

Individual differences among deep neural network models
- PMID: 33184286
- PMCID: PMC7665054
- DOI: 10.1038/s41467-020-19632-w
Individual differences among deep neural network models
Abstract
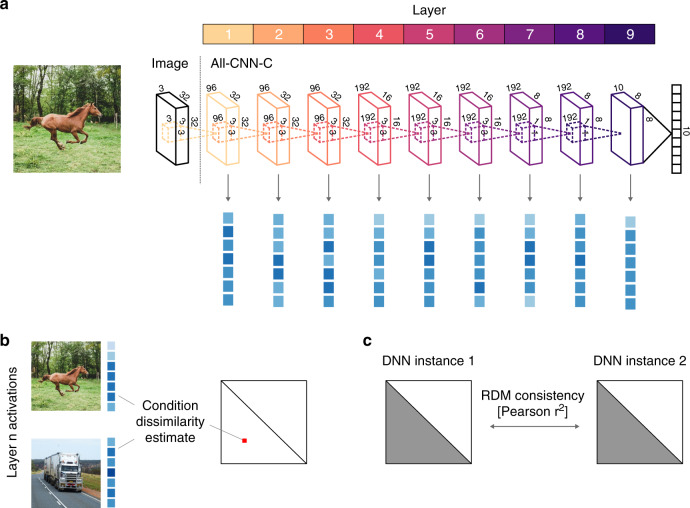
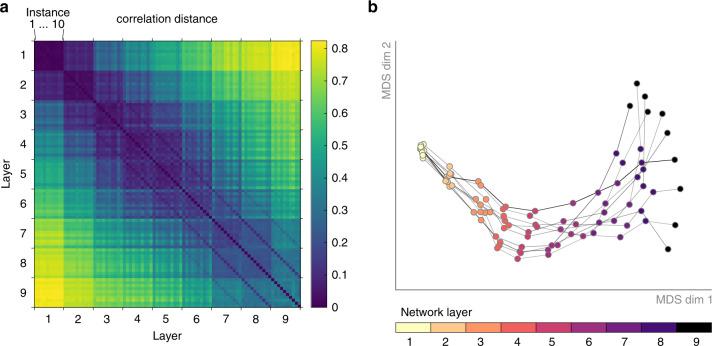
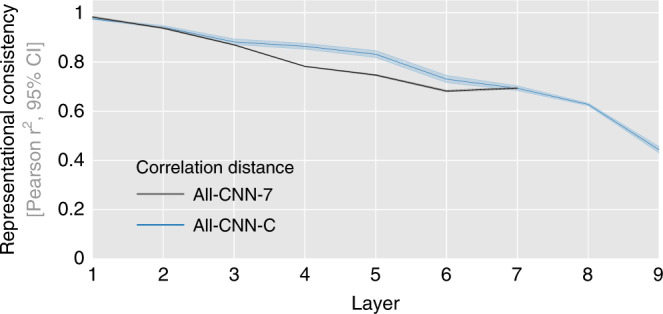
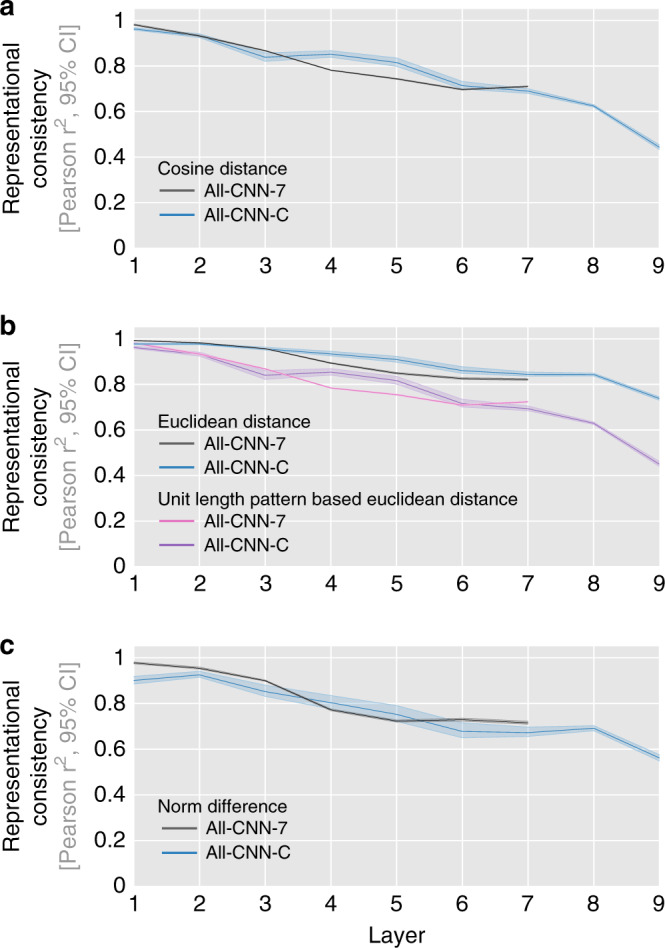
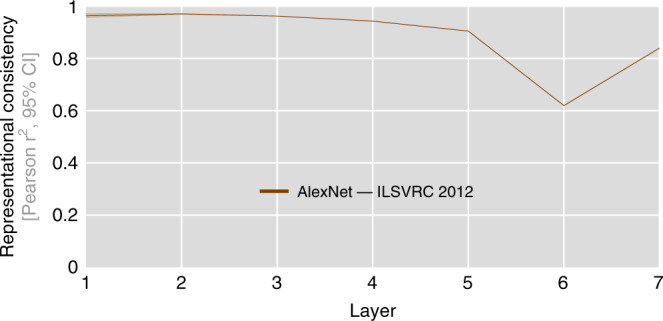
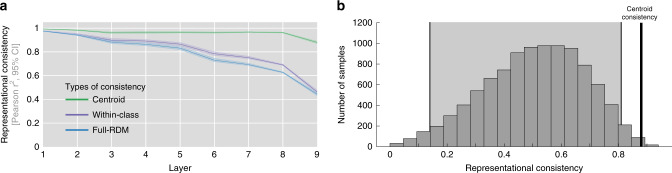
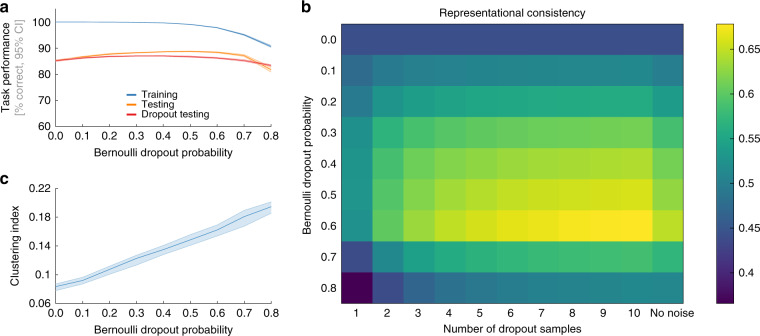
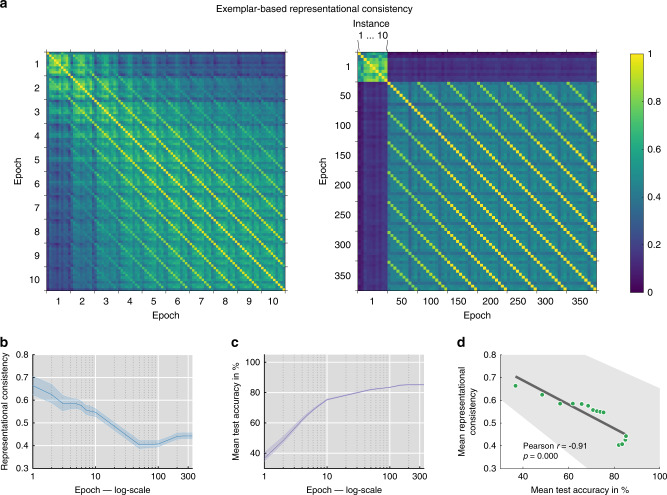
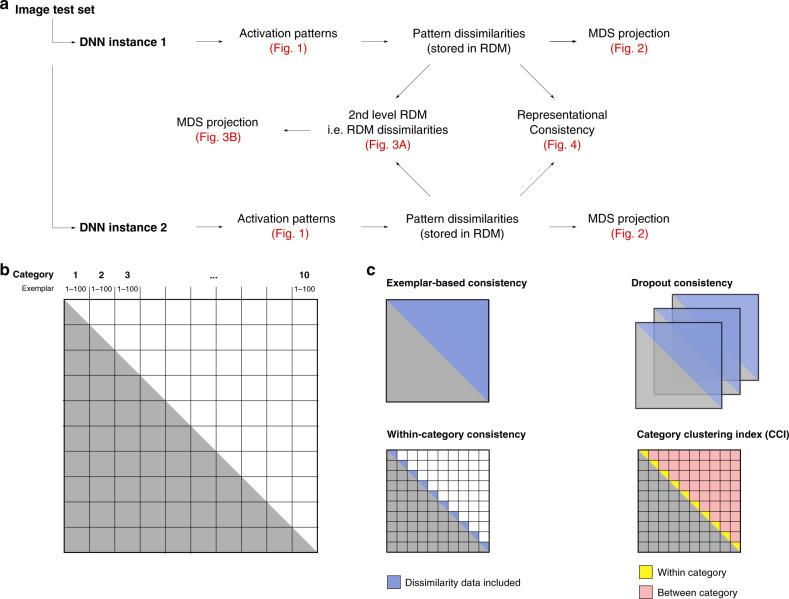
Deep neural networks (DNNs) excel at visual recognition tasks and are increasingly used as a modeling framework for neural computations in the primate brain. Just like individual brains, each DNN has a unique connectivity and representational profile. Here, we investigate individual differences among DNN instances