

A data-driven methodology to discover similarities between cocaine samples
- PMID: 32994485
- PMCID: PMC7525495
- DOI: 10.1038/s41598-020-72652-w
A data-driven methodology to discover similarities between cocaine samples
Abstract
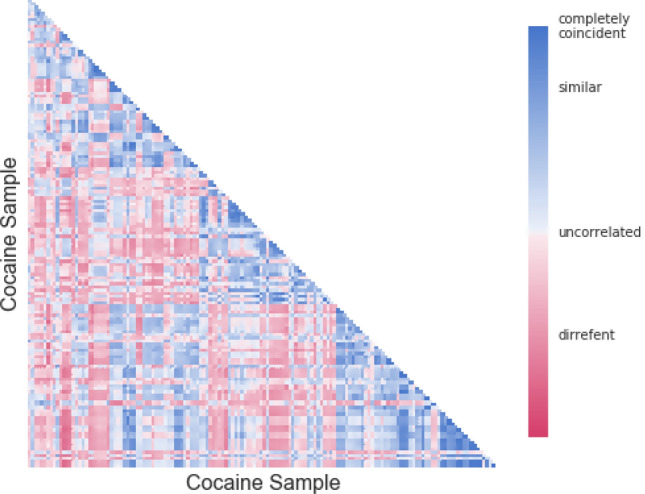
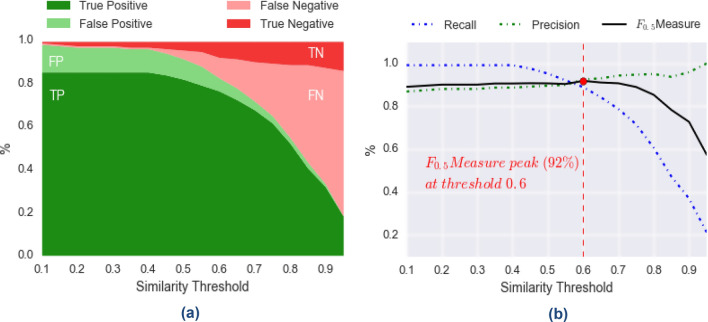
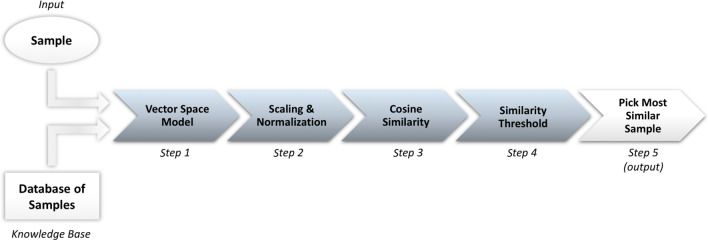
Machine learning has been used for distinct purposes in the science field but no applications on illegal drug have been done before. This study proposes a new web-based system for cocaine classification, profiling relations and comparison, that is capable of producing meaningful output based on a large amount of chemical profiling's data. In particular, the Profiling Relations In Drug trafficking in Europe (PRIDE) system, offers several advantages to intelligence actions across Europe. Thus, it provides a standardized, broad methodology which uses machine learning algorithms to classify and compare drug profiles, highlight how similar drug samples are, and how probable it is that they share a common origin, batch, or preparation process. We evaluated the proposed algorithms using precision and recall metrics and analyzed the quality of predictions performed by the algorithms, with respect to our gold standard. In our experiments, we reached a value of 88% for F0.5-measure, 91% for precision, and 78% for recall, confirming our main hypothesis: machine learning can learn and be applied to have an automatic classification of cocaine profiles.
Conflict of interest statement
The authors declare no competing interests.
Figures


References
-
- United Nations Office on Drugs and Crime. Recommended methods for the Identification and Analysis of Cocaine in Seized Materials Manual for use by national drug analysis laboratories. United Nations. New York. https://www.unodc.org/documents/scientific/Cocaine_Manual_Rev_1.pdf (2012).
Publication types
LinkOut - more resources
Full Text Sources
