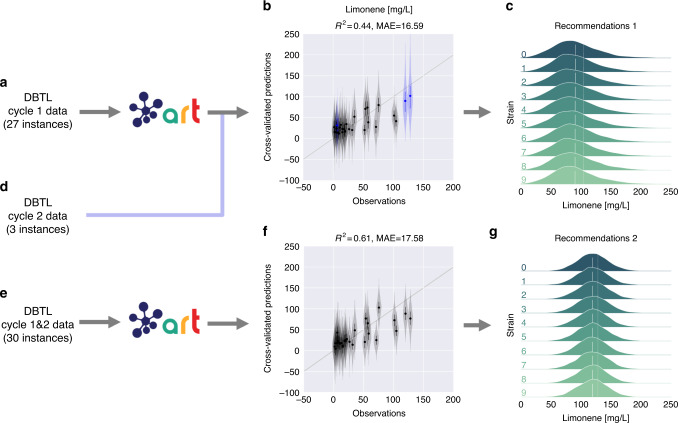
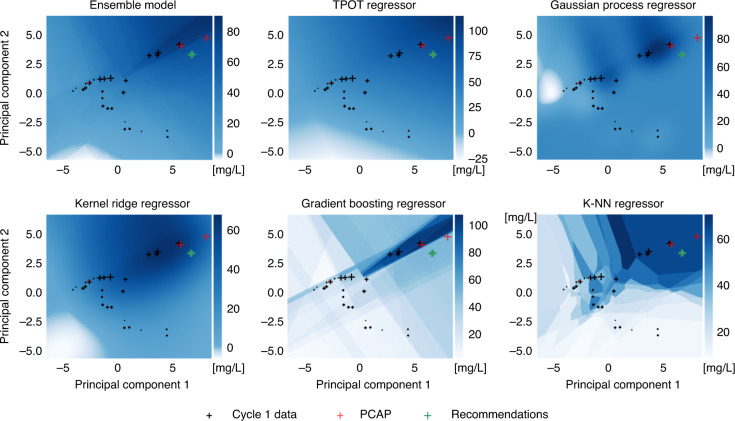
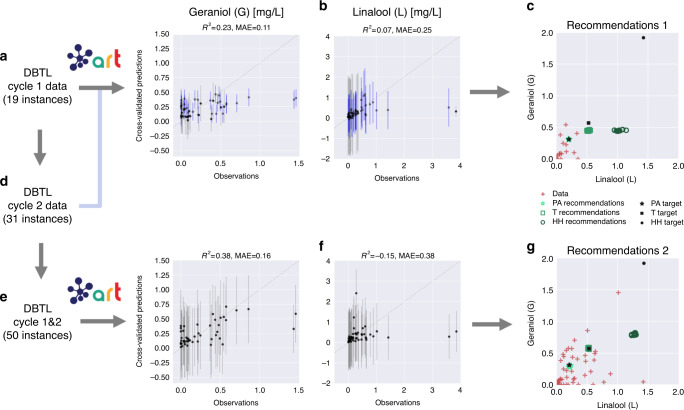
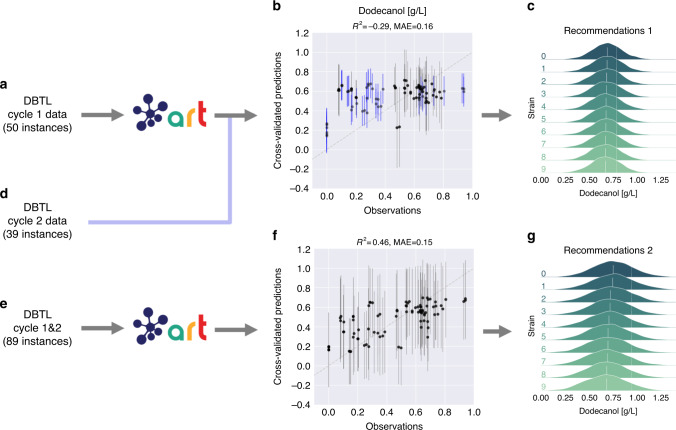
Synthetic biology allows us to bioengineer cells to synthesize novel valuable molecules such as renewable biofuels or anticancer drugs. However, traditional synthetic biology approaches involve ad-hoc engineering practices, which lead to long development times. Here, we present the Automated Recommendation Tool (ART), a tool that leverages machine learning and probabilistic modeling techniques to guide synthetic biology in a systematic fashion, without the need for a full mechanistic understanding of the biological system. Using sampling-based optimization, ART provides a set of recommended strains to be built in the next engineering cycle, alongside probabilistic predictions of their production levels. We demonstrate the capabilities of ART on simulated data sets, as well as experimental data from real metabolic engineering projects producing renewable biofuels, hoppy flavored beer without hops, fatty acids, and tryptophan. Finally, we discuss the limitations of this approach, and the practical consequences of the underlying assumptions failing.
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Stephanopoulos G. Metabolic fluxes and metabolic engineering. Metab. Eng. 1999;1:1–11. - PubMed
-
- Beller HR, Lee TS, Katz L. Natural products as biofuels and bio-based chemicals: fatty acids and isoprenoids. Nat. Prod. Rep. 2015;32:1508–1526. - PubMed
-
- Cann, O. These are the top 10 emerging technologies of 2016. World Economic Forum website https://www.weforum.org/agenda/2016/06/top-10-emerging-technologies-2016 (2016).
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
