

Integrating when and what information in the left parietal lobe allows language rule generalization
- PMID: 33137084
- PMCID: PMC7660506
- DOI: 10.1371/journal.pbio.3000895
Integrating when and what information in the left parietal lobe allows language rule generalization
Abstract
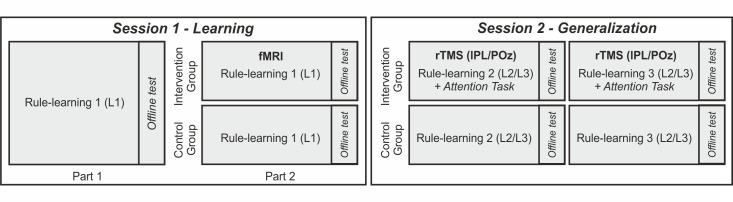
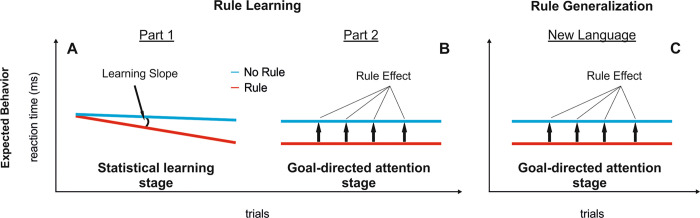
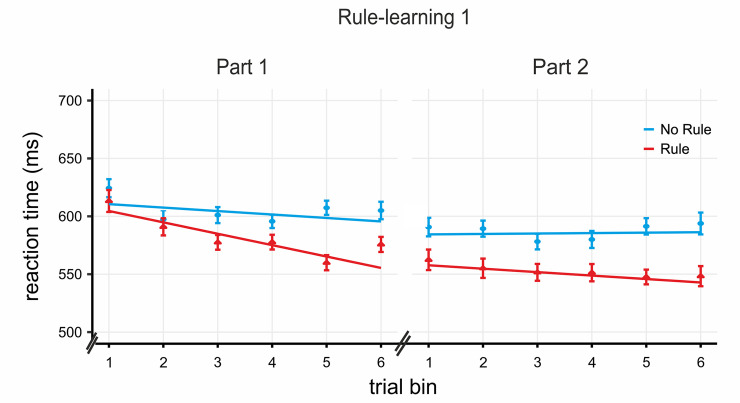
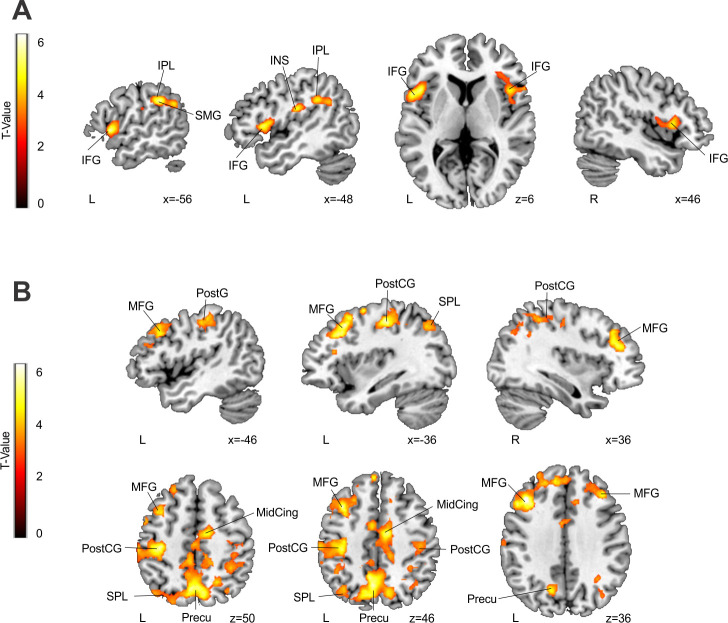
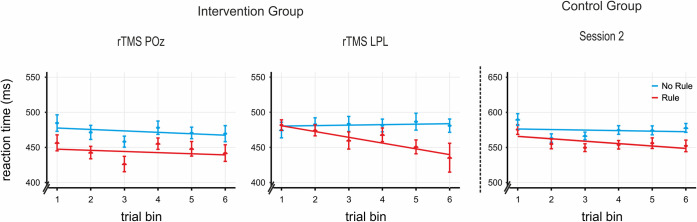
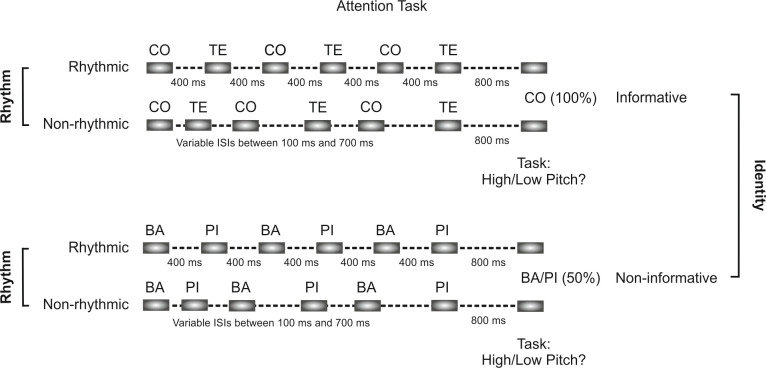
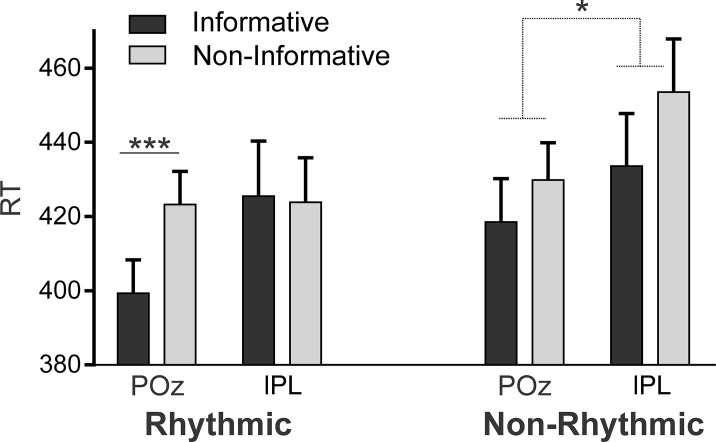
A crucial aspect when learning a language is discovering the rules that govern how words are combined in order to convey meanings. Because rules are characterized by sequential co-occurrences between elements (e.g., "These cupcakes are unbelievable"), tracking the statistical relationships between these elements is fundamental. However, purely bottom-up statistical learning alone cannot fully account for the ability to create abstract rule representations that can be generalized, a paramount requirement of linguistic rules. Here, we provide evidence that, after the statistical relations between words have been extracted, the engagement of goal-directed attention is key to enable rule generalization. Incidental learning performance during a rule-learning task on an artificial language revealed a progressive shift from statistical learning to goal-directed attention. In addition, and consistent with