

Amino Acid k-mer Feature Extraction for Quantitative Antimicrobial Resistance (AMR) Prediction by Machine Learning and Model Interpretation for Biological Insights
- PMID: 33126516
- PMCID: PMC7694136
- DOI: 10.3390/biology9110365
Amino Acid k-mer Feature Extraction for Quantitative Antimicrobial Resistance (AMR) Prediction by Machine Learning and Model Interpretation for Biological Insights
Abstract
Machine learning algorithms can learn mechanisms of antimicrobial resistance from the data of DNA sequence without any a priori information. Interpreting a trained machine learning algorithm can be exploited for validating the model and obtaining new information about resistance mechanisms. Different feature extraction methods, such as SNP calling and counting nucleotide k-mers have been proposed for presenting DNA sequences to the model. However, there are trade-offs between interpretability, computational complexity and accuracy for different feature extraction methods. In this study, we have proposed a new feature extraction method, counting amino acid k-mers or oligopeptides, which provides easier model interpretation compared to counting nucleotide k-mers and reaches the same or even better accuracy in comparison with different methods. Additionally, we have trained machine learning algorithms using different feature extraction methods and compared the results in terms of accuracy, model interpretability and computational complexity. We have built a new feature selection pipeline for extraction of important features so that new AMR determinants can be discovered by analyzing these features. This pipeline allows the construction of models that only use a small number of features and can predict resistance accurately.
Keywords: SNP; amino acid; antimicrobial resistance; gene clustering; genome sequencing; k-mer counting; machine learning; nucleotide.
Conflict of interest statement
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Figures









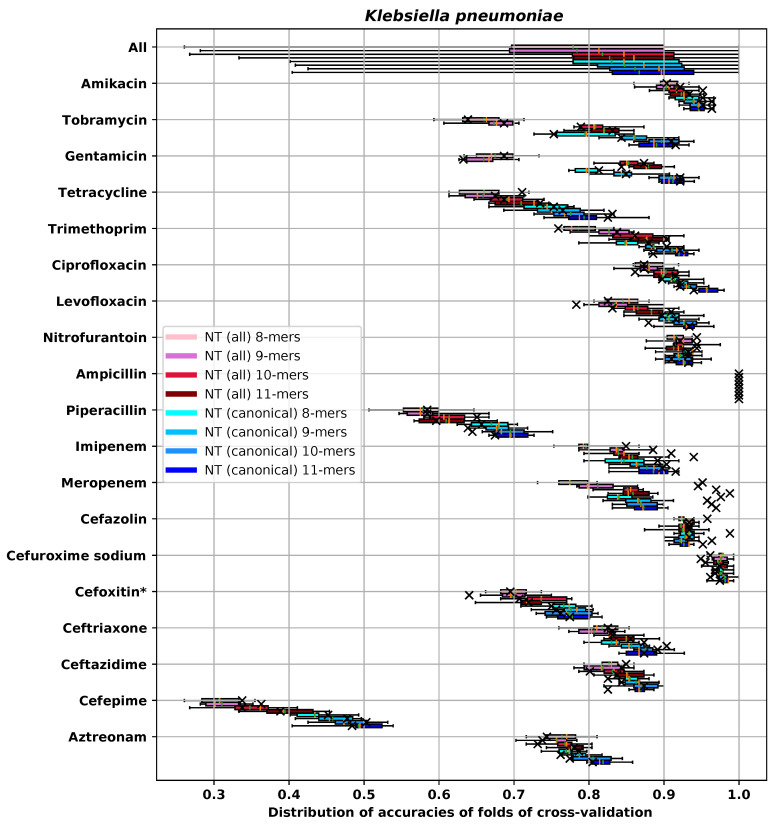




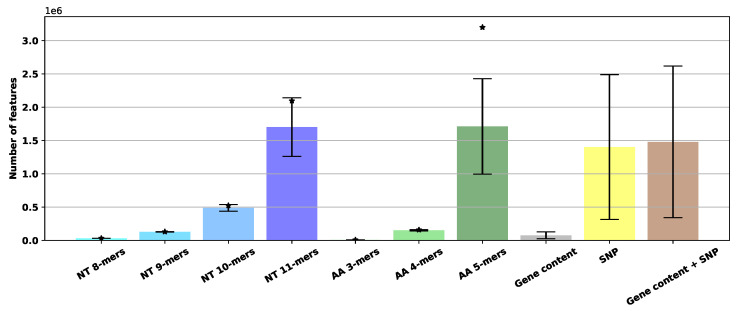






References
-
- Cassini A., Högberg L.D., Plachouras D., Quattrocchi A., Hoxha A., Simonsen G.S., Colomb-Cotinat M., Kretzschmar M.E., Devleesschauwer B., Cecchini M., et al. Attributable deaths and disability-adjusted life-years caused by infections with antibiotic-resistant bacteria in the EU and the European Economic Area in 2015: A population-level modelling analysis. Lancet Infect. Dis. 2019;19:56–66. doi: 10.1016/S1473-3099(18)30605-4. - DOI - PMC - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
