

Robust parallel decision-making in neural circuits with nonlinear inhibition
- PMID: 33008882
- PMCID: PMC7568288
- DOI: 10.1073/pnas.1917551117
Robust parallel decision-making in neural circuits with nonlinear inhibition
Abstract
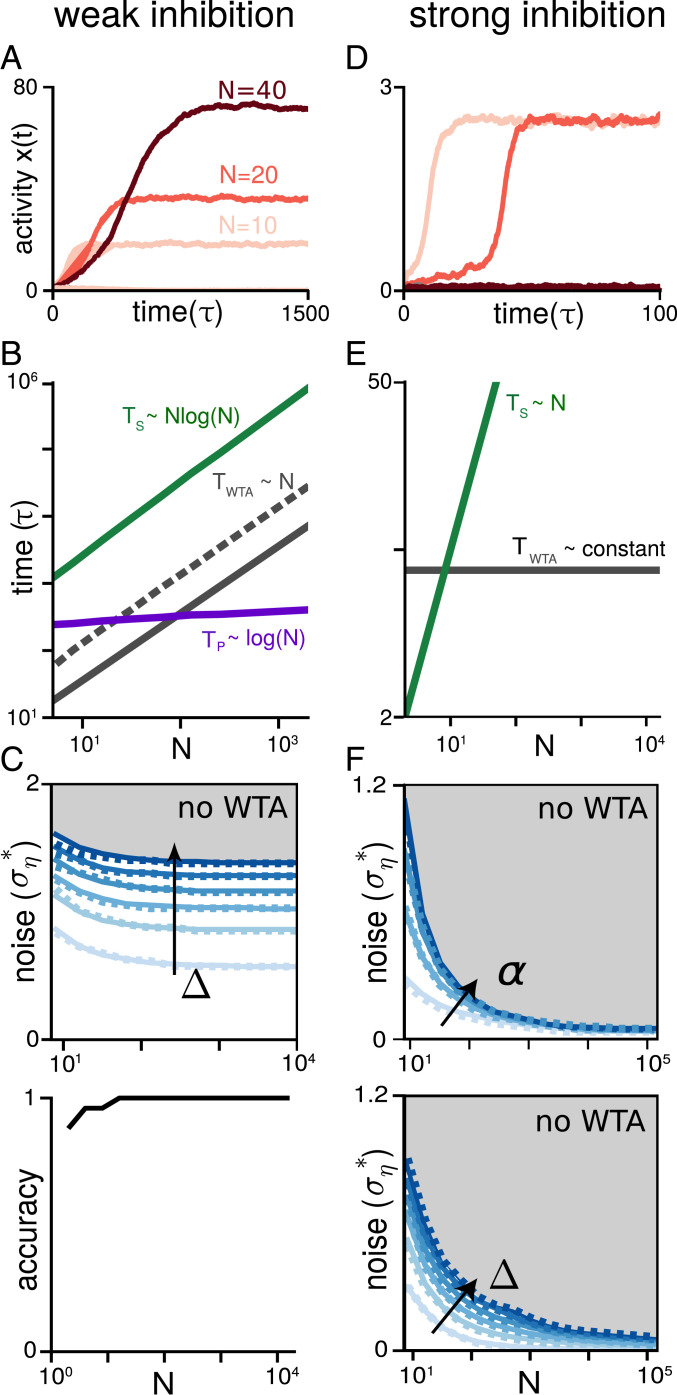
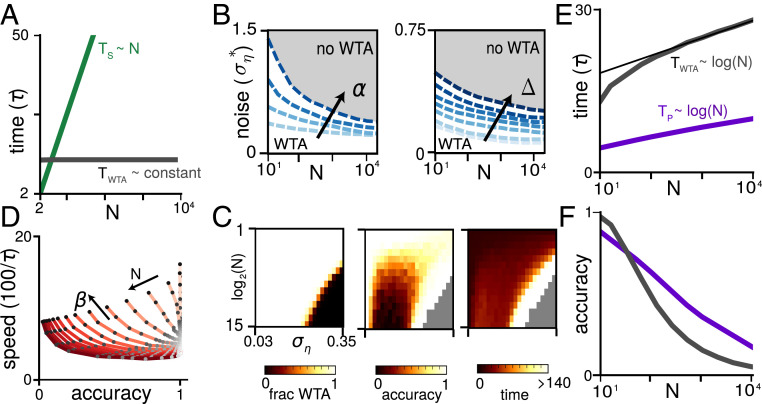
An elemental computation in the brain is to identify the best in a set of options and report its value. It is required for inference, decision-making, optimization, action selection, consensus, and foraging. Neural computing is considered powerful because of its parallelism; however, it is unclear whether neurons can perform this max-finding operation in a way that improves upon the prohibitively slow optimal serial max-finding computation (which takes [Formula: see text] time for N noisy candidate options) by a factor of N, the benchmark for parallel computation. Biologically plausible architectures for this task are winner-take-all (WTA) networks, where individual neurons inhibit each other so only those with the largest input remain active. We show that conventional WTA networks fail the parallelism benchmark and, worse, in the presence of noise, altogether fail to produce a winner when N is large. We introduce the nWTA network, in which neurons are equipped with a second nonlinearity that prevents weakly active neurons from contributing inhibition. Without parameter fine-tuning or rescaling as N varies, the nWTA network achieves the parallelism benchmark. The network reproduces experimentally observed phenomena like Hick's law without needing an additional readout stage or adaptive N-dependent thresholds. Our work bridges scales by linking cellular nonlinearities to circuit-level decision-making, establishes that distributed computation saturating the parallelism benchmark is possible in networks of noisy, finite-memory neurons, and shows that Hick's law may be a symptom of near-optimal parallel decision-making with noisy input.
Keywords: neural circuits; noisy computation; optimal decision-making; speed–accuracy trade-off.
Copyright © 2020 the Author(s). Published by PNAS.
Conflict of interest statement
The authors declare no competing interest.
Figures



References
-
- Gold J. I., Shadlen M. N., The neural basis of decision making. Annu. Rev. Neurosci. 30, 535–574 (2007). - PubMed
-
- Bogacz R., Gurney K., The basal ganglia and cortex implement optimal decision making between alternative actions. Neural Comput. 19, 442–477 (2007). - PubMed
-
- Chittka L., Skorupski P., Raine N. E., Speed–accuracy tradeoffs in animal decision making. Trends Ecol. Evol. 24, 400–407 (2009). - PubMed
