

Comparison of distributed memory algorithms for X-ray wave propagation in inhomogeneous media
- PMID: 33114856
- PMCID: PMC7679186
- DOI: 10.1364/OE.400240
Comparison of distributed memory algorithms for X-ray wave propagation in inhomogeneous media
Abstract
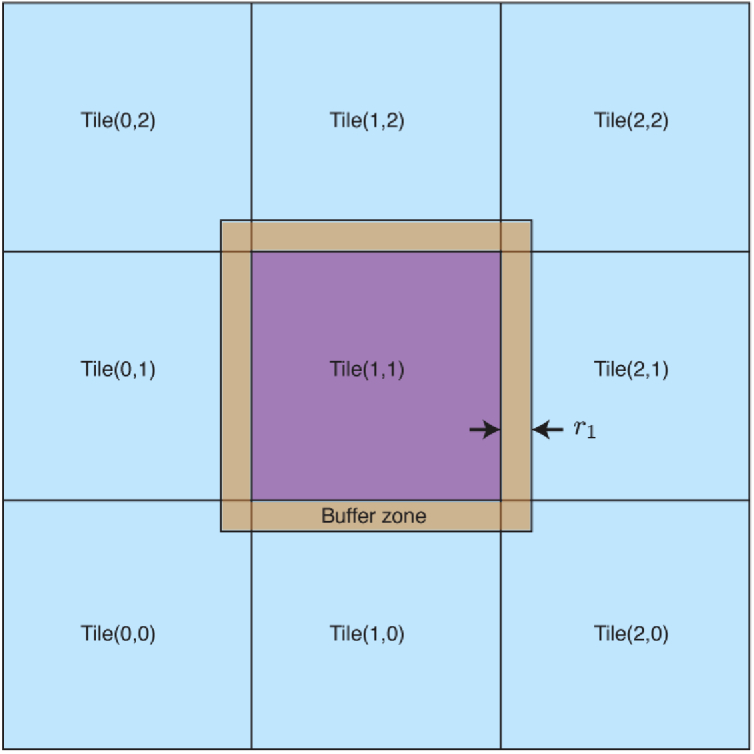
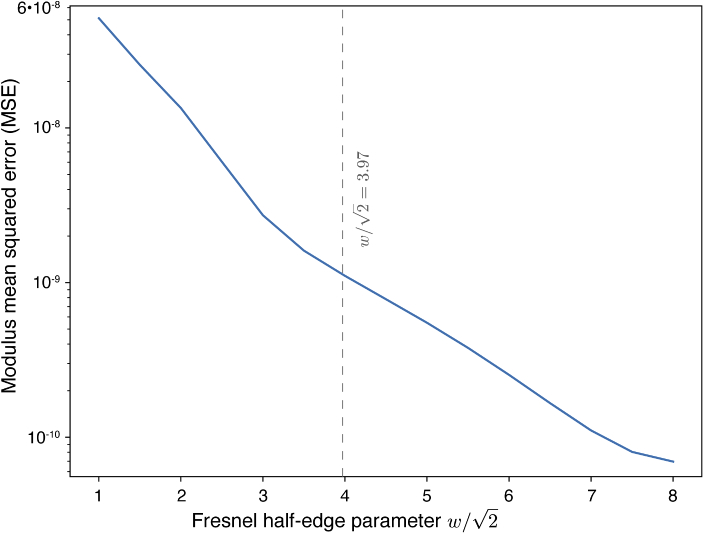
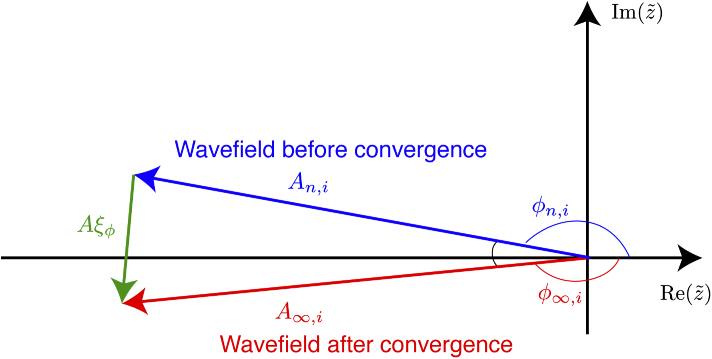
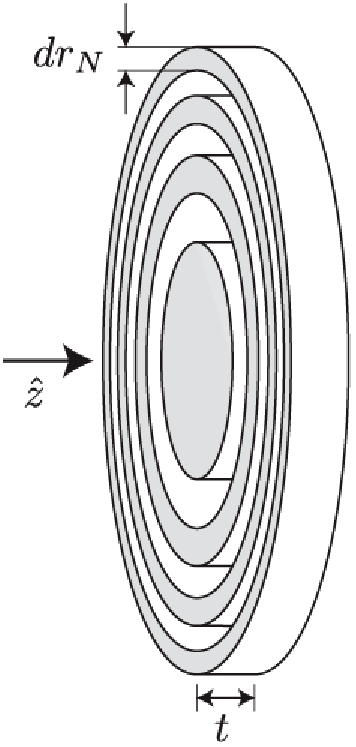
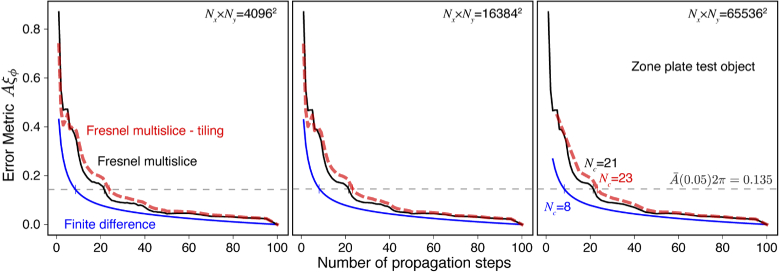
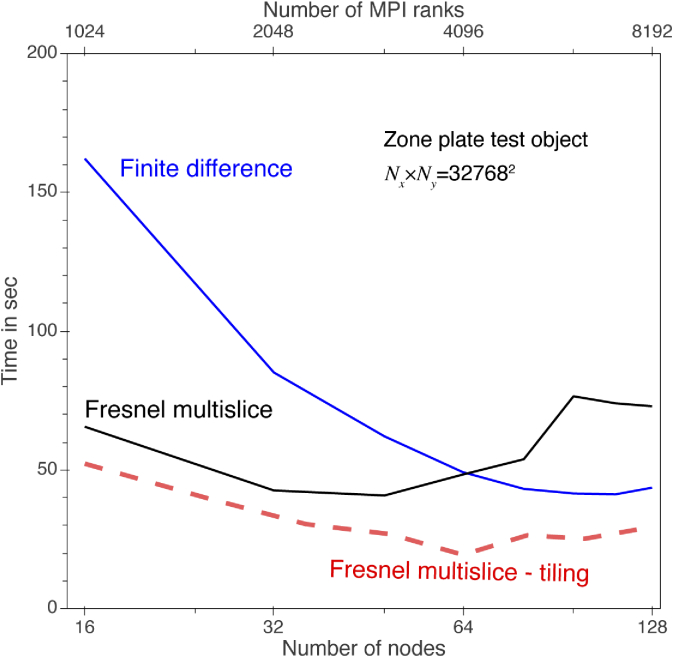
