

No Assembly Required: Using BTyper3 to Assess the Congruency of a Proposed Taxonomic Framework for the Bacillus cereus Group With Historical Typing Methods
- PMID: 33072050
- PMCID: PMC7536271
- DOI: 10.3389/fmicb.2020.580691
No Assembly Required: Using BTyper3 to Assess the Congruency of a Proposed Taxonomic Framework for the Bacillus cereus Group With Historical Typing Methods
Abstract
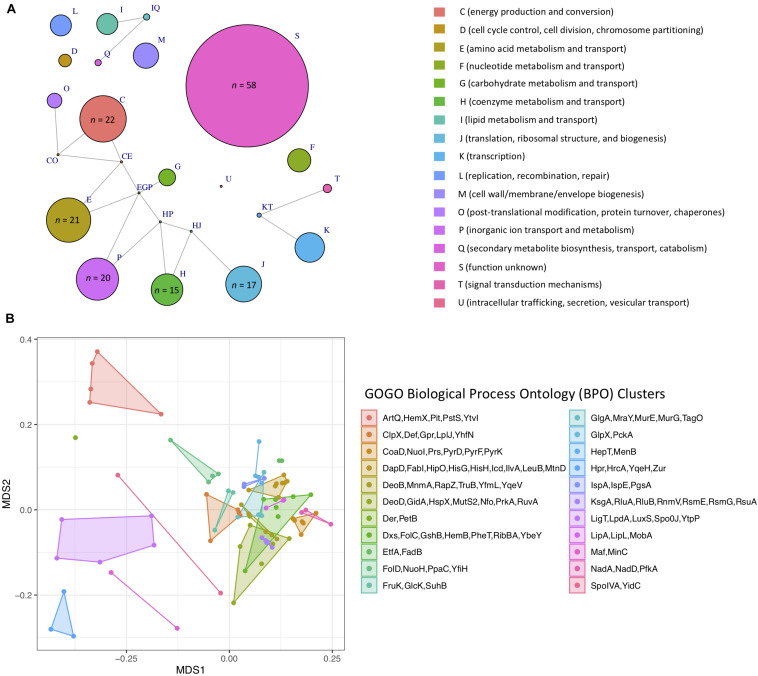
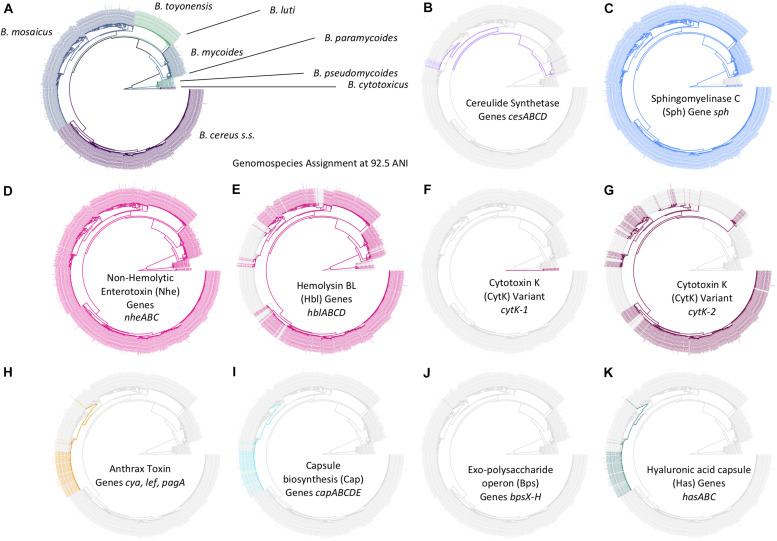
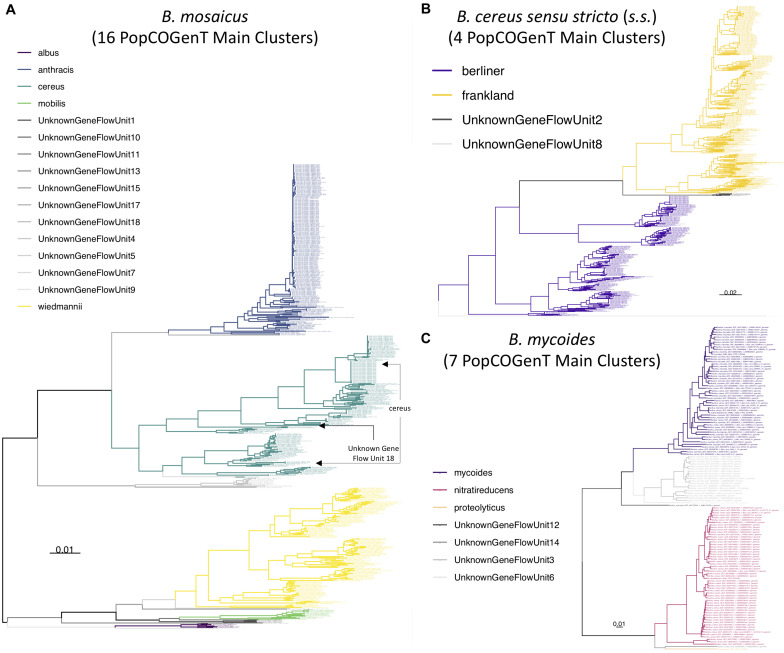
The Bacillus cereus group, also known as B. cereus sensu lato (s.l.), is a species complex comprising numerous closely related lineages, which vary in their ability to cause illness in humans and animals. The classification of B. cereus s.l. isolates into species-level taxonomic units is essential for facilitating communication between and among microbiologists, clinicians, public health officials, and industry professionals, but is not always straightforward. A recently proposed genomospecies-subspecies-biovar taxonomic framework aims to provide a standardized nomenclature for this species complex but relies heavily on whole-genome sequencing (WGS). It thus is unclear whether popular, low-cost typing methods (e.g., single- and multi-locus sequence typing) remain congruent with the proposed taxonomy. Here, we characterize 2,231 B. cereus s.l. genomes using a combination of in silico (i) average-nucleotide identity (ANI)-based genomospecies assignment, (ii) ANI-based subspecies assignment, (iii) seven-gene multi-locus sequence typing (MLST), (iv) single-locus panC group assignment, (v) rpoB allelic typing, and (vi) virulence factor detection. We show that sequence types (STs) assigned using MLST can be used for genomospecies assignment, and we provide a comprehensive list of ST/genomospecies associations. For panC group assignment, we show that an adjusted, eight-group framework is largely, albeit not perfectly, congruent with the proposed eight-genomospecies taxonomy, as panC alone may not distinguish (i) B. luti from Group II B. mosaicus and (ii) B. paramycoides from Group VI B. mycoides. We additionally provide a list of loci that capture the topology of the whole-genome B. cereus s.l. phylogeny that may be used in future sequence typing efforts. For researchers with access to WGS, MLST, and/or panC data, we showcase how our recently released software, BTyper3 (https://github.com/lmc297/BTyper3), can be used to assign B. cereus s.l. isolates to taxonomic units within this proposed framework with little-to-no user intervention or domain-specific knowledge of B. cereus s.l. taxonomy. We additionally outline a novel method for assigning B. cereus s.l. genomes to pseudo-gene flow units within proposed genomospecies. The results presented here highlight the backward-compatibility and accessibility of the recently proposed genomospecies-subspecies-biovar taxonomic framework and illustrate that WGS is not a necessity for microbiologists who want to use the proposed nomenclature effectively.
Keywords: Bacillus anthracis; Bacillus cereus; Bacillus cereus group; Bacillus thuringiensis; multi-locus sequence typing (MLST); single-locus sequence typing (SLST); taxonomy; whole-genome sequencing.
Copyright © 2020 Carroll, Cheng and Kovac.
