

Distributional Reinforcement Learning in the Brain
- PMID: 33092893
- PMCID: PMC8073212
- DOI: 10.1016/j.tins.2020.09.004
Distributional Reinforcement Learning in the Brain
Abstract
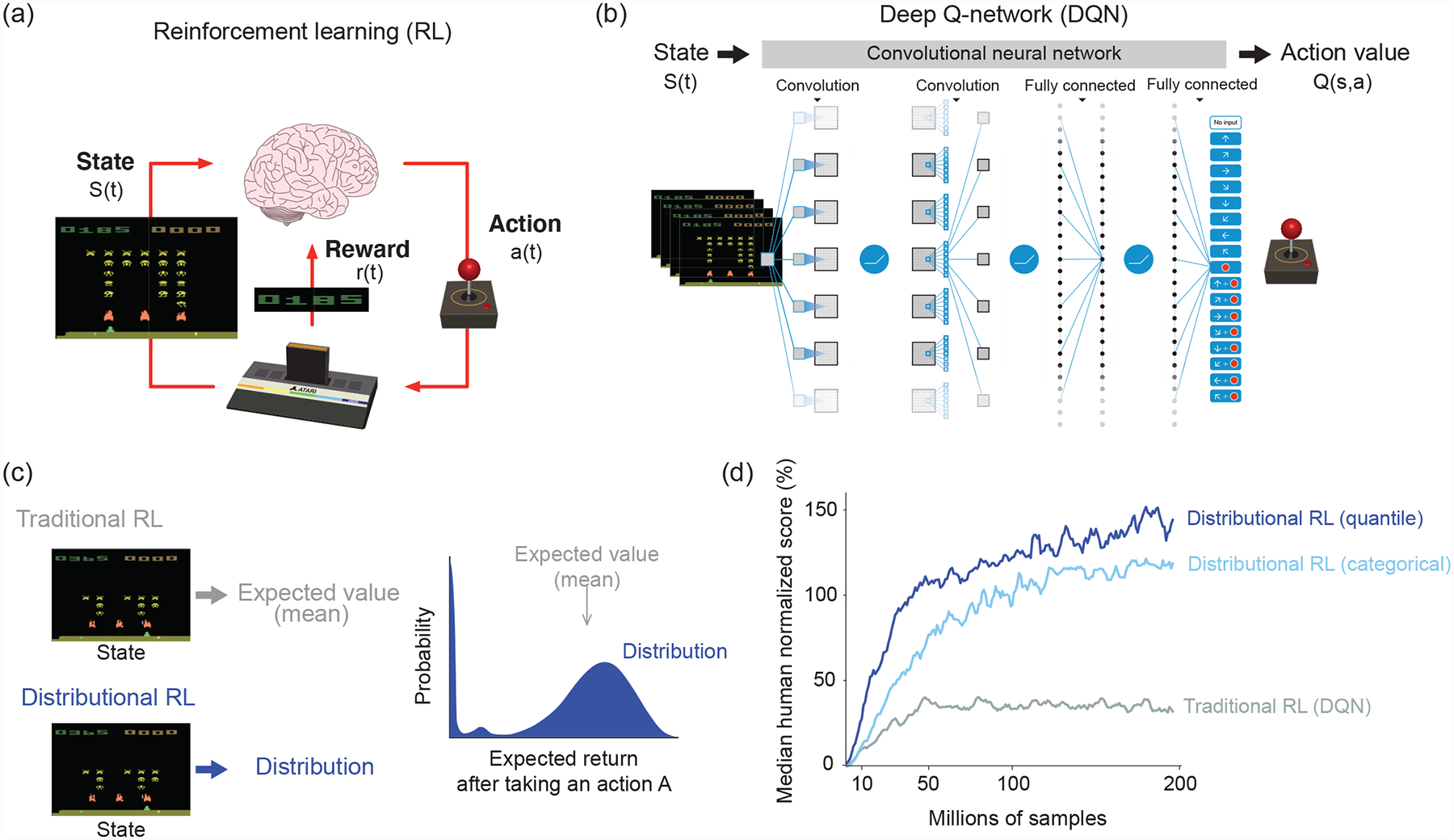
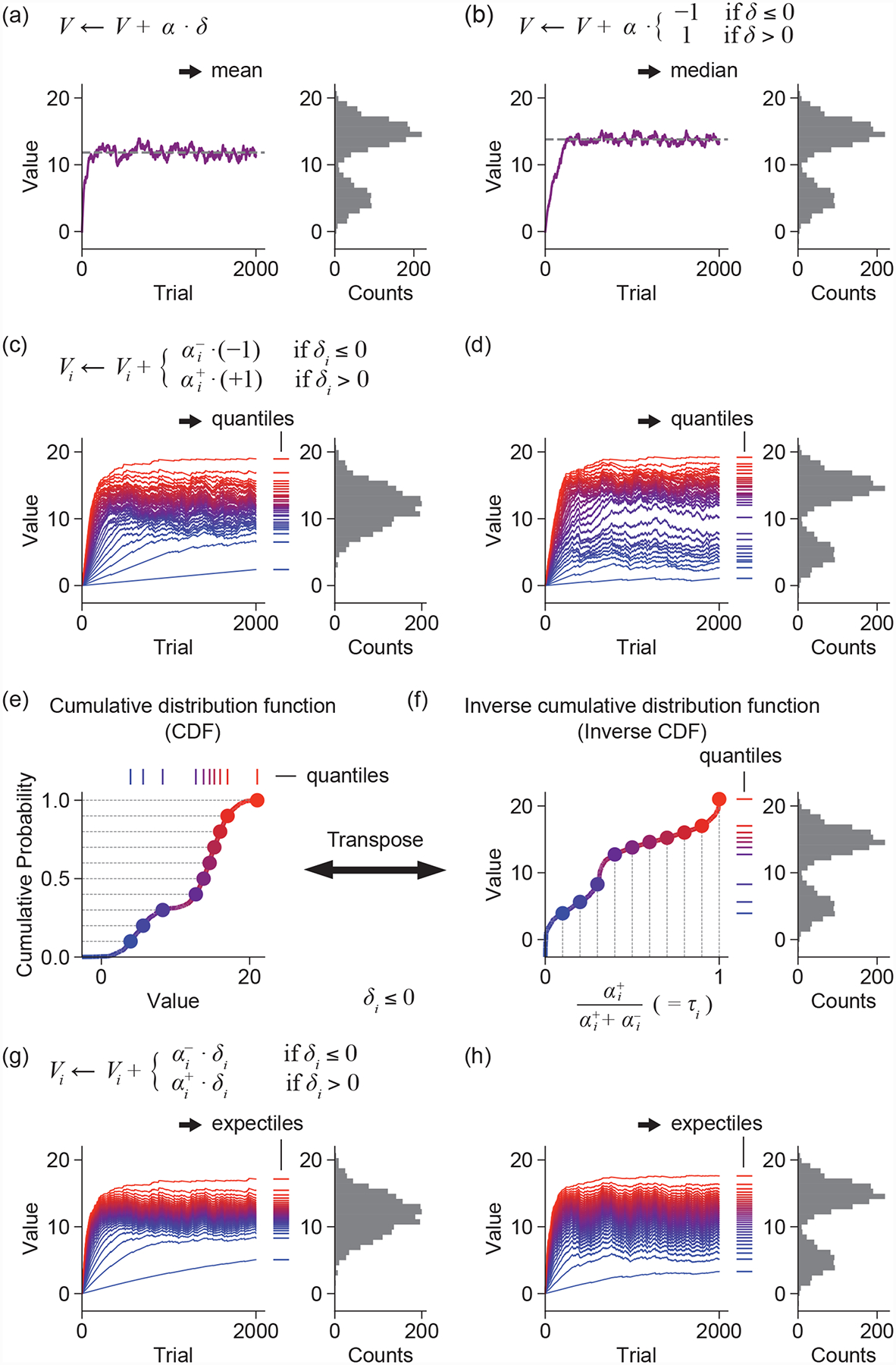
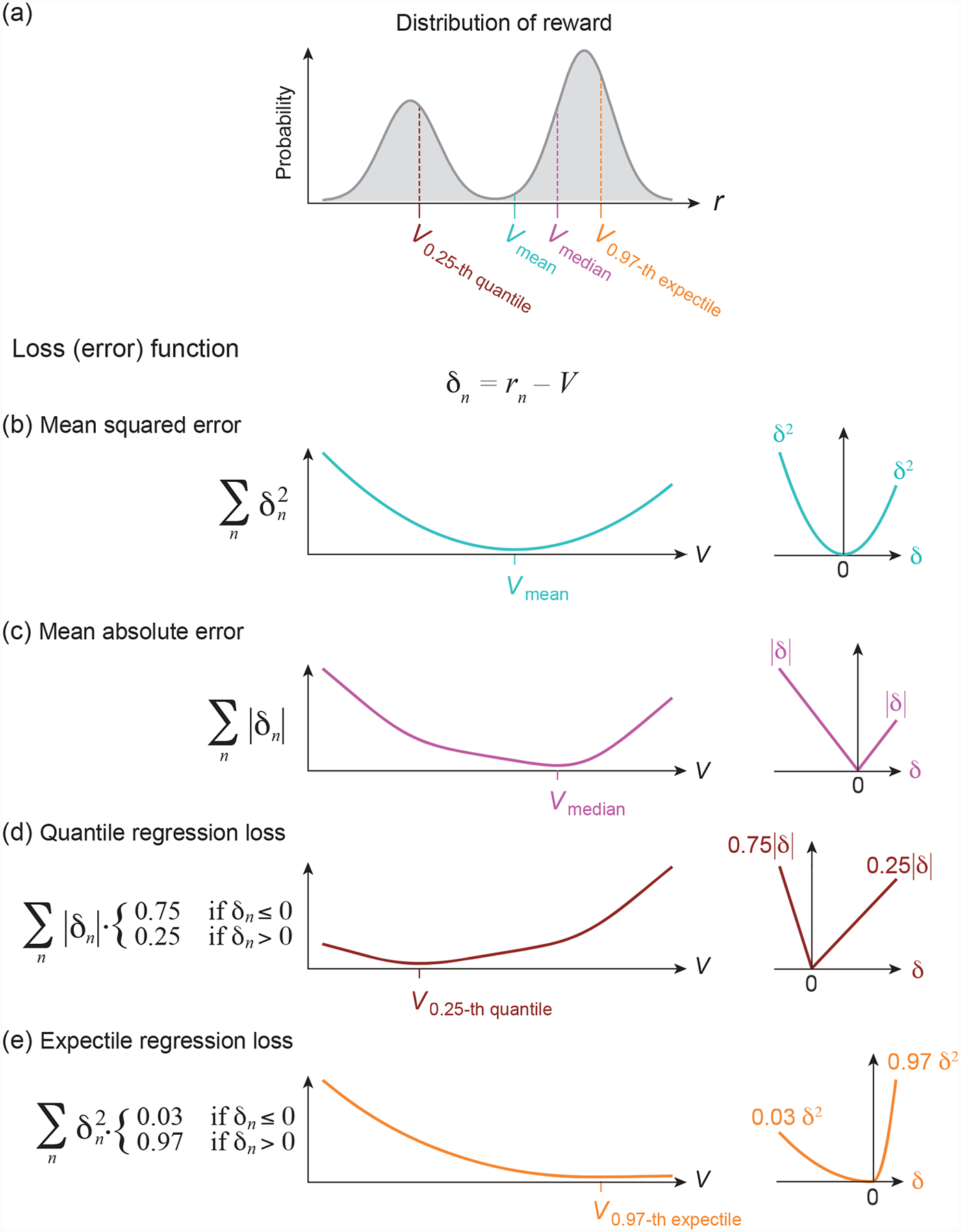