the recruitment of attention, functional MRI (fMRI) analyses of late learning stages showed left parietal activity within a broad bilateral dorsal frontoparietal network. Critically, repetitive transcranial magnetic stimulation (rTMS) on participants' peak of activation within the left parietal cortex impaired their ability to generalize learned rules to a structurally analogous new language. No stimulation or rTMS on a nonrelevant brain region did not have the same interfering effect on generalization. Performance on an additional attentional task showed that this rTMS on the parietal site hindered participants' ability to integrate "what" (stimulus identity) and "when" (stimulus timing) information about an expected target. The present findings suggest that learning rules from speech is a two-stage process: following statistical learning, goal-directed attention-involving left parietal regions-integrates "what" and "when" stimulus information to facilitate rapid rule generalization.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Smith LB. Learning How to Learn Words: An Associative Crane. In: Golinkoff RM, Hirsh-Pasek K, editors. Becoming a Word Learner: A Debate on Lexical Acquisition. Oxford, UK: Oxford University Press; 2000. p. 51–80. 10.1093/acprof:oso/9780195130324.003.003 - DOI
-
- Saffran JR, Wilson DP. From syllables to syntax: Multilevel statistical learning by 12-month-old infants. Infancy. 2003;4: 273–284. 10.1207/S15327078IN0402_07 - DOI
