

To pool or not to pool: Can we ignore cross-trial variability in FMRI?
- PMID: 33181352
- PMCID: PMC7861143
- DOI: 10.1016/j.neuroimage.2020.117496
To pool or not to pool: Can we ignore cross-trial variability in FMRI?
Abstract
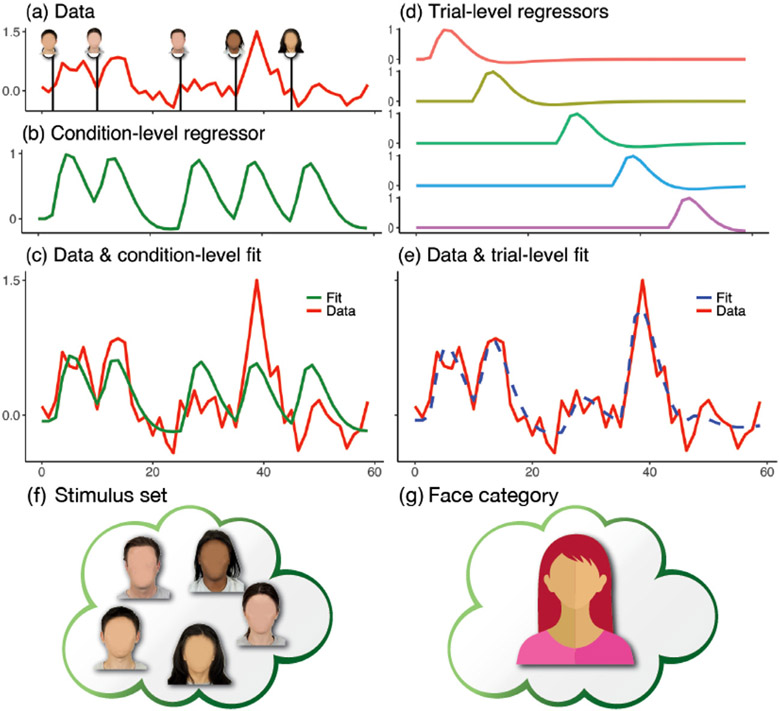
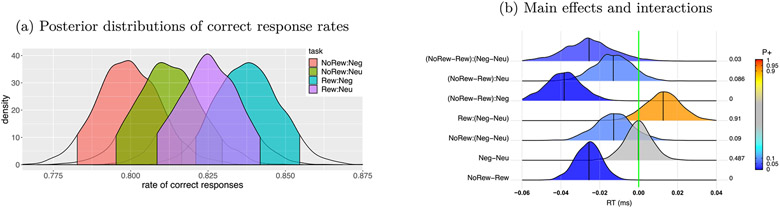
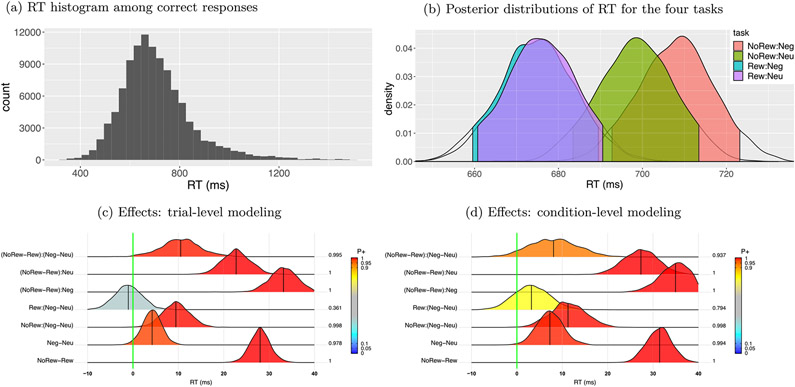
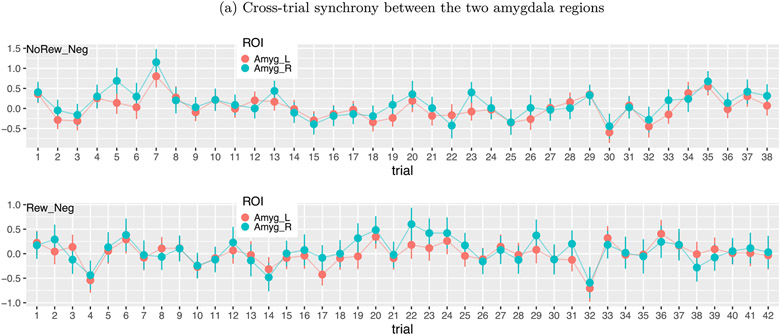
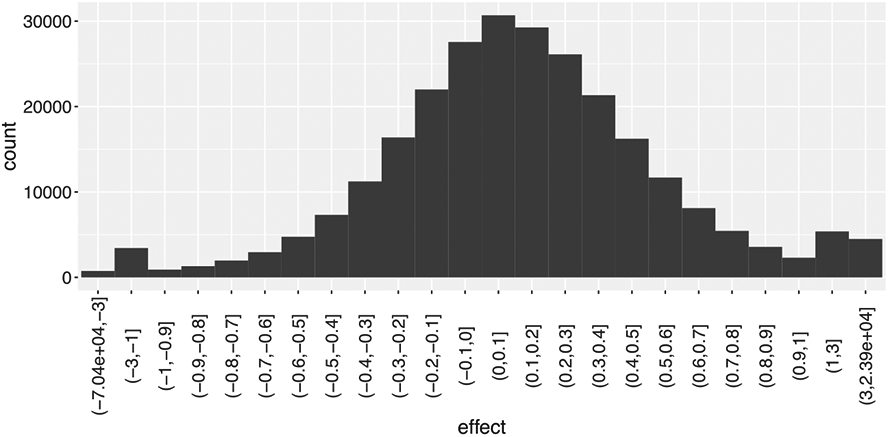
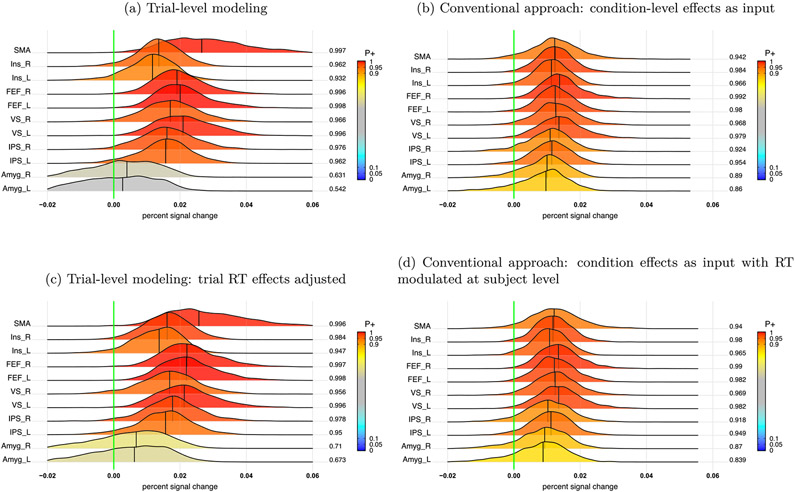
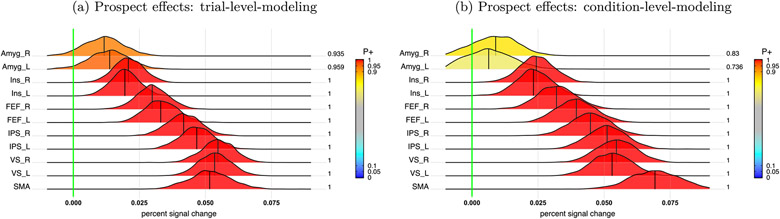
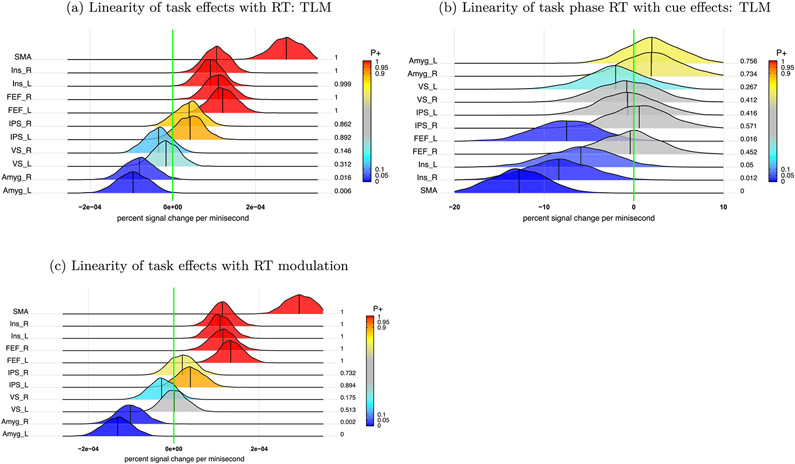
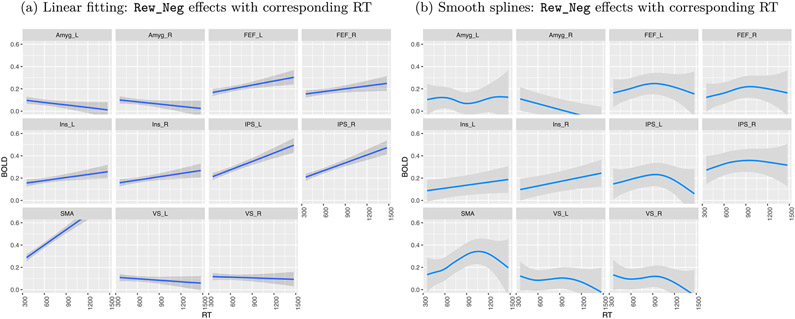
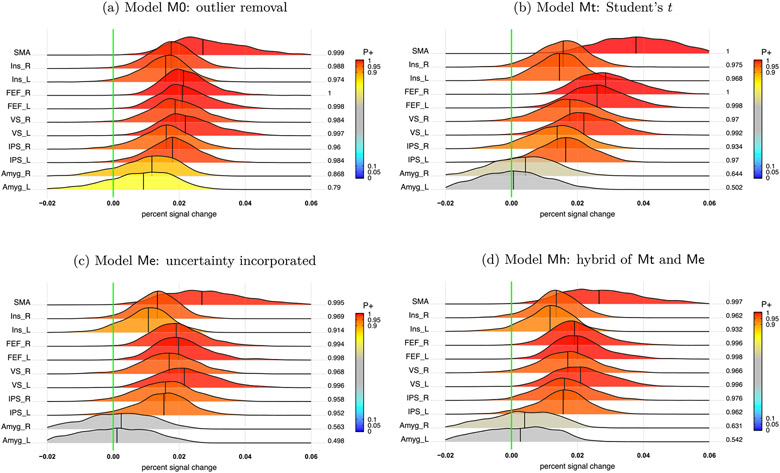
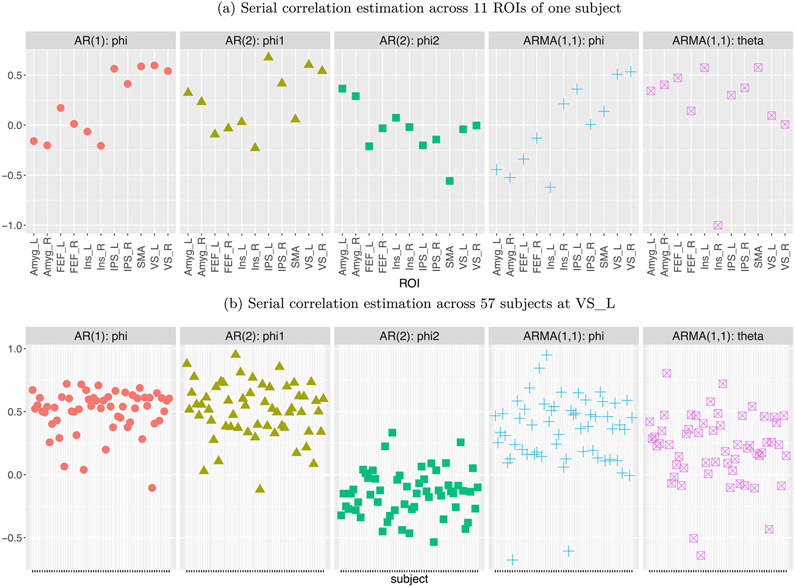
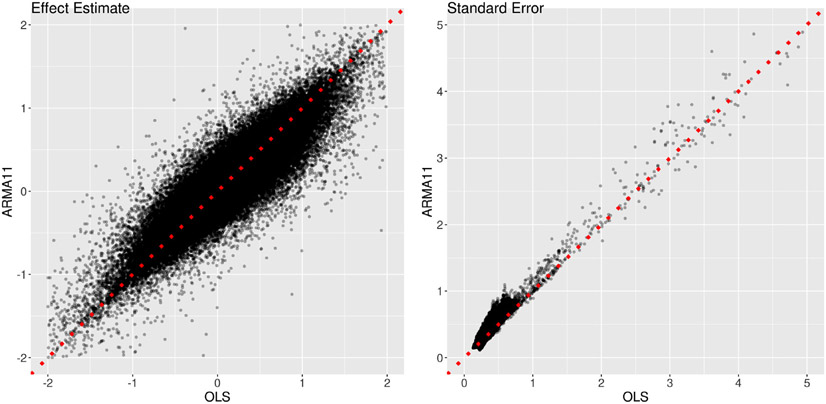
In this work, we investigate the importance of explicitly accounting for cross-trial variability in neuroimaging data analysis. To attempt to obtain reliable estimates in a task-based experiment, each condition is usually repeated across many trials. The investigator may be interested in (a) condition-level effects, (b) trial-level effects, or (c) the association of trial-level effects with the corresponding behavior data. The typical strategy for condition-level modeling is to create one regressor per condition at the subject level with the underlying assumption that responses do not change across trials. In this methodology of complete pooling, all cross-trial variability is ignored and dismissed as random noise that is swept under the rug of model residuals. Unfortunately, this framework invalidates the generalizability from the confine of specific trials (e.g., particular faces) to the associated stimulus category ("face"), and may inflate the statistical evidence when the trial sample size is not large enough. Here we propose an adaptive and computationally tractable framework that meshes well with the current two-level pipeline and explicitly accounts for trial-by-trial variability. The trial-level effects are first estimated per subject through no pooling. To allow generalizing beyond the particular stimulus set employed, the cross-trial variability is modeled at the population level through partial pooling in a multilevel model, which permits accurate effect estimation and characterization. Alternatively, trial-level estimates can be used to investigate, for example, brain-behavior associations or correlations between brain regions. Furthermore, our approach allows appropriate accounting for serial correlation, handling outliers, adapting to data skew, and capturing nonlinear brain-behavior relationships. By applying a Bayesian multilevel model framework at the level of regions of interest to an experimental dataset, we show how multiple testing can be addressed and full results reported without arbitrary dichotomization. Our approach revealed important differences compared to the conventional method at the condition level, including how the latter can distort effect magnitude and precision. Notably, in some cases our approach led to increased statistical sensitivity. In summary, our proposed framework provides an effective strategy to capture trial-by-trial responses that should be of interest to a wide community of experimentalists.
