

The Temporal Fine Structure of Background Noise Determines the Benefit of Bimodal Hearing for Recognizing Speech
- PMID: 33104927
- PMCID: PMC7644728
- DOI: 10.1007/s10162-020-00772-1
The Temporal Fine Structure of Background Noise Determines the Benefit of Bimodal Hearing for Recognizing Speech
Abstract
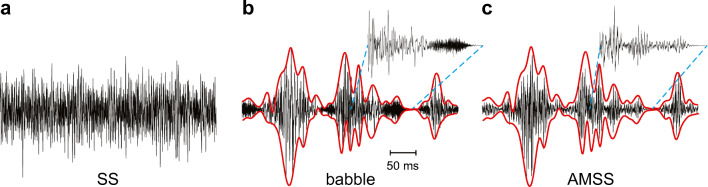
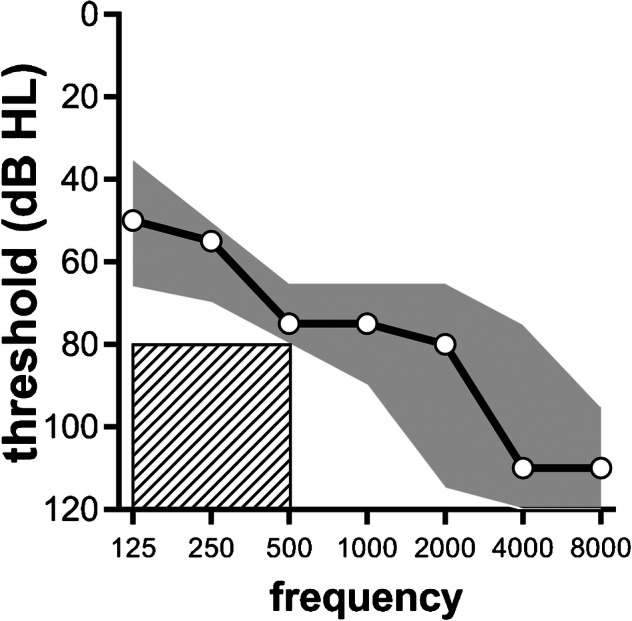
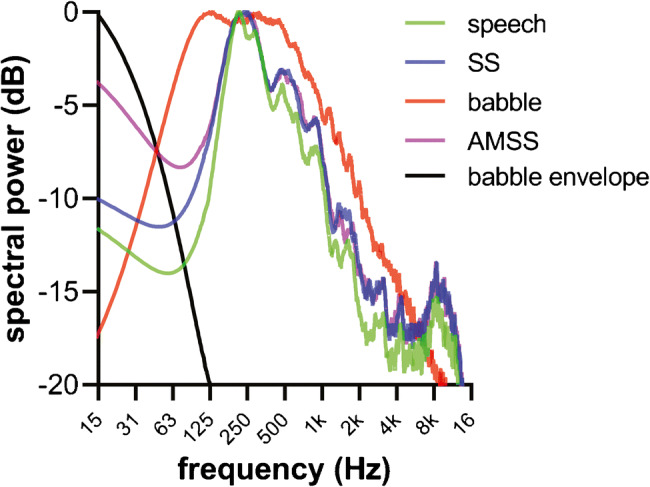
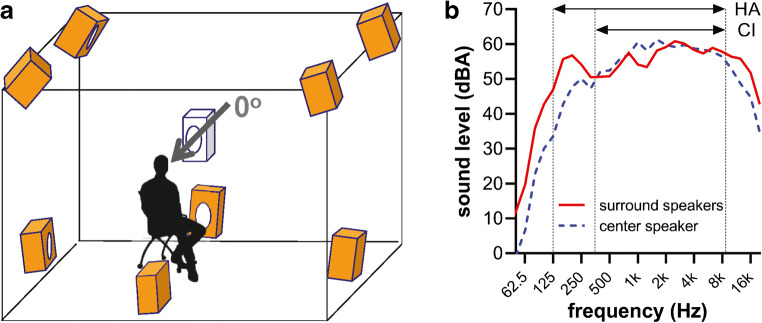
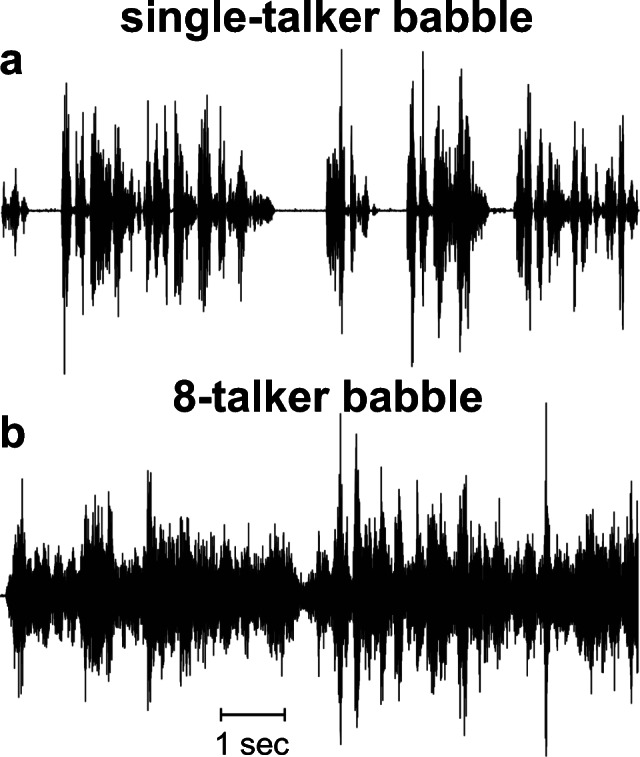
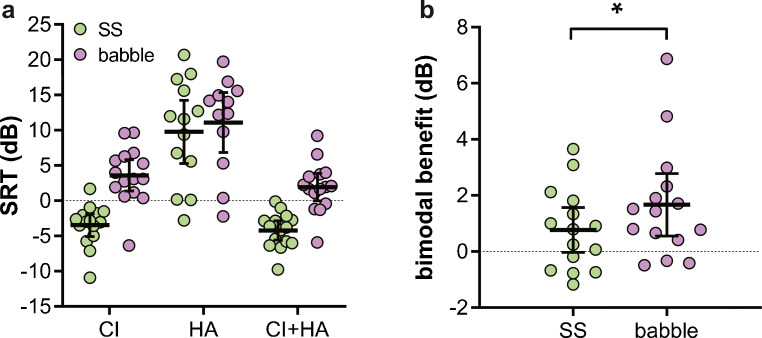
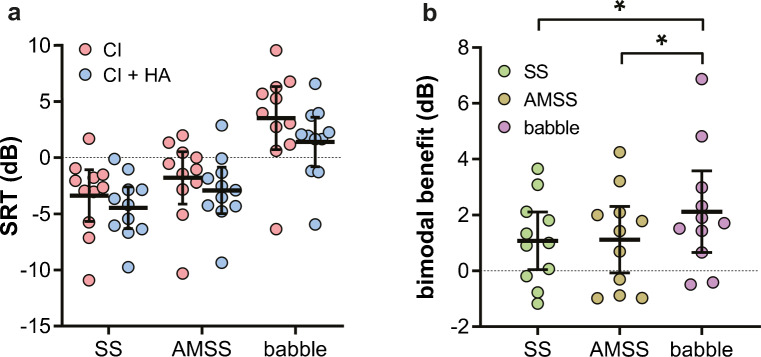
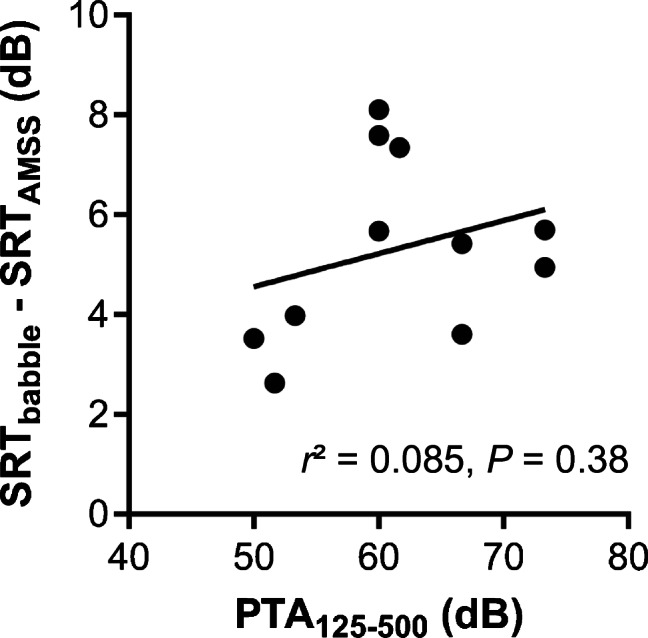
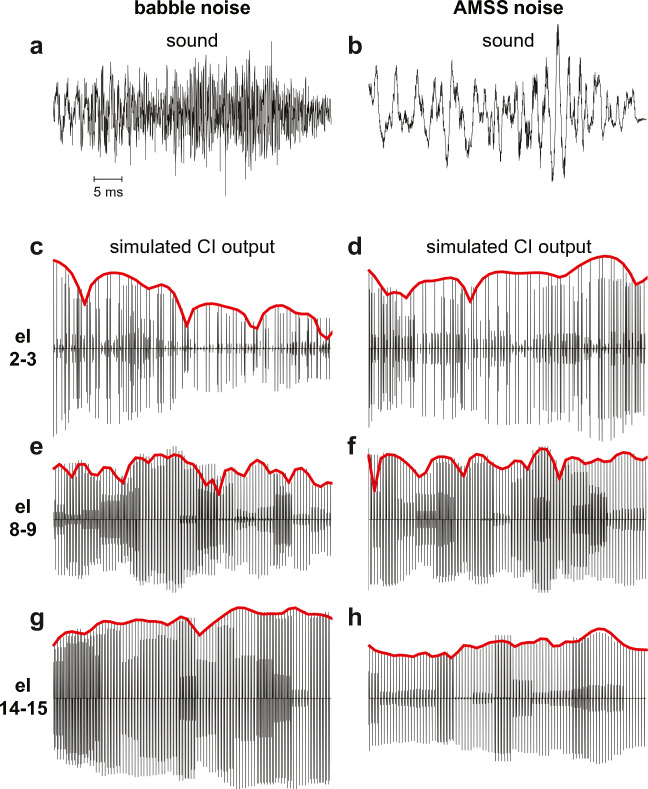
Cochlear implant (CI) users have more difficulty understanding speech in temporally modulated noise than in steady-state (SS) noise. This is thought to be caused by the limited low-frequency information that CIs provide, as well as by the envelope coding in CIs that discards the temporal fine structure (TFS). Contralateral amplification with a hearing aid, referred to as bimodal hearing, can potentially provide CI users with TFS cues to complement the envelope cues provided by the CI signal. In this study, we investigated whether the