

Order Matters! Influences of Linear Order on Linguistic Category Learning
- PMID: 33124103
- PMCID: PMC7685149
- DOI: 10.1111/cogs.12910
Order Matters! Influences of Linear Order on Linguistic Category Learning
Abstract
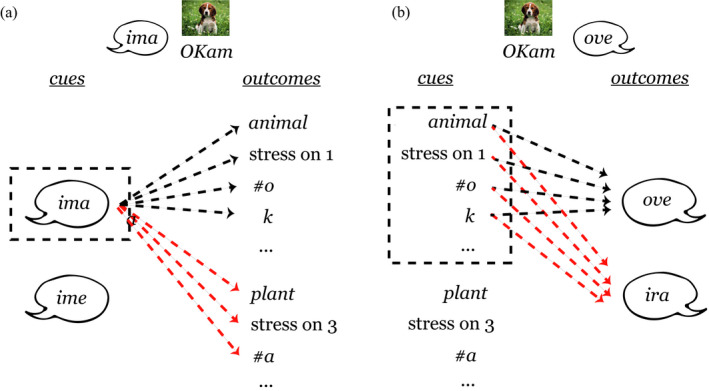
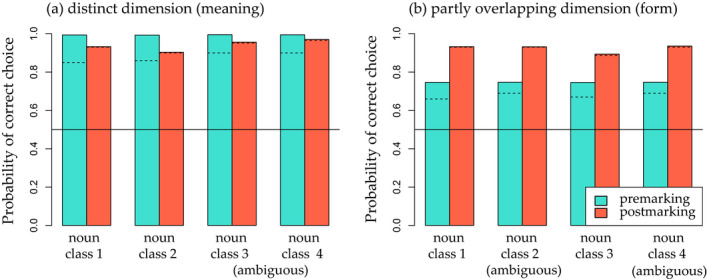
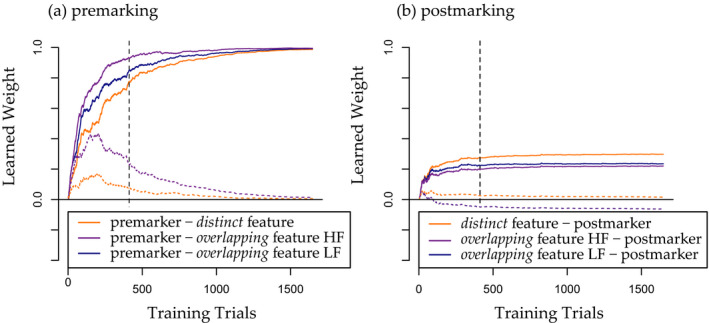
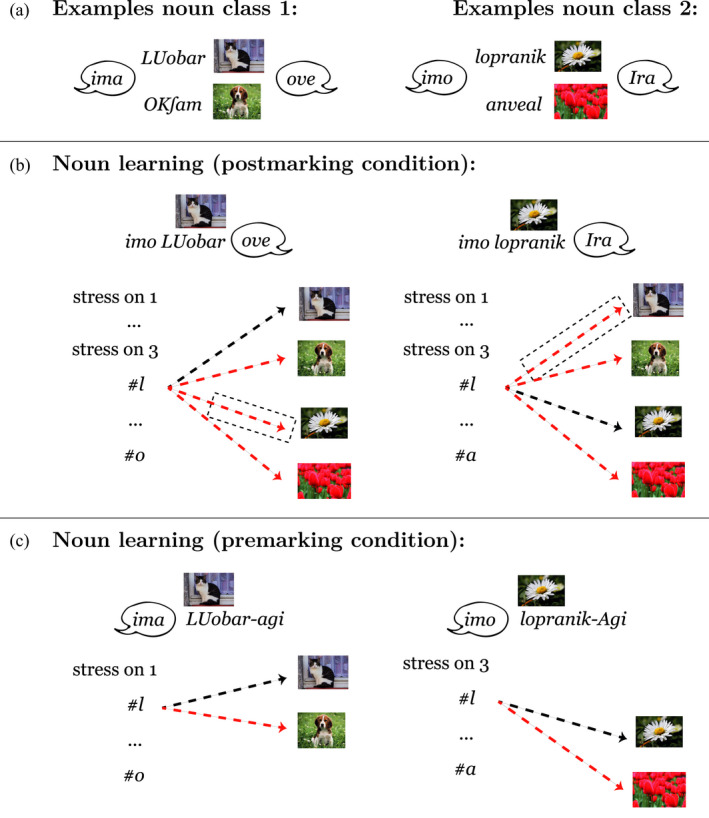
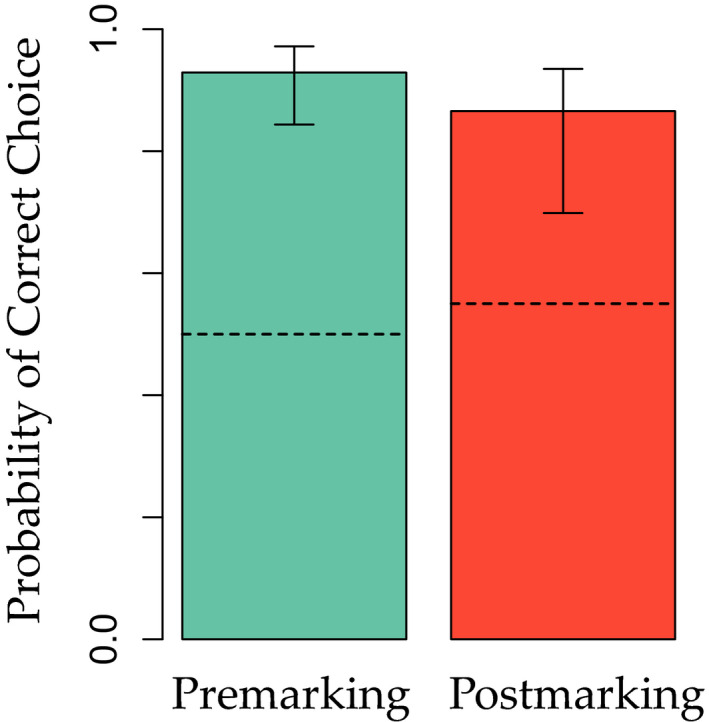
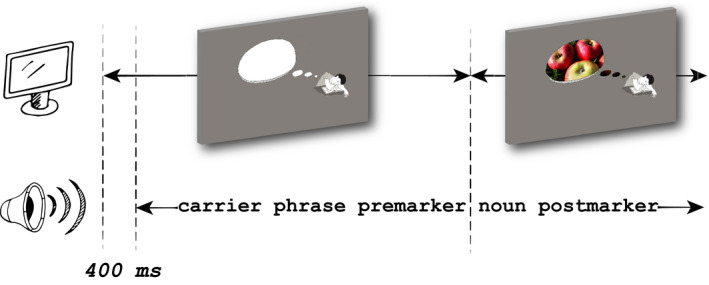
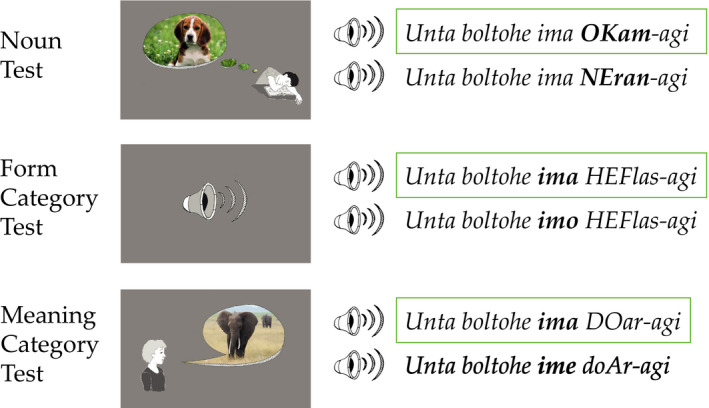
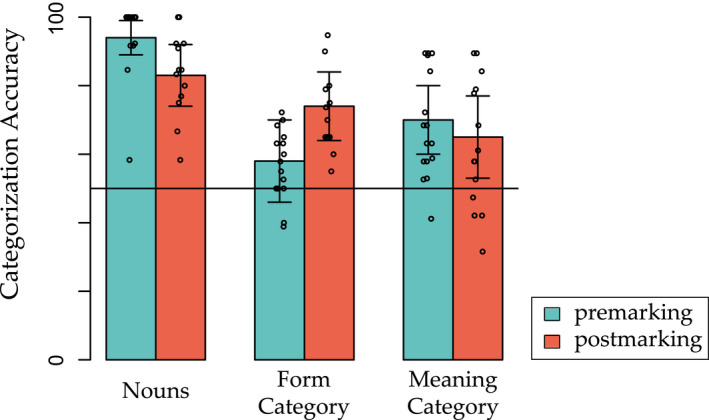
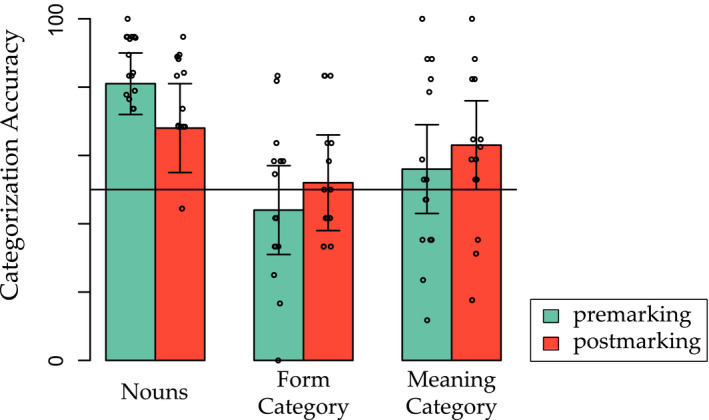
Linguistic category learning has been shown to be highly sensitive to linear order, and depending on the task, differentially sensitive to the information provided by preceding category markers (premarkers, e.g., gendered articles) or succeeding category markers (postmarkers, e.g., gendered suffixes). Given that numerous systems for marking grammatical categories exist in natural languages, it follows that a better understanding of these findings can shed light on the factors underlying this diversity. In two discriminative learning simulations and an artificial language learning