Figures

Similar articles
-
Proposal of a Taxonomic Nomenclature for the Bacillus cereus Group Which Reconciles Genomic Definitions of Bacterial Species with Clinical and Industrial Phenotypes.mBio. 2020 Feb 25;11(1):e00034-20. doi: 10.1128/mBio.00034-20. mBio. 2020. PMID: 32098810 Free PMC article.
-
Rapid, High-Throughput Identification of Anthrax-Causing and Emetic Bacillus cereus Group Genome Assemblies via BTyper, a Computational Tool for Virulence-Based Classification of Bacillus cereus Group Isolates by Using Nucleotide Sequencing Data.Appl Environ Microbiol. 2017 Aug 17;83(17):e01096-17. doi: 10.1128/AEM.01096-17. Print 2017 Sep 1. Appl Environ Microbiol. 2017. PMID: 28625989 Free PMC article.
-
Genomic Sequencing of Bacillus cereus Sensu Lato Strains Isolated from Meat and Poultry Products in South Africa Enables Inter- and Intranational Surveillance and Source Tracking.Microbiol Spectr. 2022 Jun 29;10(3):e0070022. doi: 10.1128/spectrum.00700-22. Epub 2022 Apr 27. Microbiol Spectr. 2022. PMID: 35475639 Free PMC article.
-
Keeping up with the Bacillus cereus group: taxonomy through the genomics era and beyond.Crit Rev Food Sci Nutr. 2022;62(28):7677-7702. doi: 10.1080/10408398.2021.1916735. Epub 2021 May 3. Crit Rev Food Sci Nutr. 2022. PMID: 33939559 Review.
-
Characterization and comparative genomic analysis of bacteriophages infecting members of the Bacillus cereus group.Arch Virol. 2014 May;159(5):871-84. doi: 10.1007/s00705-013-1920-3. Epub 2013 Nov 22. Arch Virol. 2014. PMID: 24264384 Review.
Cited by
-
Strains Associated with Two 2020 Welder Anthrax Cases in the United States Belong to Separate Lineages within Bacillus cereus sensu lato.Pathogens. 2022 Jul 29;11(8):856. doi: 10.3390/pathogens11080856. Pathogens. 2022. PMID: 36014977 Free PMC article.
-
Characterization of a Deep Sea Bacillus toyonensis Isolate: Genomic and Pathogenic Features.Front Cell Infect Microbiol. 2021 Mar 10;11:629116. doi: 10.3389/fcimb.2021.629116. eCollection 2021. Front Cell Infect Microbiol. 2021. PMID: 33777842 Free PMC article.
-
Antimicrobial and Phylogenomic Characterization of Bacillus cereus Group Strains Isolated from Different Food Sources in Italy.Antibiotics (Basel). 2024 Sep 20;13(9):898. doi: 10.3390/antibiotics13090898. Antibiotics (Basel). 2024. PMID: 39335071 Free PMC article.
-
Toxigenic Genes, Pathogenic Potential and Antimicrobial Resistance of Bacillus cereus Group Isolated from Ice Cream and Characterized by Whole Genome Sequencing.Foods. 2022 Aug 17;11(16):2480. doi: 10.3390/foods11162480. Foods. 2022. PMID: 36010481 Free PMC article.
-
Comparison of the performance of multiple whole-genome sequence-based tools for the identification of Bacillus cereus sensu stricto biovar Thuringiensis.Appl Environ Microbiol. 2024 Apr 17;90(4):e0177823. doi: 10.1128/aem.01778-23. Epub 2024 Mar 12. Appl Environ Microbiol. 2024. PMID: 38470126 Free PMC article.
References
-
- Antonation K. S., Grutzmacher K., Dupke S., Mabon P., Zimmermann F., Lankester F., et al. (2016). Bacillus cereus Biovar anthracis causing anthrax in sub-saharan Africa-chromosomal monophyly and broad geographic distribution. PLoS Negl. Trop. Dis. 10:e0004923. 10.1371/journal.pntd.0004923 - DOI - PMC - PubMed
LinkOut - more resources
Full Text Sources
Molecular Biology Databases