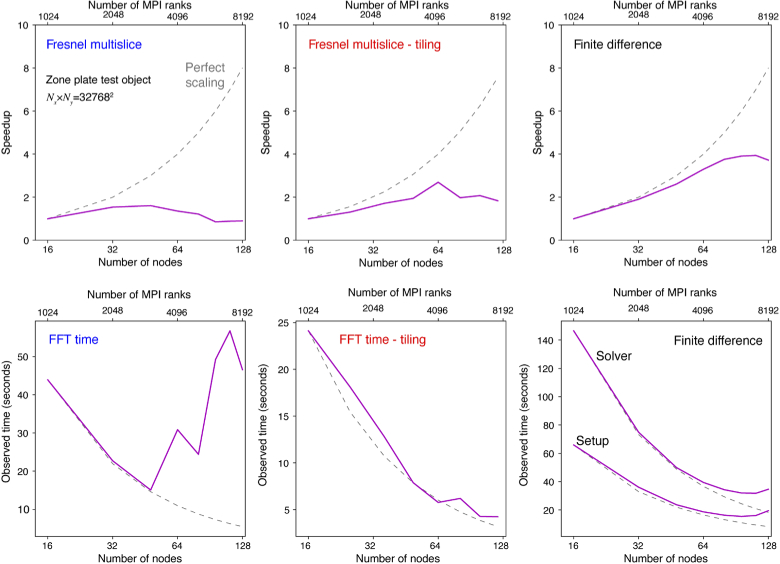
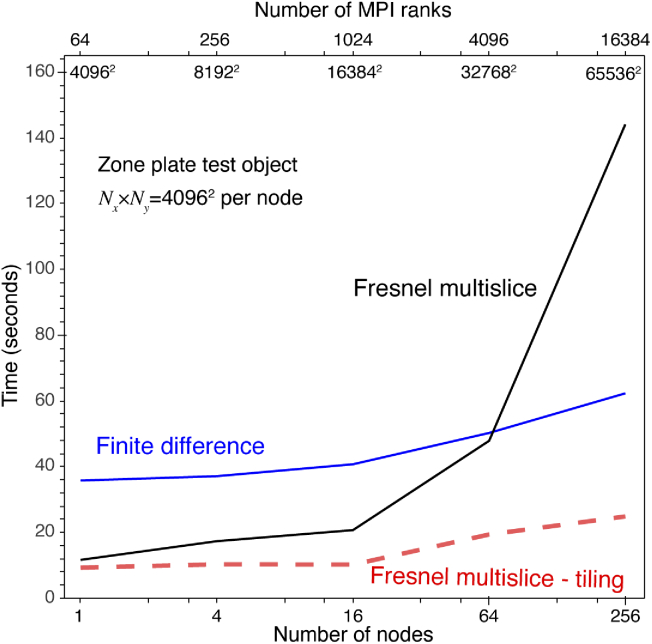
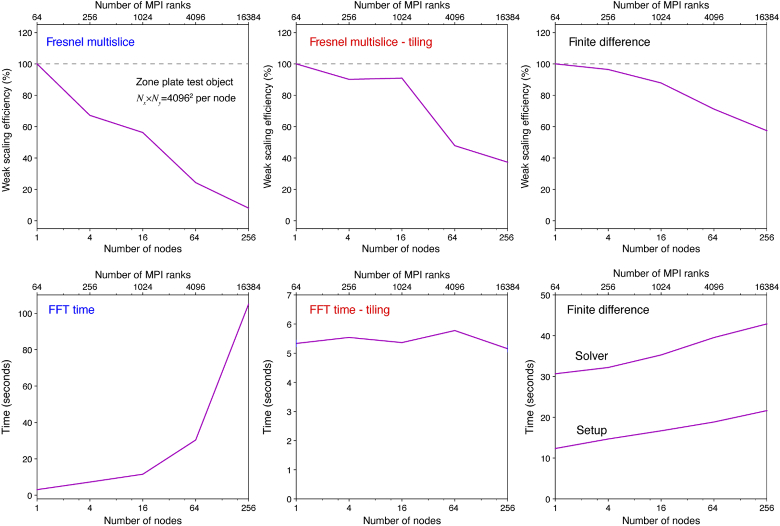
Calculations of X-ray wave propagation in large objects are needed for modeling diffractive X-ray optics and for optimization-based approaches to image reconstruction for objects that extend beyond the depth of focus. We describe three methods for calculating wave propagation with large arrays on parallel computing systems with distributed memory: (1) a full-array Fresnel multislice approach, (2) a tiling-based short-distance Fresnel multislice approach, and (3) a finite difference approach. We find that the first approach suffers from internode communication delays when the transverse array size becomes large, while the second and third approaches have similar scaling to large array size problems (with the second approach offering about three times the compute speed).
Conflict of interest statement
The authors declare no conflicts of interest.
