

Transfer learning enables prediction of CYP2D6 haplotype function
- PMID: 33137098
- PMCID: PMC7660895
- DOI: 10.1371/journal.pcbi.1008399
Transfer learning enables prediction of CYP2D6 haplotype function
Abstract
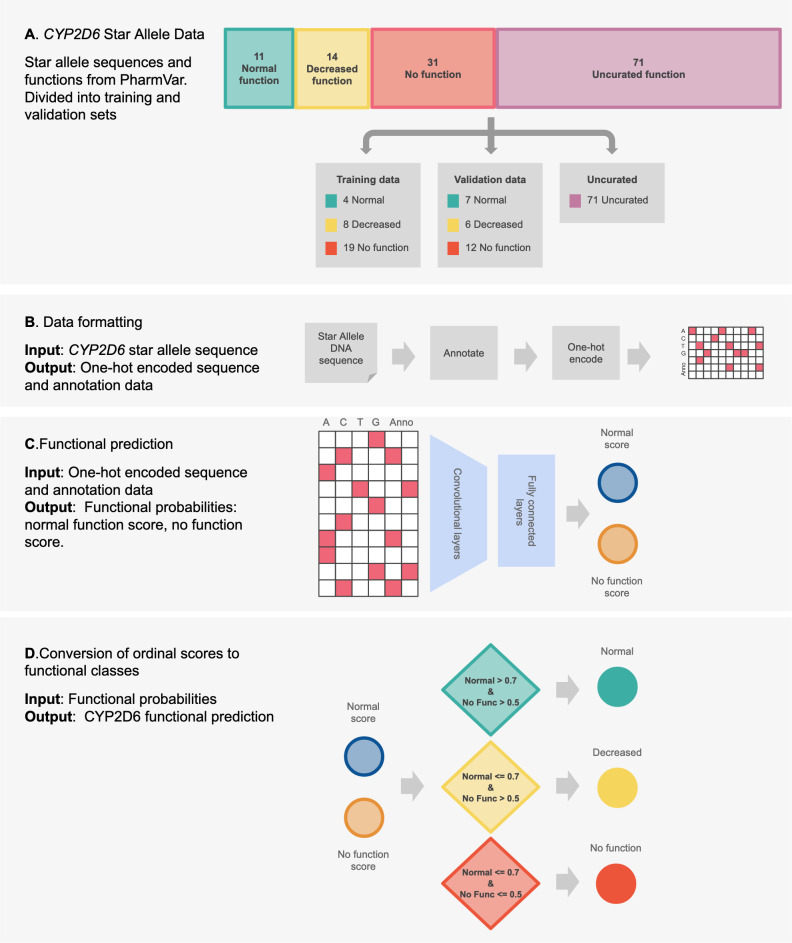
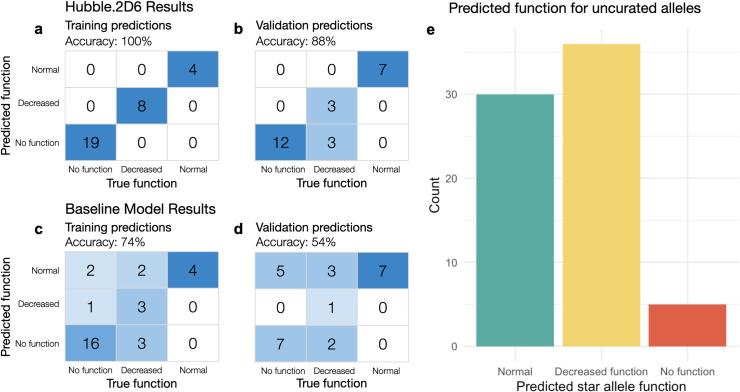
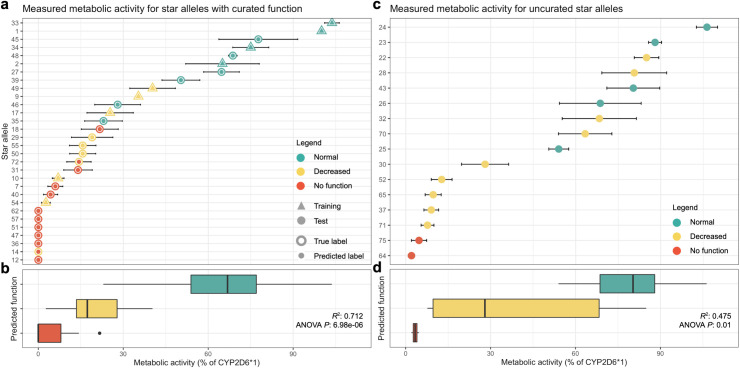
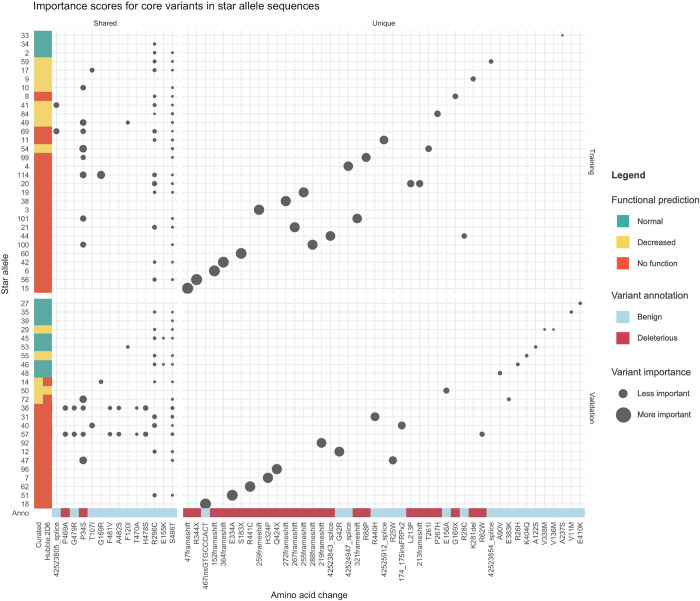
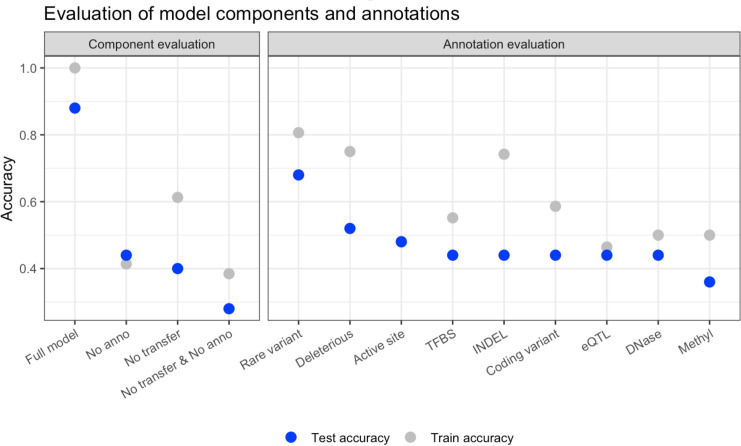
Cytochrome P450 2D6 (CYP2D6) is a highly polymorphic gene whose protein product metabolizes more than 20% of clinically used drugs. Genetic variations in CYP2D6 are responsible for interindividual heterogeneity in drug response that can lead to drug toxicity and ineffective treatment, making CYP2D6 one of the most important pharmacogenes. Prediction of CYP2D6 phenotype relies on curation of literature-derived functional studies to assign a functional status to CYP2D6 haplotypes. As the number of large-scale sequencing efforts grows, new haplotypes continue to be discovered, and assignment of function is challenging to maintain. To address this challenge, we have trained a convolutional neural network to predict functional status of CYP2D6 haplotypes, called Hubble.2D6. Hubble.2D6 predicts haplotype function from sequence data and was trained using two pre-training steps with a combination of real and simulated data. We find that Hubble.2D6 predicts CYP2D6 haplotype functional status with 88% accuracy in a held-out test set and explains 47.5% of the variance in in vitro functional data among star alleles with unknown function. Hubble.2D6 may be a useful tool for assigning function to haplotypes with uncurated function, and used for screening individuals who are at risk of being poor metabolizers.
