

High-dimensional dynamics of generalization error in neural networks
- PMID: 33022471
- PMCID: PMC7685244
- DOI: 10.1016/j.neunet.2020.08.022
High-dimensional dynamics of generalization error in neural networks
Abstract
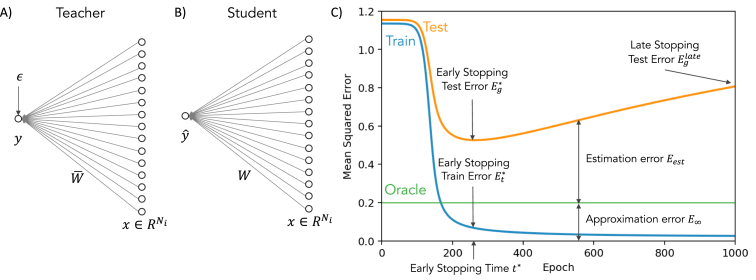
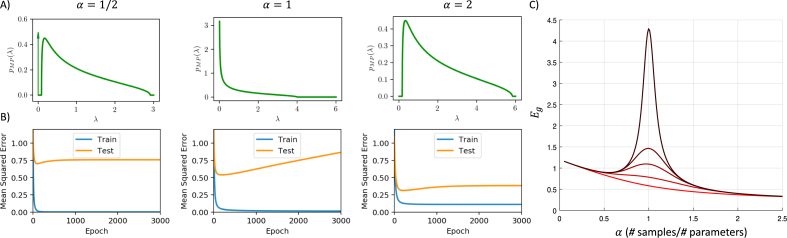
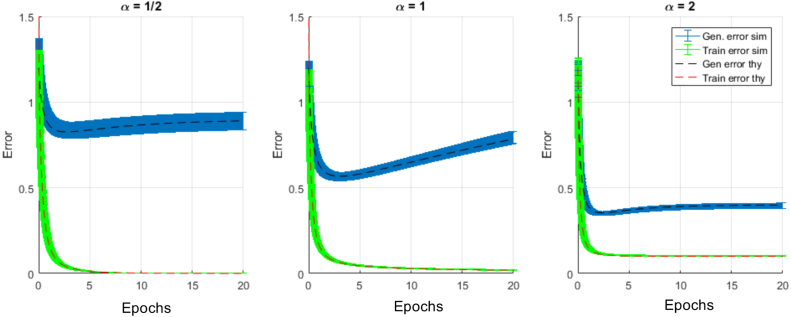
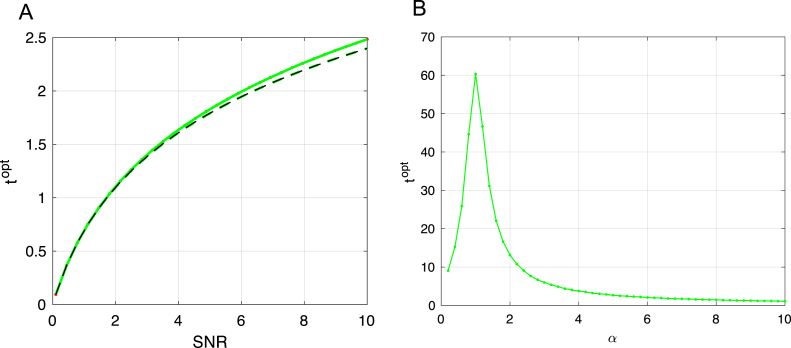
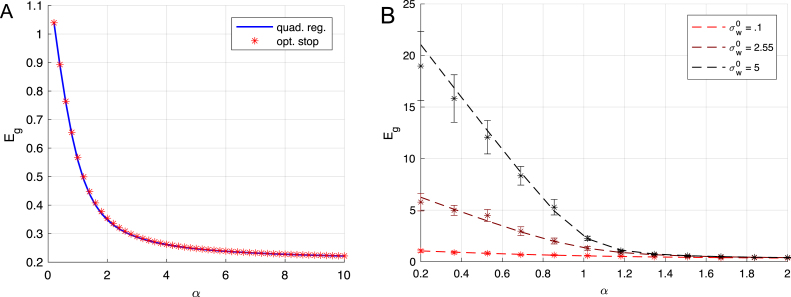
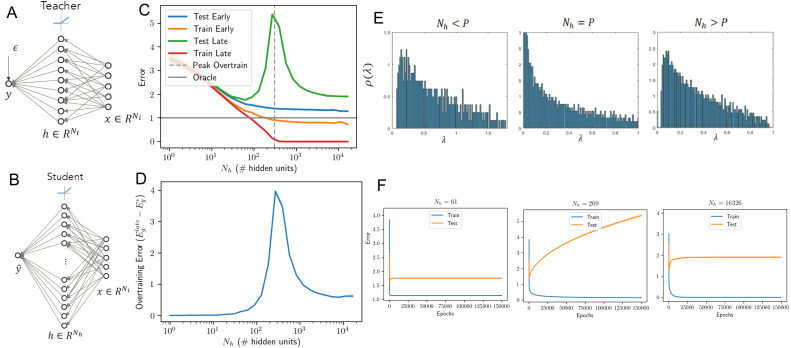
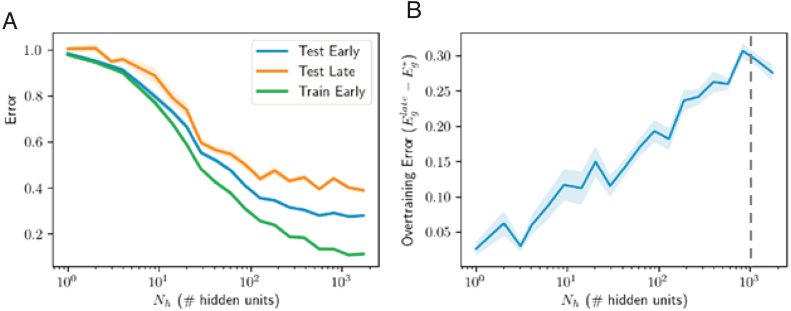
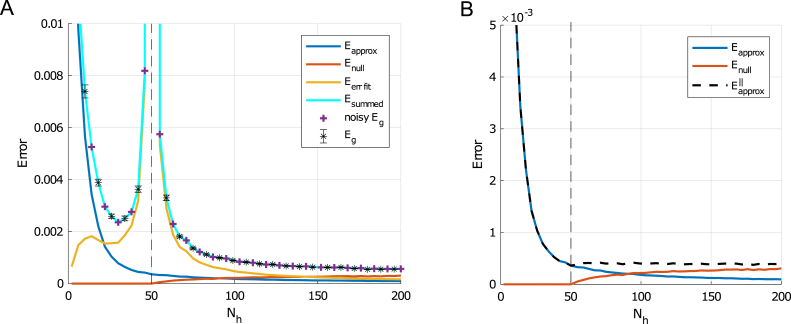
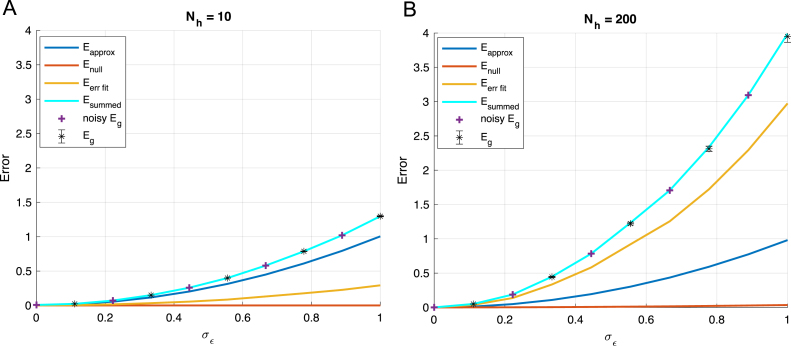
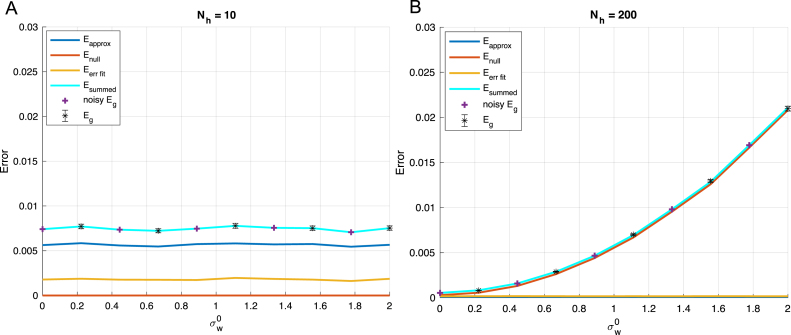
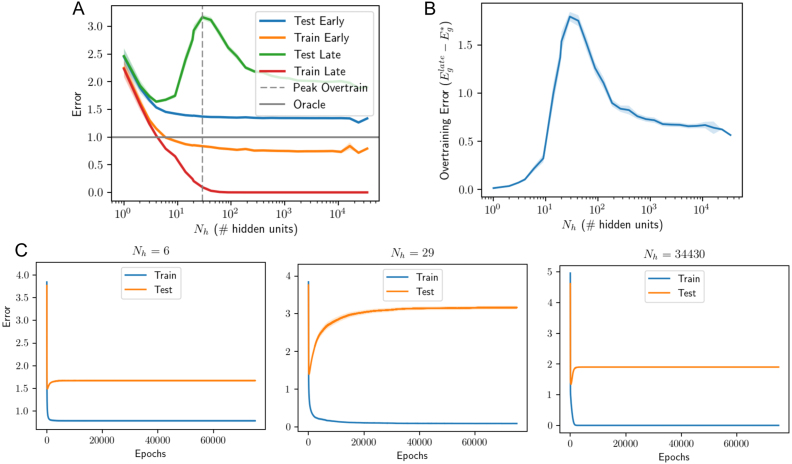
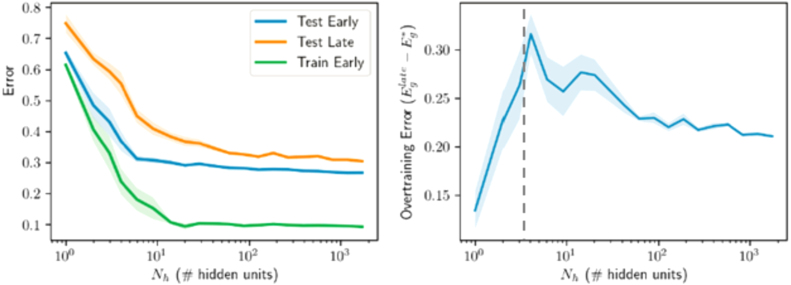
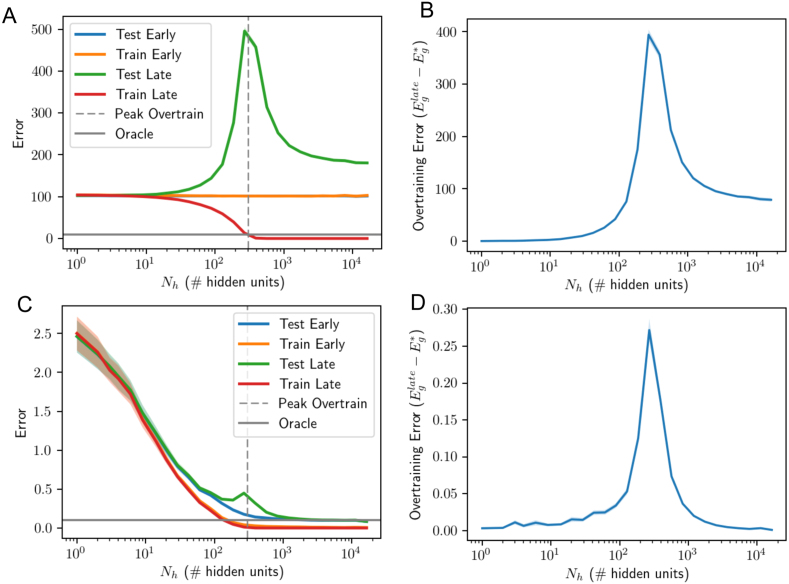
We perform an analysis of the average generalization dynamics of large neural networks trained using gradient descent. We study the practically-relevant "high-dimensional" regime where the number of free parameters in the network is on the order of or even larger than the number of examples in the dataset. Using random matrix theory and exact solutions in linear models, we derive the generalization error and training error dynamics of learning and analyze how they depend on the dimensionality of data and signal to