use of a CI alone provides access to only envelope cues and whether acoustic amplification can provide additional access to TFS cues. To this end, we evaluated speech recognition in bimodal listeners, using SS noise and two amplitude-modulated noise types, namely babble noise and amplitude-modulated steady-state (AMSS) noise. We hypothesized that speech recognition in noise depends on the envelope of the noise, but not on its TFS when listening with a CI. Secondly, we hypothesized that the amount of benefit gained by the addition of a contralateral hearing aid depends on both the envelope and TFS of the noise. The two amplitude-modulated noise types decreased speech recognition more effectively than SS noise. Against expectations, however, we found that babble noise decreased speech recognition more effectively than AMSS noise in the CI-only condition. Therefore, we rejected our hypothesis that TFS is not available to CI users. In line with expectations, we found that the bimodal benefit was highest in babble noise. However, there was no significant difference between the bimodal benefit obtained in SS and AMSS noise. Our results suggest that a CI alone can provide TFS cues and that bimodal benefits in noise depend on TFS, but not on the envelope of the noise.
Keywords: bimodal hearing; cochlear implants; hearing aids; sensorineural hearing loss; speech intelligibility; speech perception.
Conflict of interest statement
The authors declare that they have no conflict of interest.
Figures
References
-
- Advanced Bionics LLC (2009) HiRes Fidelity 120® sound processing - implementing active current steering for increased spectral resolution in Harmony® HiResolution® bionic ear users White paper
-
- Advanced Bionics LLC (2016) Optimizing hearing for listeners with a ccochlear implant and contralateral hearing aid. Adaptive Phonak digital bimodal fitting formula. White paper
-
- Armstrong M, Pegg P, James C, Blarney P. Speech perception in noise with implant and hearing aid. Otol Neurotol. 1997;18:S140–S141. - PubMed
-
- Arnoldner C, Riss D, Brunner M, Durisin M, Baumgartner W-D, Hamzavi GT, Jafar S. Speech and music perception with the new fine structure speech coding strategy: preliminary results. Acta Otolaryngol. 2007;127:1298–1303. - PubMed
-
- Avan P, Giraudet F, Büki B. Importance of binaural hearing. Audiol Neurotol. 2015;20(suppl 1):3–6. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