experiment, we identify two factors that modulate linear order effects in linguistic category learning: category structure and the level of abstraction in a category hierarchy. Regarding category structure, we find that postmarking brings an advantage for learning category diagnostic stimulus dimensions, an effect not present when categories are non-confusable. Regarding levels of abstraction, we find that premarking of super-ordinate categories (e.g., noun class) facilitates learning of subordinate categories (e.g., nouns). We present detailed simulations using a plausible candidate mechanism for the observed effects, along with a comprehensive analysis of linear order effects within an expectation-based account of learning. Our findings indicate that linguistic category learning is differentially guided by pre- and postmarking, and that the influence of each is modulated by the specific characteristics of a given category system.
Keywords: Artificial language learning experiment; Behavioral experiment; Computational simulation; Discriminative learning; Error-driven learning; Linguistic categories.
© 2020 The Authors. Cognitive Science published by Wiley Periodicals LLC on behalf of Cognitive Science Society (CSS).
Figures
References
-
- Aizenberg, I. , Aizenberg, N. N. , & Vandewalle, J. P. (2013). Multi‐valued and universal binary neurons: Theory, learning and applications. Dordrecht, The Netherlands: Springer Science & Business Media.
-
- Akaike, H. (2011). Akaike's information criterion In Lovric M. (Ed.), International encyclopedia of statistical science (p. 25). Berlin/Heidelberg: Springer.
-
- Arnon, I. , & Ramscar, M. (2012). Granularity and the acquisition of grammatical gender: How order‐of‐acquisition affects what gets learned. Cognition, 122(3), 292–305. - PubMed
-
- Arppe, A. , Hendrix, P. , Milin, P. , Baayen, R. H. , Sering, T. , & Shaoul, C. (2018). ndl: Naive discriminative learning. R package version 0.2.18. Available at: https://CRAN.R‐project.org/package=ndl. Accessed September 28, 2020.
-
- Boersma, P. , & Escudero, P. (2008). Learning to perceive a smaller L2 vowel inventory: An optimality theory account In Avery P., Dresher B. E. & Rice K. (Eds.), Contrast in phonology: Theory, perception, acquisition (pp. 271–301). Berlin: Mouton de Gruyter.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
