

This is a preprint.
SARS-CoV-2 gene content and COVID-19 mutation impact by comparing 44 Sarbecovirus genomes
- PMID: 33024961
- PMCID: PMC7536840
- DOI: 10.21203/rs.3.rs-80345/v1
SARS-CoV-2 gene content and COVID-19 mutation impact by comparing 44 Sarbecovirus genomes
Update in
-
SARS-CoV-2 gene content and COVID-19 mutation impact by comparing 44 Sarbecovirus genomes.Nat Commun. 2021 May 11;12(1):2642. doi: 10.1038/s41467-021-22905-7. Nat Commun. 2021. PMID: 33976134 Free PMC article.
Abstract
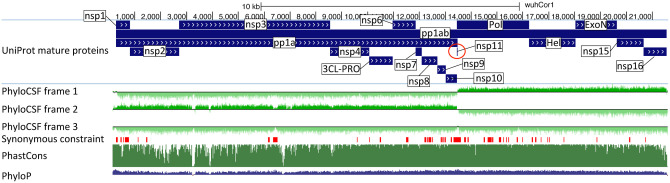
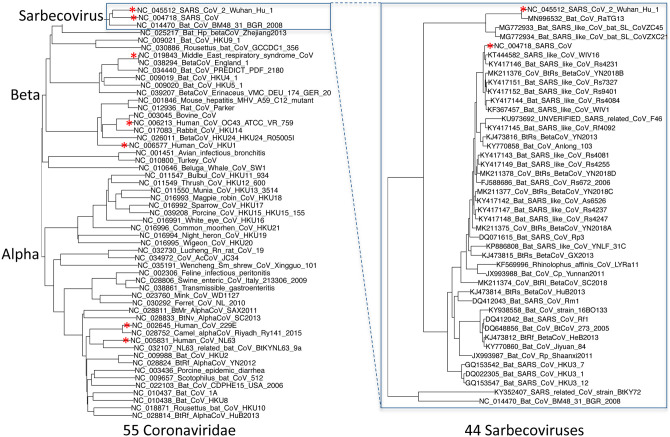
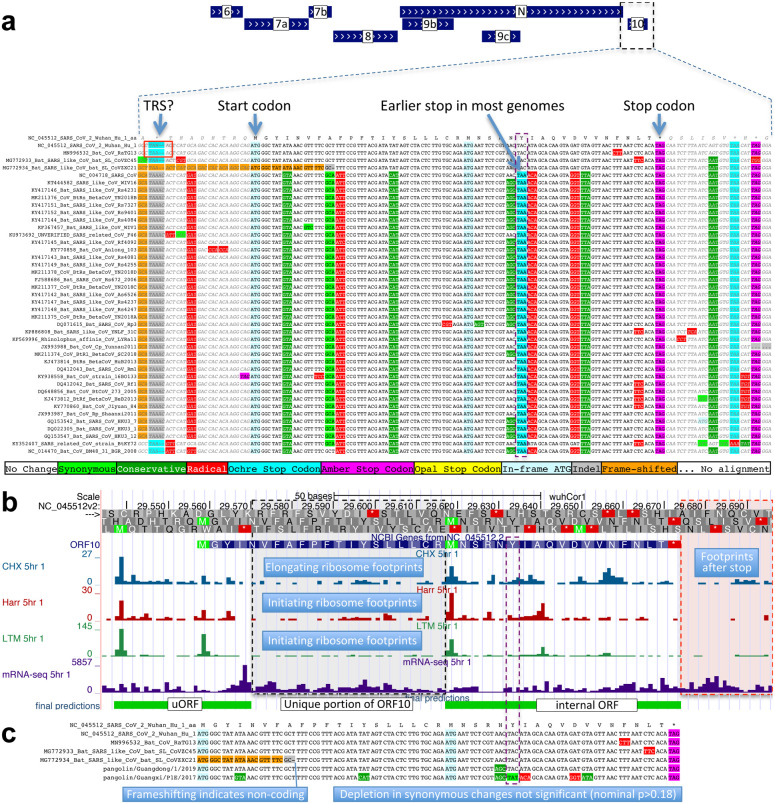
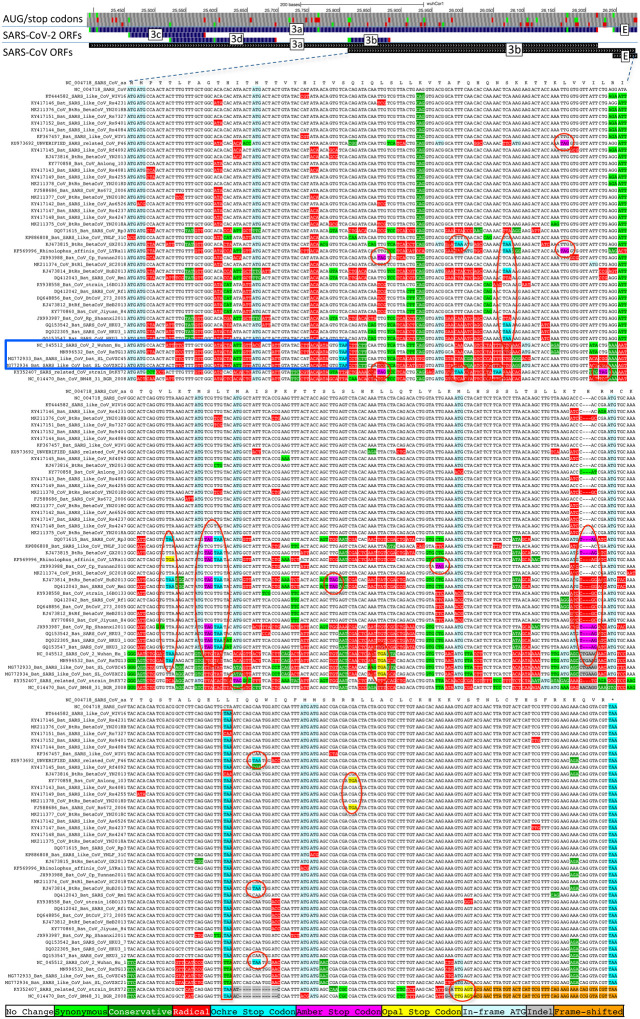
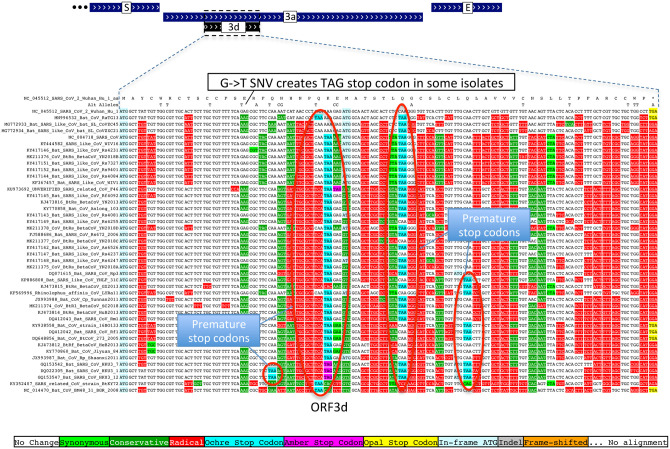
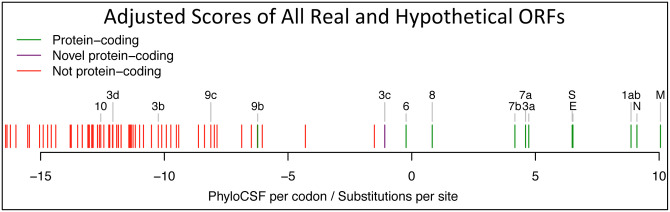
