

Deep Reinforcement Learning for Indoor Mobile Robot Path Planning
- PMID: 32992750
- PMCID: PMC7582363
- DOI: 10.3390/s20195493
Deep Reinforcement Learning for Indoor Mobile Robot Path Planning
Abstract
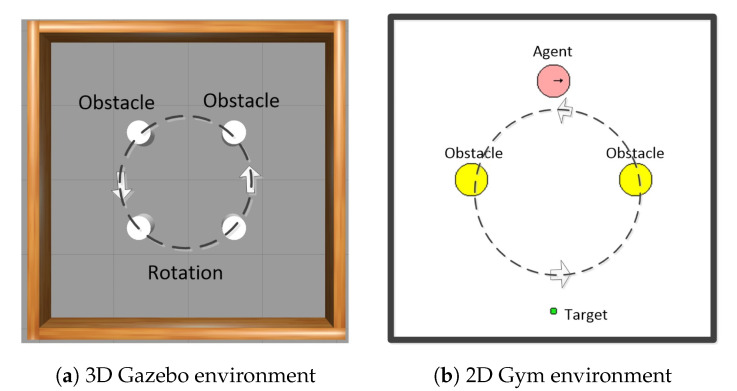
This paper proposes a novel incremental training mode to address the problem of Deep Reinforcement Learning (DRL) based path planning for a mobile robot. Firstly, we evaluate the related graphic search algorithms and Reinforcement Learning (RL) algorithms in a lightweight 2D environment. Then, we design the algorithm based on DRL, including observation states, reward function, network structure as well as parameters optimization, in a 2D environment to circumvent the time-consuming works for a 3D environment. We transfer the designed algorithm to a simple 3D environment for retraining to obtain the converged network parameters, including the weights and biases of deep neural network (DNN), etc. Using these parameters as initial values, we continue to train the model in a complex 3D environment. To improve the generalization of the model in different scenes, we propose to combine the DRL algorithm Twin Delayed Deep Deterministic policy gradients (TD3) with the traditional global path planning algorithm Probabilistic Roadmap (PRM) as a novel path planner (PRM+TD3). Experimental results show that the incremental training mode can notably improve the development efficiency. Moreover, the PRM+TD3 path planner can effectively improve the generalization of the model.
Keywords: deep neural network; deep reinforcement learning; generalization; incremental training mode; mobile robot; path planning; reward function.
Conflict of interest statement
The authors declare no conflict of interest.
Figures










References
-
- Zhang L., Chen Z., Cui W., Li B., Chen C.Y., Cao Z., Gao K. WiFi-Based Indoor Robot Positioning Using Deep Fuzzy Forests. IEEE Internet Things J. 2020 doi: 10.1109/JIOT.2020.2986685. - DOI
-
- Dissanayake G., Huang S., Wang Z., Ranasinghe R. A review of recent developments in Simultaneous Localization and Mapping; Proceedings of the 2011 6th International Conference on Industrial and Information Systems; Kandy, Sri Lanka. 16–19 August 2011; pp. 477–482.
-
- Zhang L., Zapata R., Lépinay P. Self-adaptive Monte Carlo localization for mobile robots using range finders. Robotica. 2012;30:229–244. doi: 10.1017/S0263574711000567. - DOI
-
- Chen W., Liao T., Li Z., Lin H., Xue H., Zhang L., Guo J., Cao Z. Using FTOC to track shuttlecock for the badminton robot. Neurocomputing. 2019;334:182–196. doi: 10.1016/j.neucom.2019.01.023. - DOI
-
- Cao Z., Liao T., Song W., Chen Z., Li C. Detecting the shuttlecock for a badminton robot: A YOLO based approach. Expert Syst. Appl. 2020;164:113833. doi: 10.1016/j.eswa.2020.113833. - DOI
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