Conflict of interest statement
The authors of this manuscript have the following competing interests: RBA is a stockholder in Personalis.com and 23andme.com.
Figures
Similar articles
-
Interrogation of CYP2D6 Structural Variant Alleles Improves the Correlation Between CYP2D6 Genotype and CYP2D6-Mediated Metabolic Activity.Clin Transl Sci. 2020 Jan;13(1):147-156. doi: 10.1111/cts.12695. Epub 2019 Oct 25. Clin Transl Sci. 2020. PMID: 31536170 Free PMC article.
-
Polymorphism of human cytochrome P450 2D6 and its clinical significance: Part I.Clin Pharmacokinet. 2009;48(11):689-723. doi: 10.2165/11318030-000000000-00000. Clin Pharmacokinet. 2009. PMID: 19817501 Review.
-
Assessment of the predictive power of genotypes for the in-vivo catalytic function of CYP2D6 in a German population.Pharmacogenetics. 1998 Feb;8(1):15-26. doi: 10.1097/00008571-199802000-00003. Pharmacogenetics. 1998. PMID: 9511177
-
Cytochrome P450 2D6: overview and update on pharmacology, genetics, biochemistry.Naunyn Schmiedebergs Arch Pharmacol. 2004 Jan;369(1):23-37. doi: 10.1007/s00210-003-0832-2. Epub 2003 Nov 15. Naunyn Schmiedebergs Arch Pharmacol. 2004. PMID: 14618296 Review.
-
Polymorphism of human cytochrome P450 2D6 and its clinical significance: part II.Clin Pharmacokinet. 2009;48(12):761-804. doi: 10.2165/11318070-000000000-00000. Clin Pharmacokinet. 2009. PMID: 19902987
Cited by
-
Targeted haplotyping in pharmacogenomics using Oxford Nanopore Technologies' adaptive sampling.Front Pharmacol. 2023 Nov 13;14:1286764. doi: 10.3389/fphar.2023.1286764. eCollection 2023. Front Pharmacol. 2023. PMID: 38026945 Free PMC article.
-
Review on Databases and Bioinformatic Approaches on Pharmacogenomics of Adverse Drug Reactions.Pharmgenomics Pers Med. 2021 Jan 13;14:61-75. doi: 10.2147/PGPM.S290781. eCollection 2021. Pharmgenomics Pers Med. 2021. PMID: 33469342 Free PMC article. Review.
-
Comprehensive Allele Genotyping in Critical Pharmacogenes Reduces Residual Clinical Risk in Diverse Populations.Clin Pharmacol Ther. 2021 Sep;110(3):759-767. doi: 10.1002/cpt.2279. Epub 2021 Jun 7. Clin Pharmacol Ther. 2021. PMID: 33930192 Free PMC article.
-
Exploiting deep transfer learning for the prediction of functional non-coding variants using genomic sequence.Bioinformatics. 2022 Jun 13;38(12):3164-3172. doi: 10.1093/bioinformatics/btac214. Bioinformatics. 2022. PMID: 35389435 Free PMC article.
-
From gene to dose: Long-read sequencing and *-allele tools to refine phenotype predictions of CYP2C19.Front Pharmacol. 2023 Mar 1;14:1076574. doi: 10.3389/fphar.2023.1076574. eCollection 2023. Front Pharmacol. 2023. PMID: 36937863 Free PMC article.
References
-
- Saravanakumar A, Sadighi A, Ryu R, Akhlaghi F. Physicochemical Properties, Biotransformation, and Transport Pathways of Established and Newly Approved Medications: A Systematic Review of the Top 200 Most Prescribed Drugs vs. the FDA-Approved Drugs Between 2005 and 2016. Clin Pharmacokinet. 2019. 10.1007/s40262-019-00750-8 - DOI - PMC - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
