

DNA mismatches reveal conformational penalties in protein-DNA recognition
- PMID: 33087930
- PMCID: PMC7666076
- DOI: 10.1038/s41586-020-2843-2
DNA mismatches reveal conformational penalties in protein-DNA recognition
Abstract
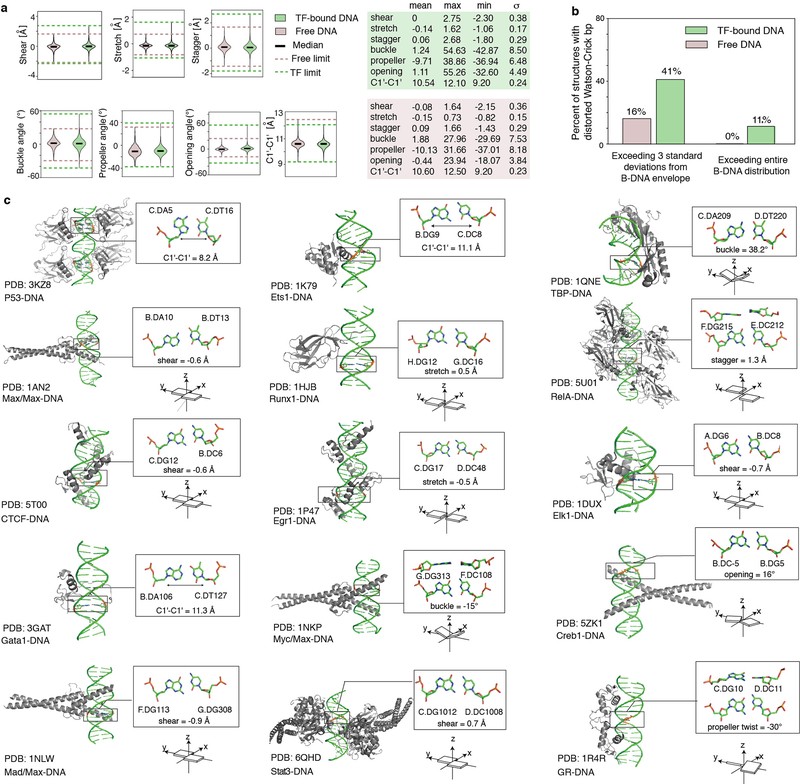
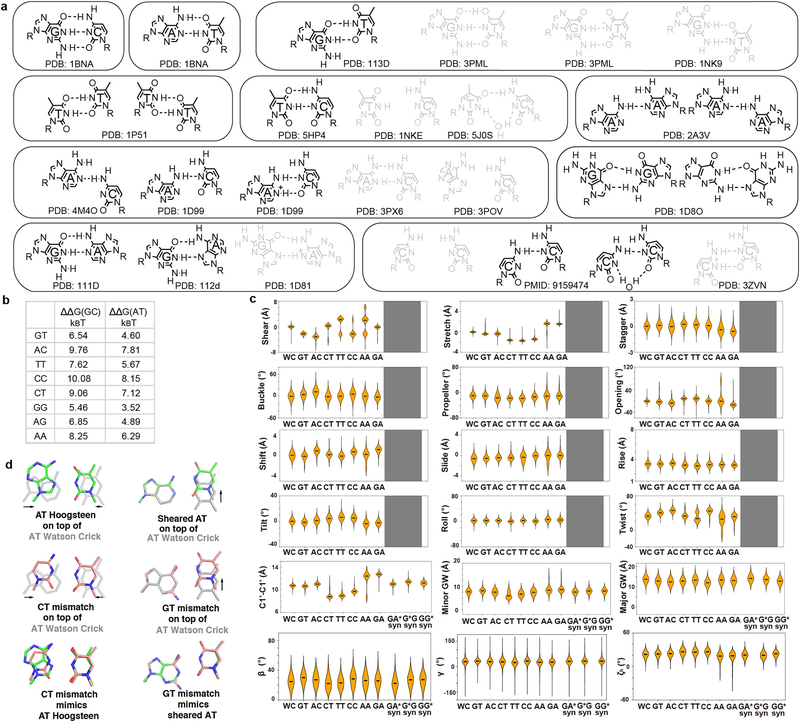
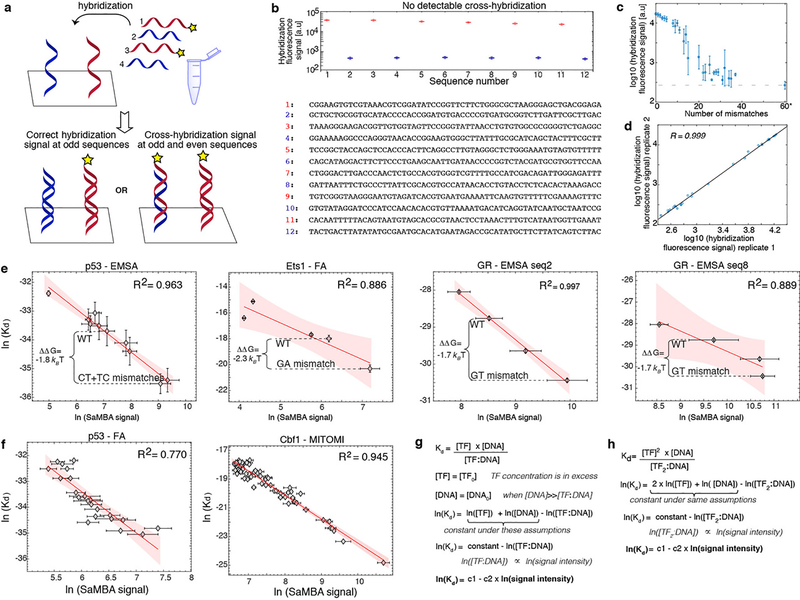
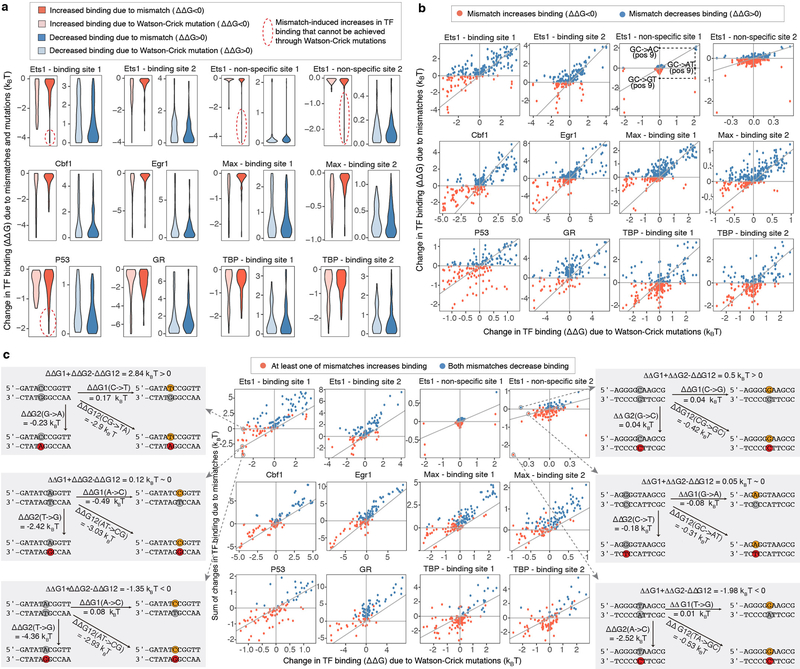
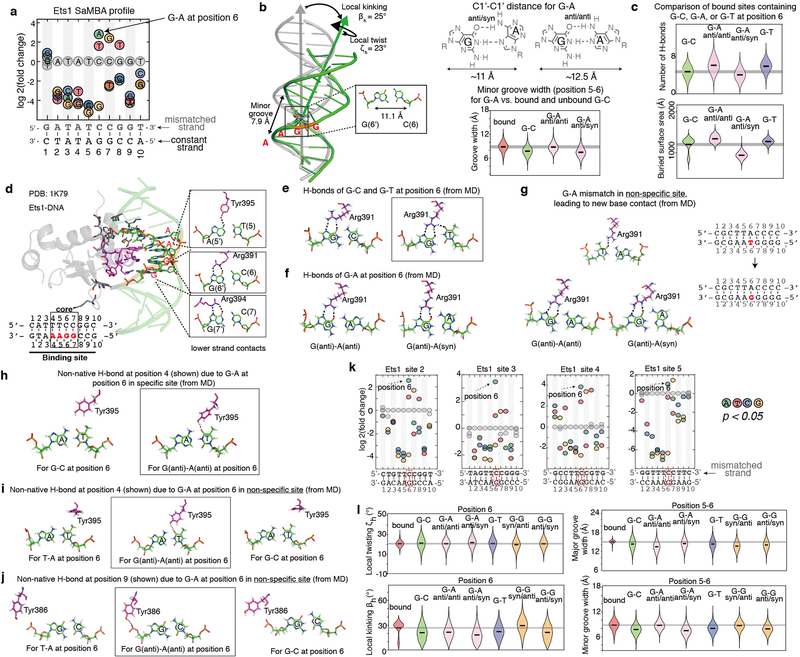
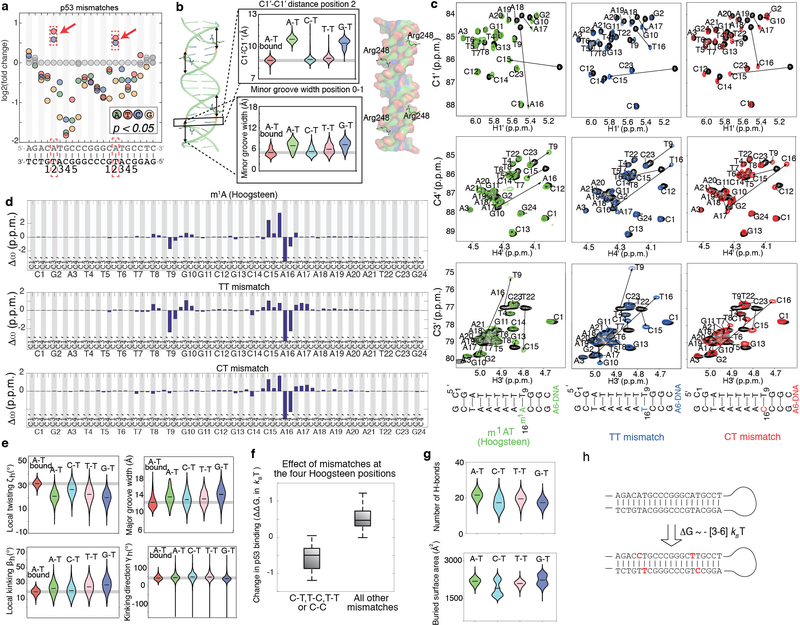
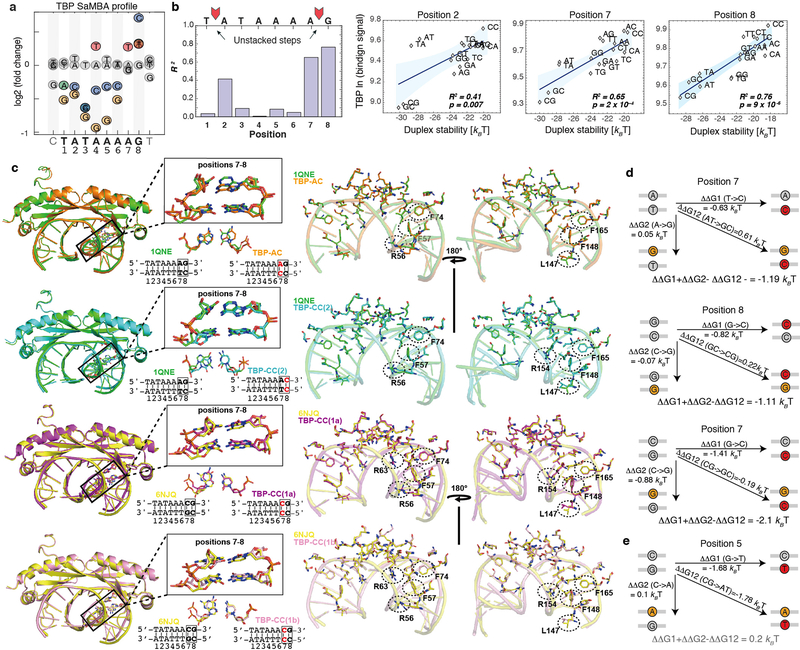
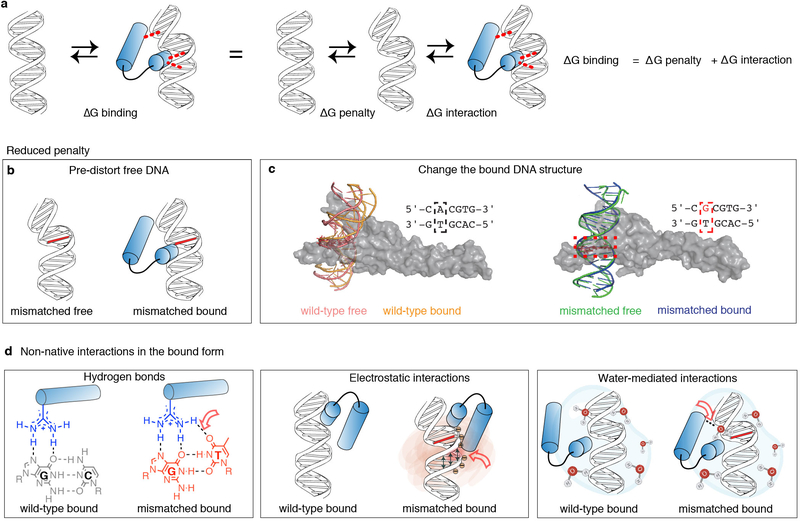
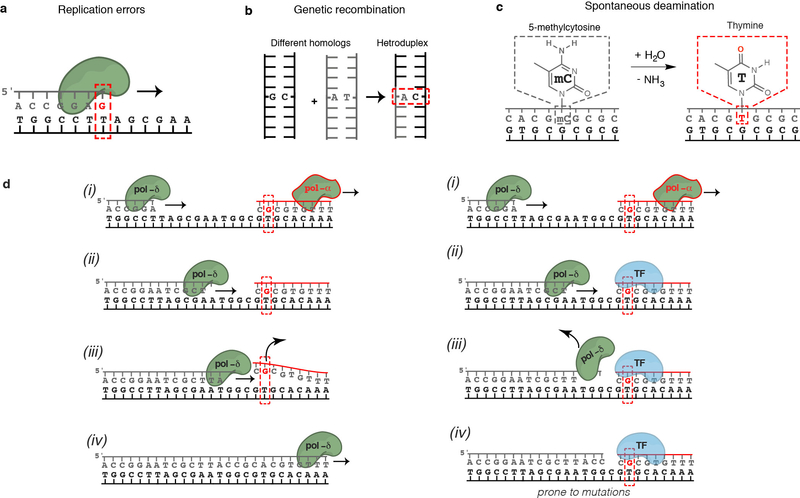
