

Democratizing EHR analyses with FIDDLE: a flexible data-driven preprocessing pipeline for structured clinical data
- PMID: 33040151
- PMCID: PMC7727385
- DOI: 10.1093/jamia/ocaa139
Democratizing EHR analyses with FIDDLE: a flexible data-driven preprocessing pipeline for structured clinical data
Abstract
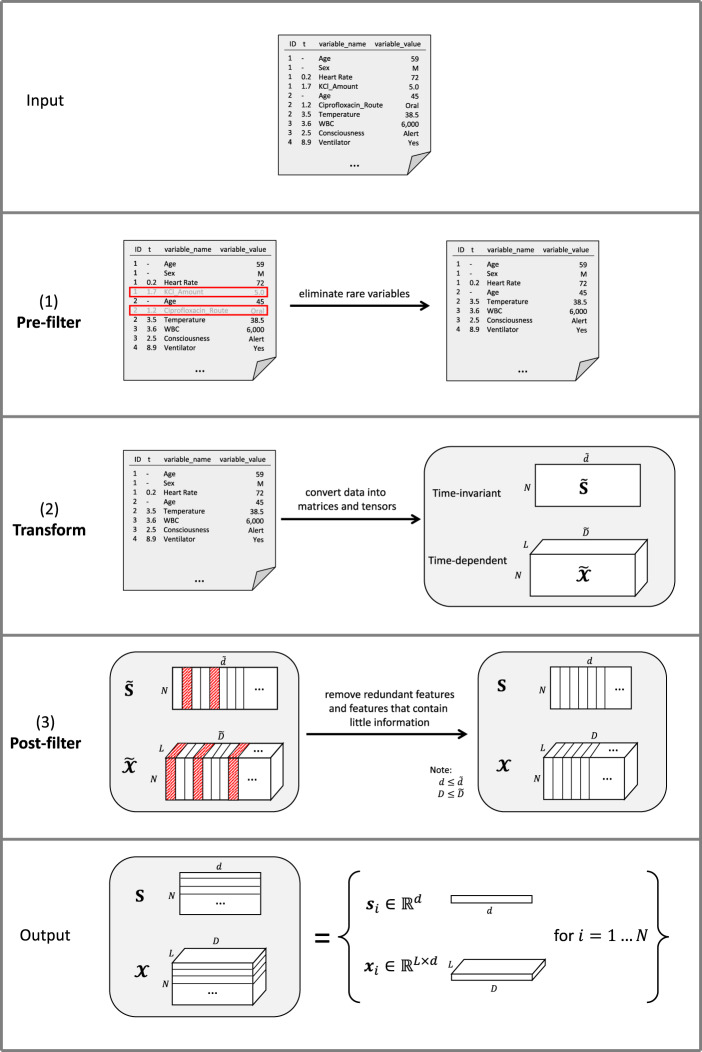
Objective: In applying machine learning (ML) to electronic health record (EHR) data, many decisions must be made before any ML is applied; such preprocessing requires substantial effort and can be labor-intensive. As the role of ML in health care grows, there is an increasing need for systematic and reproducible preprocessing techniques for EHR data. Thus, we developed FIDDLE (Flexible Data-Driven Pipeline), an open-source framework that streamlines the preprocessing of data extracted from the EHR.
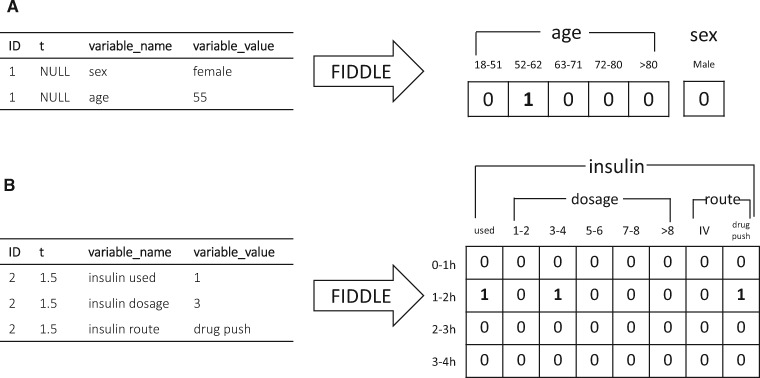
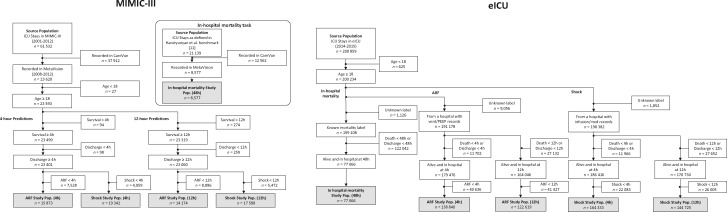
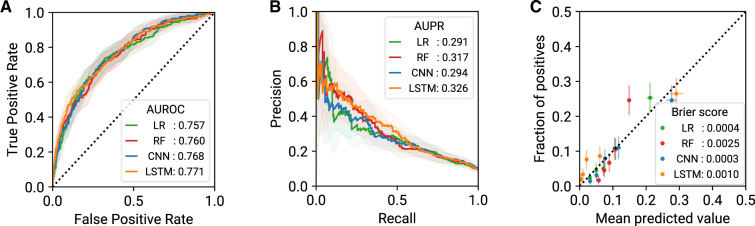
Materials and methods: Largely data-driven, FIDDLE systematically transforms structured EHR data into feature vectors, limiting the number of decisions a user must make while incorporating good practices from the literature. To demonstrate its utility and flexibility, we conducted a proof-of-concept experiment in which we applied FIDDLE to 2 publicly available EHR data sets collected from intensive care units: MIMIC-III and the eICU Collaborative Research Database. We trained different ML models to predict 3 clinically important outcomes: in-hospital mortality, acute respiratory failure, and shock. We evaluated models using the area under the receiver operating characteristics curve (AUROC), and compared it to several baselines.