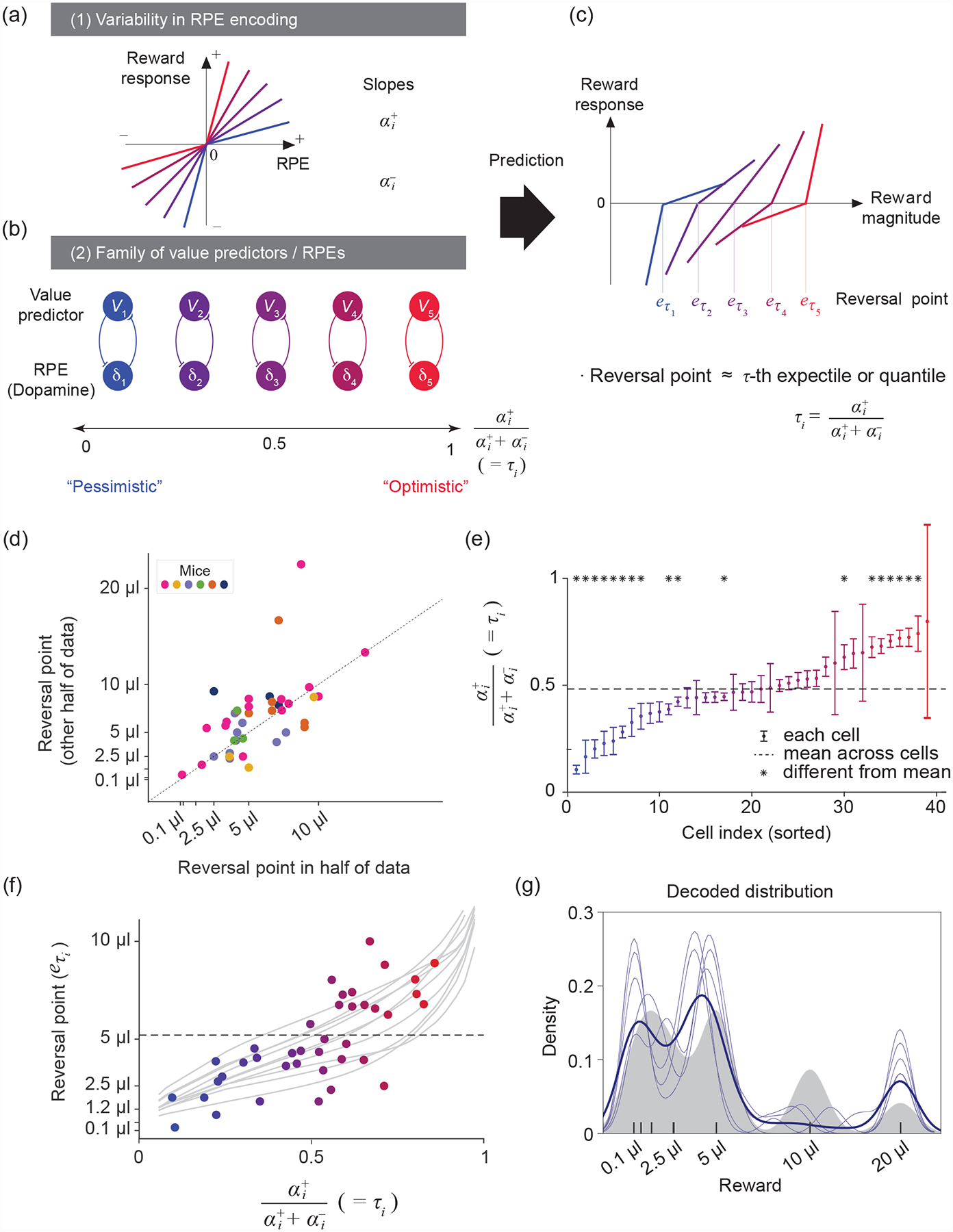
Learning about rewards and punishments is critical for survival. Classical studies have demonstrated an impressive correspondence between the firing of dopamine neurons in the mammalian midbrain and the reward prediction errors of reinforcement learning algorithms, which express the difference between actual reward and predicted mean reward. However, it may be advantageous to learn not only the mean but also the complete distribution of potential rewards. Recent advances in machine learning have revealed a biologically plausible set of algorithms for reconstructing this reward distribution from experience. Here, we review the mathematical foundations of these algorithms as well as initial evidence for their neurobiological implementation. We conclude by highlighting outstanding questions regarding the circuit computation and behavioral readout of these distributional codes.