Figures
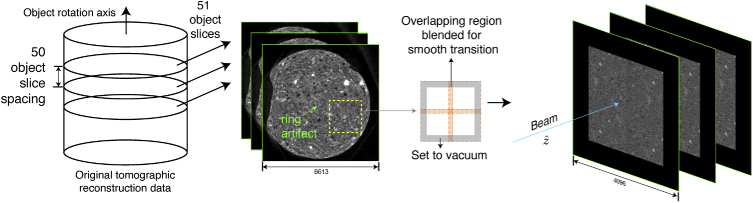
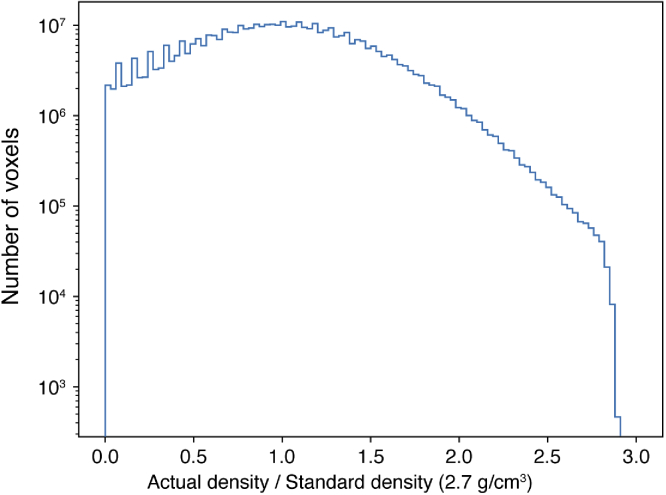
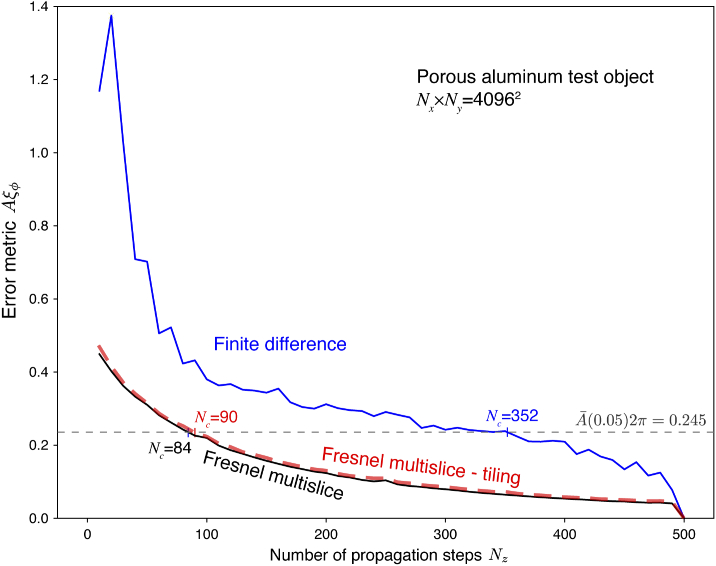
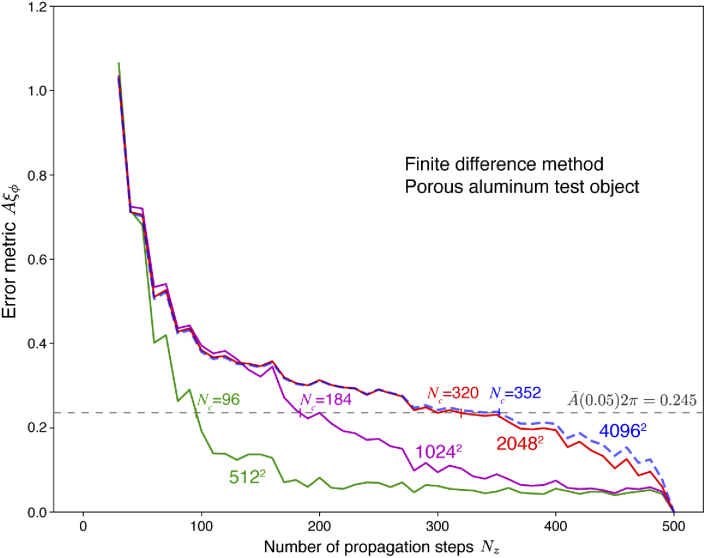
References
-
- Born M., Wolf E., Principles of Optics (Cambridge University Press, Cambridge, 1999), seventh ed.
-
- Jacobsen C., X-ray Microscopy (Cambridge University Press, Cambridge, 2020).