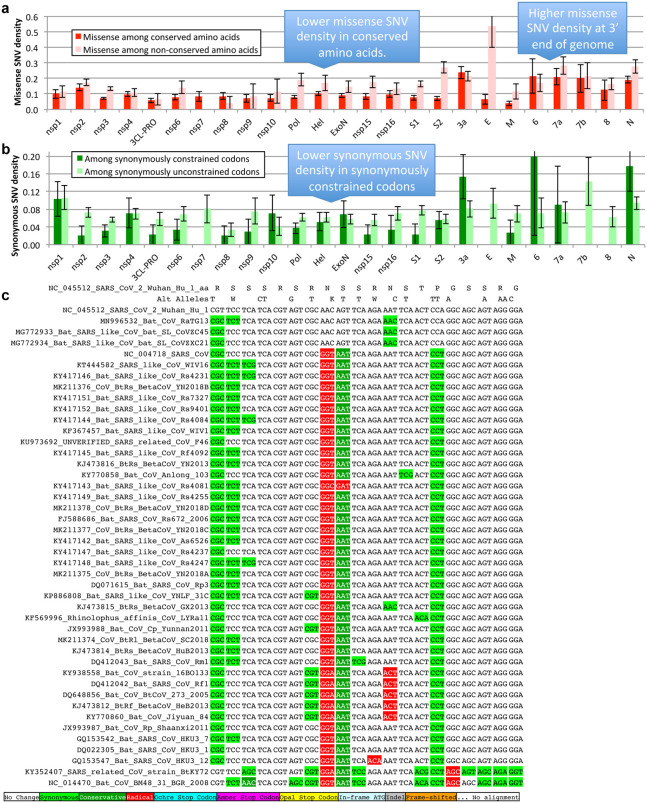
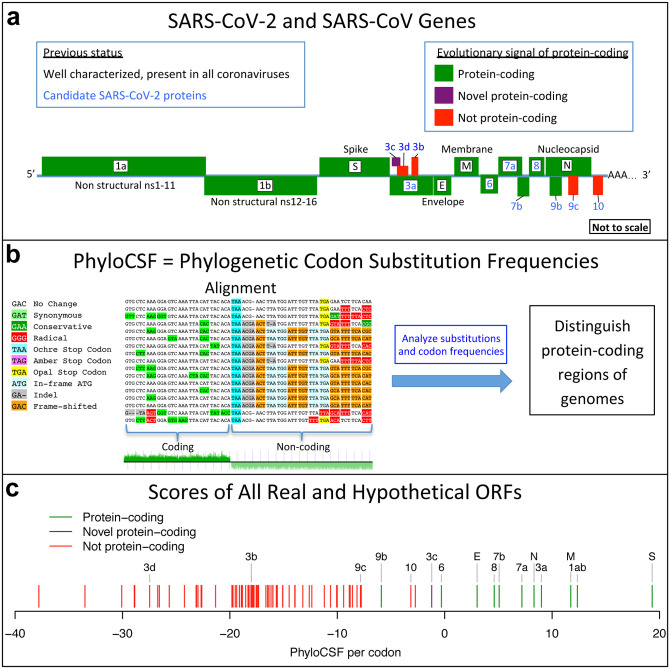
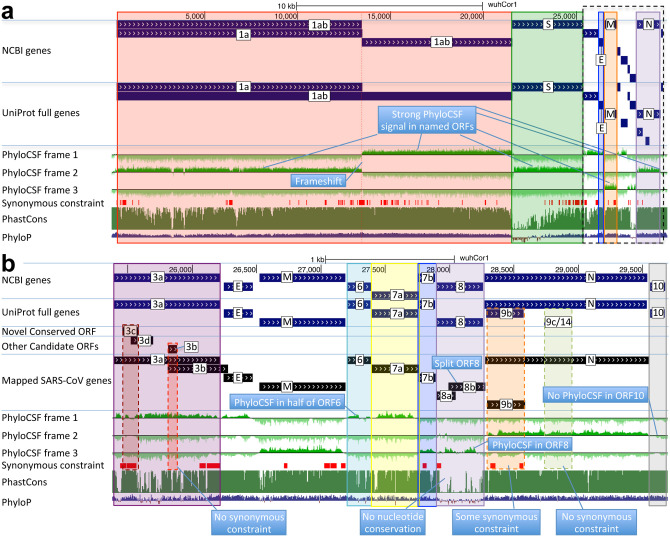
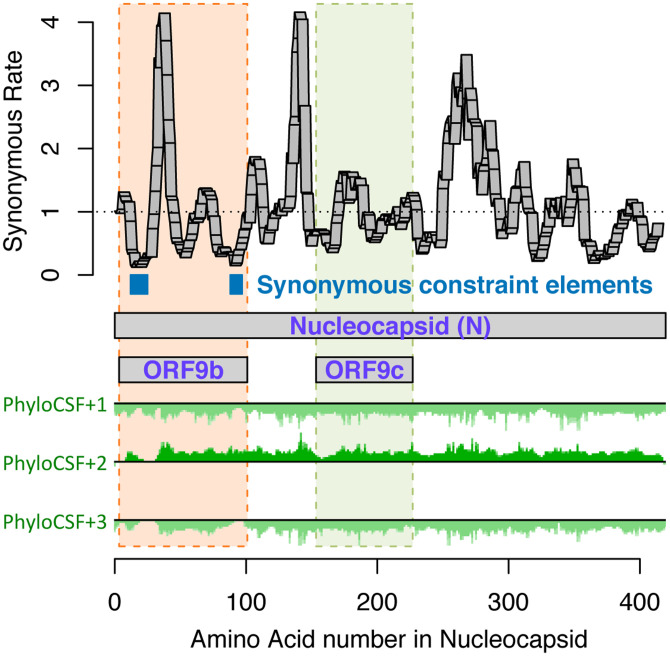
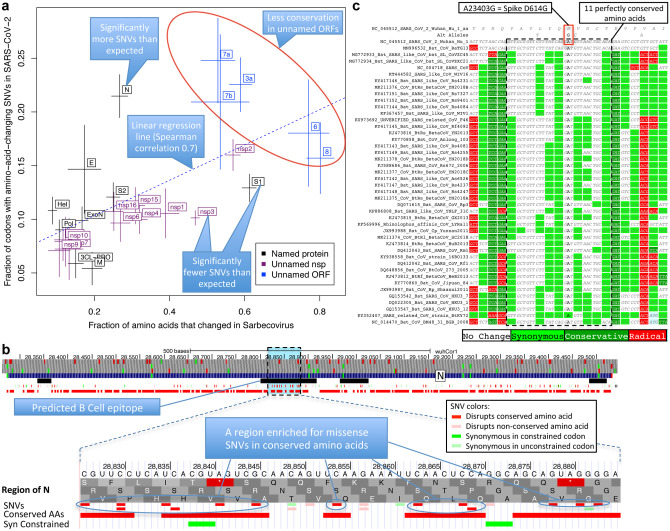
Despite its overwhelming clinical importance, the SARS-CoV-2 gene set remains unresolved, hindering dissection of COVID-19 biology. Here, we use comparative genomics to provide a high-confidence protein-coding gene set, characterize protein-level and nucleotide-level evolutionary constraint, and prioritize functional mutations from the ongoing COVID-19 pandemic. We select 44 complete Sarbecovirus genomes at evolutionary distances ideally-suited for protein-coding and non-coding element identification, create whole-genome alignments, and quantify protein-coding