Keywords: artificial intelligence; deep neural networks; dopamine; machine learning; population coding; reward.
Copyright © 2020 The Author(s). Published by Elsevier Ltd.. All rights reserved.
Figures
Similar articles
-
A distributional code for value in dopamine-based reinforcement learning.Nature. 2020 Jan;577(7792):671-675. doi: 10.1038/s41586-019-1924-6. Epub 2020 Jan 15. Nature. 2020. PMID: 31942076 Free PMC article.
-
Dopamine errors drive excitatory and inhibitory components of backward conditioning in an outcome-specific manner.Curr Biol. 2022 Jul 25;32(14):3210-3218.e3. doi: 10.1016/j.cub.2022.06.035. Epub 2022 Jun 24. Curr Biol. 2022. PMID: 35752165
-
An opponent striatal circuit for distributional reinforcement learning.Nature. 2025 Mar;639(8055):717-726. doi: 10.1038/s41586-024-08488-5. Epub 2025 Feb 19. Nature. 2025. PMID: 39972123 Free PMC article.
-
Understanding dopamine and reinforcement learning: the dopamine reward prediction error hypothesis.Proc Natl Acad Sci U S A. 2011 Sep 13;108 Suppl 3(Suppl 3):15647-54. doi: 10.1073/pnas.1014269108. Epub 2011 Mar 9. Proc Natl Acad Sci U S A. 2011. PMID: 21389268 Free PMC article. Review.
-
Predictive reward signal of dopamine neurons.J Neurophysiol. 1998 Jul;80(1):1-27. doi: 10.1152/jn.1998.80.1.1. J Neurophysiol. 1998. PMID: 9658025 Review.
Cited by
-
Glutamate inputs send prediction error of reward but not negative value of aversive stimuli to dopamine neurons.bioRxiv [Preprint]. 2023 Nov 9:2023.11.09.566472. doi: 10.1101/2023.11.09.566472. bioRxiv. 2023. Update in: Neuron. 2024 Mar 20;112(6):1001-1019.e6. doi: 10.1016/j.neuron.2023.12.019. PMID: 37986868 Free PMC article. Updated. Preprint.
-
Interoception as modeling, allostasis as control.Biol Psychol. 2022 Jan;167:108242. doi: 10.1016/j.biopsycho.2021.108242. Epub 2021 Dec 20. Biol Psychol. 2022. PMID: 34942287 Free PMC article.
-
Investigating Transfer Learning in Noisy Environments: A Study of Predecessor and Successor Features in Spatial Learning Using a T-Maze.Sensors (Basel). 2024 Oct 3;24(19):6419. doi: 10.3390/s24196419. Sensors (Basel). 2024. PMID: 39409459 Free PMC article.
-
Decision-Making, Pro-variance Biases and Mood-Related Traits.Comput Psychiatr. 2024 Aug 21;8(1):142-158. doi: 10.5334/cpsy.114. eCollection 2024. Comput Psychiatr. 2024. PMID: 39184228 Free PMC article.
-
Ketamine rescues anhedonia by cell-type- and input-specific adaptations in the nucleus accumbens.Neuron. 2025 May 7;113(9):1398-1412.e4. doi: 10.1016/j.neuron.2025.02.021. Epub 2025 Mar 19. Neuron. 2025. PMID: 40112815
References
-
- LeCun Y et al. (2015) Deep learning. Nature 521, 436–444 - PubMed
-
- Mnih V et al. (2015) Human-level control through deep reinforcement learning. Nature 518, 529–533 - PubMed
-
- Silver D et al. (2016) Mastering the game of Go with deep neural networks and tree search. Nature 529, 484–489 - PubMed
-
- Botvinick M et al. (2019) Reinforcement Learning, Fast and Slow. Trends Cogn. Sci. (Regul. Ed.) 23, 408–422 - PubMed
-
- Hassabis D et al. (2017) Neuroscience-Inspired Artificial Intelligence. Neuron 95, 245–258 - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