Copyright © 2020. Published by Elsevier Inc.
Figures
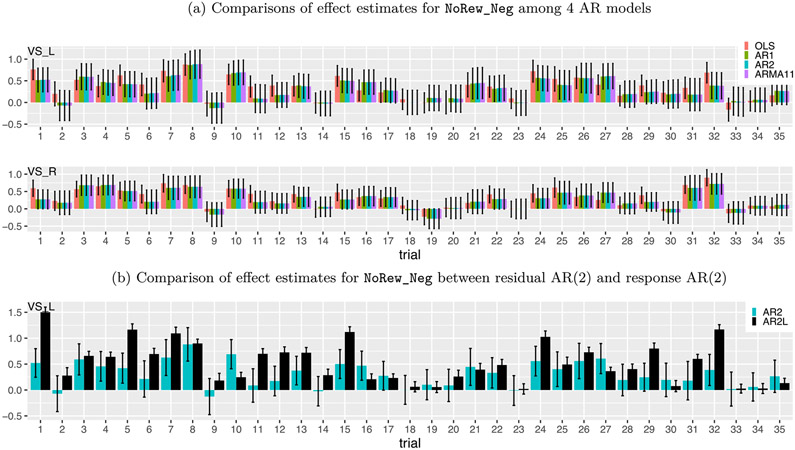
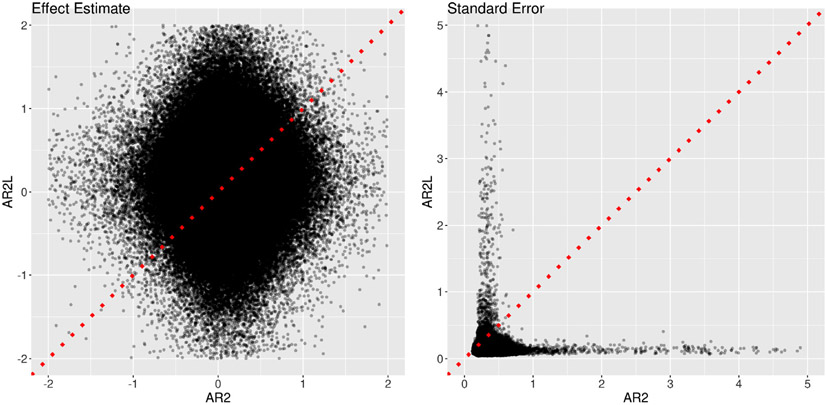
References
-
- Achen CH, 2001. Why lagged dependent variables can suppress the explanatory power of other independent variables Annual Meeting of the Political Methodology Section of the American Political Science Association. UCLA; July 20–22, 2000.
-
- Baayen H, Davidson DJ, Bates DM, 2008. Mixed-effects modeling with crossed random effects for subjects and WES. J. Memory Lang. 59 (4), 390–412.
-
- Bellemare MF, Masaki T, Pepinsky TB, 2017. Lagged explanatory variables and the estimation of causal effect. J. Polit 79 (3), 949–963.
-
- Bullmore E, Brammer M, Williams SC, Rabe-Hesketh S, Janot N, David A, Mellers J, Howard R, Sham P, 1996. Statistical methods of estimation and inference for functional MR image analysis. Magn. Reson. Med 35, 261–277. - PubMed
-
- Bürkner PC, 2018. Advanced Bayesian multilevel modeling with the r package BRMS. R J. 10 (1), 395–411.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