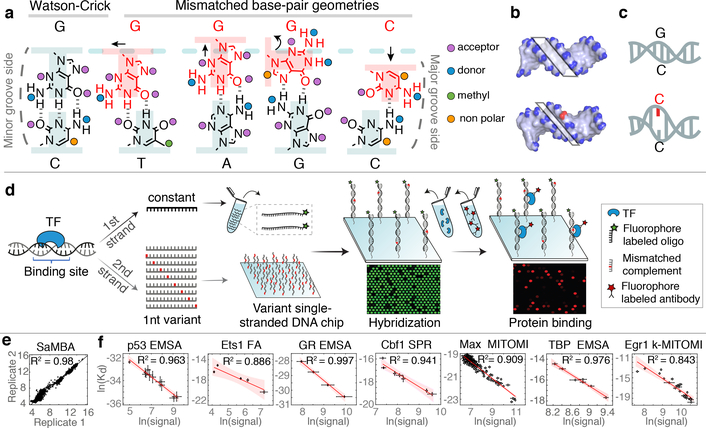
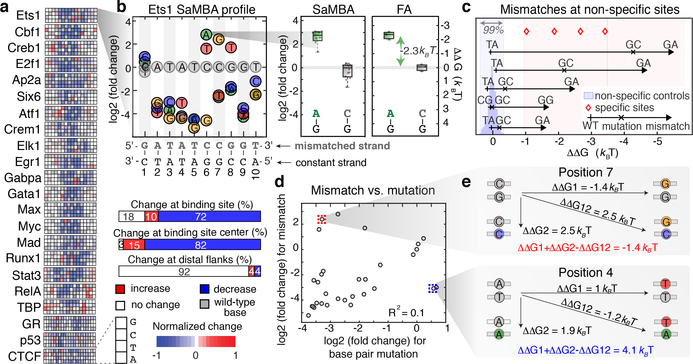
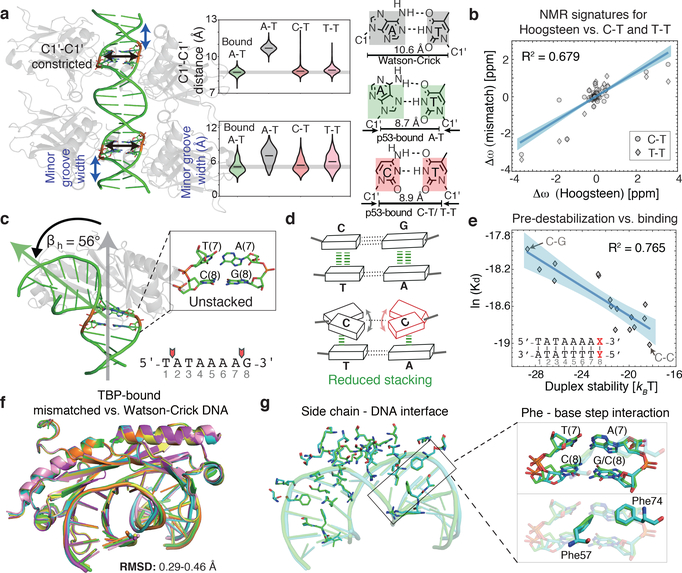
Transcription factors recognize specific genomic sequences to regulate complex gene-expression programs. Although it is well-established that transcription factors bind to specific DNA sequences using a combination of base readout and shape recognition, some fundamental aspects of protein-DNA binding remain poorly understood1,2. Many DNA-binding proteins induce changes in the structure of the DNA outside the intrinsic B-DNA envelope. However, how the energetic cost that is associated with