noise ratio of the learning problem. We find that the dynamics of gradient descent learning naturally protect against overtraining and overfitting in large networks. Overtraining is worst at intermediate network sizes, when the effective number of free parameters equals the number of samples, and thus can be reduced by making a network smaller or larger. Additionally, in the high-dimensional regime, low generalization error requires starting with small initial weights. We then turn to non-linear neural networks, and show that making networks very large does not harm their generalization performance. On the contrary, it can in fact reduce overtraining, even without early stopping or regularization of any sort. We identify two novel phenomena underlying this behavior in overcomplete models: first, there is a frozen subspace of the weights in which no learning occurs under gradient descent; and second, the statistical properties of the high-dimensional regime yield better-conditioned input correlations which protect against overtraining. We demonstrate that standard application of theories such as Rademacher complexity are inaccurate in predicting the generalization performance of deep neural networks, and derive an alternative bound which incorporates the frozen subspace and conditioning effects and qualitatively matches the behavior observed in simulation.
Keywords: Generalization error; Neural networks; Random matrix theory.
Copyright © 2020 The Authors. Published by Elsevier Ltd.. All rights reserved.
Conflict of interest statement
Declaration of Competing Interest The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures

References
-
- Advani M., Ganguli S. An equivalence between high dimensional bayes optimal inference and m-estimation. Advances in Neural Information Processing Systems. 2016
-
- Advani M., Ganguli S. 2016. Statistical mechanics of high dimensional inference supplementary material. In: See https://ganguli-gang.stanford.edu/pdf/HighDimInf.Supp.pdf.
-
- Advani M., Ganguli S. Statistical mechanics of optimal convex inference in high dimensions. Physical Review X. 2016;6(3)
-
- Advani M., Lahiri S., Ganguli S. Statistical mechanics of complex neural systems and high dimensional data. Journal of Statistical Mechanics: Theory and Experiment. 2013;(03):P03014.
-
- Amari S., Murata N., Müller K.R. Statistical theory of overtraining - Is cross-validation asymptotically effective? Advances in Neural Information Processing Systems. 1996
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