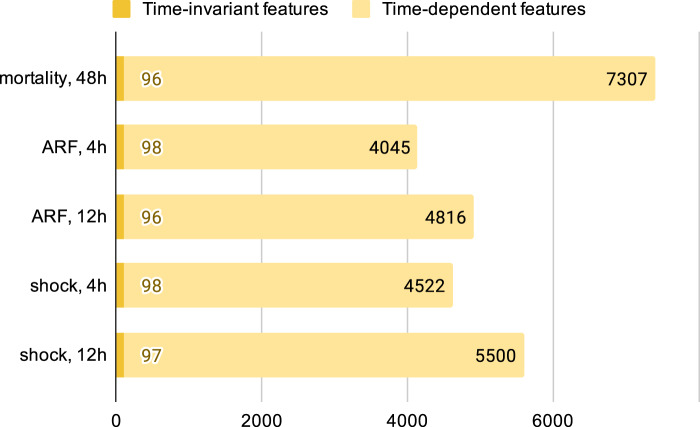
Results: Across tasks, FIDDLE extracted 2,528 to 7,403 features from MIMIC-III and eICU, respectively. On all tasks, FIDDLE-based models achieved good discriminative performance, with AUROCs of 0.757-0.886, comparable to the performance of MIMIC-Extract, a preprocessing pipeline designed specifically for MIMIC-III. Furthermore, our results showed that FIDDLE is generalizable across different prediction times, ML algorithms, and data sets, while being relatively robust to different settings of user-defined arguments.
Conclusions: FIDDLE, an open-source preprocessing pipeline, facilitates applying ML to structured EHR data. By accelerating and standardizing labor-intensive preprocessing, FIDDLE can help stimulate progress in building clinically useful ML tools for EHR data.
Keywords: electronic health records; machine learning; preprocessing pipeline.
© The Author(s) 2020. Published by Oxford University Press on behalf of the American Medical Informatics Association.
Figures
Similar articles
-
A Multidatabase ExTRaction PipEline (METRE) for facile cross validation in critical care research.J Biomed Inform. 2023 May;141:104356. doi: 10.1016/j.jbi.2023.104356. Epub 2023 Apr 5. J Biomed Inform. 2023. PMID: 37023844
-
Open Source Infrastructure for Health Care Data Integration and Machine Learning Analyses.JCO Clin Cancer Inform. 2019 Aug;3:1-16. doi: 10.1200/CCI.18.00132. JCO Clin Cancer Inform. 2019. PMID: 31454273
-
EMR-LIP: A lightweight framework for standardizing the preprocessing of longitudinal irregular data in electronic medical records.Comput Methods Programs Biomed. 2025 Feb;259:108521. doi: 10.1016/j.cmpb.2024.108521. Epub 2024 Nov 24. Comput Methods Programs Biomed. 2025. PMID: 39615196
-
Machine Learning-Based Asthma Attack Prediction Models From Routinely Collected Electronic Health Records: Systematic Scoping Review.JMIR AI. 2023 Dec 7;2:e46717. doi: 10.2196/46717. JMIR AI. 2023. PMID: 38875586 Free PMC article.
-
Comments on Contemporary Uses of Machine Learning for Electronic Health Records.N C Med J. 2024 Jun;85(4):263-265. doi: 10.18043/001c.120570. N C Med J. 2024. PMID: 39466097 Review.
Cited by
-
Applying Artificial Intelligence in Pediatric Clinical Trials: Potential Impacts and Obstacles.J Pediatr Pharmacol Ther. 2024 Jun;29(3):336-340. doi: 10.5863/1551-6776-29.3.336. Epub 2024 Jun 10. J Pediatr Pharmacol Ther. 2024. PMID: 38863862 Free PMC article. No abstract available.
-
Reformulating patient stratification for targeting interventions by accounting for severity of downstream outcomes resulting from disease onset: a case study in sepsis.J Am Med Inform Assoc. 2025 May 1;32(5):905-913. doi: 10.1093/jamia/ocaf036. J Am Med Inform Assoc. 2025. PMID: 40127468
-
A data-driven framework for clinical decision support applied to pneumonia management.Front Digit Health. 2023 Oct 9;5:1237146. doi: 10.3389/fdgth.2023.1237146. eCollection 2023. Front Digit Health. 2023. PMID: 37877124 Free PMC article.
-
EHRchitect: An open-source software tool for medical event sequences data extraction from Electronic Health Records.J Clin Transl Sci. 2025 Mar 26;9(1):e79. doi: 10.1017/cts.2025.55. eCollection 2025. J Clin Transl Sci. 2025. PMID: 40391129 Free PMC article.
-
Lifting Hospital Electronic Health Record Data Treasures: Challenges and Opportunities.JMIR Med Inform. 2022 Oct 21;10(10):e38557. doi: 10.2196/38557. JMIR Med Inform. 2022. PMID: 36269654 Free PMC article.
References
-
- Wiens J, Horvitz E, Guttag JV.. Patient risk stratification for hospital-associated C. diff as a time-series classification task. In: proceedings of the twenty-sixth annual conference on neural information processing systems (NeurIPS); December 2–6, 2012: 467–76; Lake Tahoe, Nevada.
-
- Henry KE, Hager DN, Pronovost PJ, Saria S.. A targeted real-time early warning score (TREWScore) for septic shock. Sci Transl Med 2015; 7 (299): 299ra122. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