distorting the DNA contributes to recognition has proven difficult to study, because the distorted DNA exists in low abundance in the unbound ensemble3-9. Here we use a high-throughput assay that we term SaMBA (saturation mismatch-binding assay) to investigate the role of DNA conformational penalties in transcription factor-DNA recognition. In SaMBA, mismatched base pairs are introduced to pre-induce structural distortions in the DNA that are much larger than those induced by changes in the Watson-Crick sequence. Notably, approximately 10% of mismatches increased transcription factor binding, and for each of the 22 transcription factors that were examined, at least one mismatch was found that increased the binding affinity. Mismatches also converted non-specific sites into high-affinity sites, and high-affinity sites into 'super sites' that exhibit stronger affinity than any known canonical binding site. Determination of high-resolution X-ray structures, combined with nuclear magnetic resonance measurements and structural analyses, showed that many of the DNA mismatches that increase binding induce distortions that are similar to those induced by protein binding-thus prepaying some of the energetic cost incurred from deforming the DNA. Our work indicates that conformational penalties are a major determinant of protein-DNA recognition, and reveals mechanisms by which mismatches can recruit transcription factors and thus modulate replication and repair activities in the cell10,11.
Conflict of interest statement
Ethics declaration
The authors declare no competing interests.
Figures
Comment in
-
DNA-binding proteins meet their mismatch.Nature. 2020 Nov;587(7833):199-200. doi: 10.1038/d41586-020-02658-x. Nature. 2020. PMID: 33087865 No abstract available.
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