evolutionary signatures and overlapping constraint. We find strong protein-coding signatures for all named genes and for 3a, 6, 7a, 7b, 8, 9b, and also ORF3c, a novel alternate-frame gene. By contrast, ORF10, and overlapping-ORFs 9c, 3b, and 3d lack protein-coding signatures or convincing experimental evidence and are not protein-coding. Furthermore, we show no other protein-coding genes remain to be discovered. Cross-strain and within-strain evolutionary pressures largely agree at the gene, amino-acid, and nucleotide levels, with some notable exceptions, including fewer-than-expected mutations in nsp3 and Spike subunit S1, and more-than-expected mutations in Nucleocapsid. The latter also shows a cluster of amino-acid-changing variants in otherwise-conserved residues in a predicted B-cell epitope, which may indicate positive selection for immune avoidance. Several Spike-protein mutations, including D614G, which has been associated with increased transmission, disrupt otherwise-perfectly-conserved amino acids, and could be novel adaptations to human hosts. The resulting high-confidence gene set and evolutionary-history annotations provide valuable resources and insights on COVID-19 biology, mutations, and evolution.
Conflict of interest statement
Competing interest declaration
The authors declare no competing interests.
Figures



References
-
- Miller W. A. & Koev G. Synthesis of subgenomic RNAs by positive-strand RNA viruses. Virology 273, 1–8 (2000). - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