that arise from varying only the random initialization of the network weights. Using tools typically employed in systems neuroscience, we show that this minimal change in initial conditions prior to training leads to substantial differences in intermediate and higher-level network representations despite similar network-level classification performance. We locate the origins of the effects in an under-constrained alignment of category exemplars, rather than misaligned category centroids. These results call into question the common practice of using single networks to derive insights into neural information processing and rather suggest that computational neuroscientists working with DNNs may need to base their inferences on groups of multiple network instances.
Conflict of interest statement
The authors declare no competing interests.
Figures
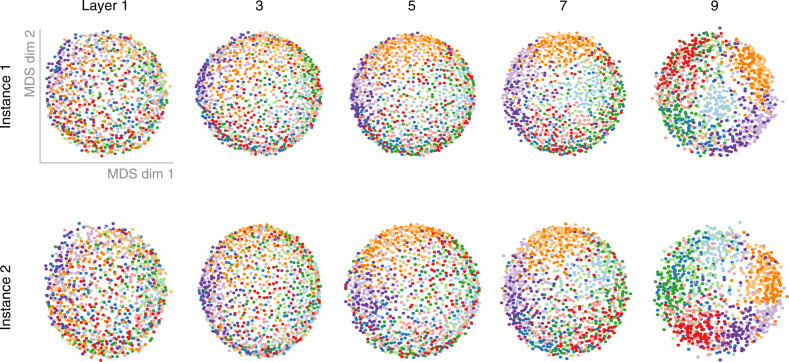
Similar articles
-
Manipulating and measuring variation in deep neural network (DNN) representations of objects.Cognition. 2024 Nov;252:105920. doi: 10.1016/j.cognition.2024.105920. Epub 2024 Aug 19. Cognition. 2024. PMID: 39163818
-
DNNBrain: A Unifying Toolbox for Mapping Deep Neural Networks and Brains.Front Comput Neurosci. 2020 Nov 30;14:580632. doi: 10.3389/fncom.2020.580632. eCollection 2020. Front Comput Neurosci. 2020. PMID: 33328946 Free PMC article.
-
Which deep learning model can best explain object representations of within-category exemplars?J Vis. 2021 Sep 1;21(10):12. doi: 10.1167/jov.21.10.12. J Vis. 2021. PMID: 34520508 Free PMC article.
-
Analyzing biological and artificial neural networks: challenges with opportunities for synergy?Curr Opin Neurobiol. 2019 Apr;55:55-64. doi: 10.1016/j.conb.2019.01.007. Epub 2019 Feb 19. Curr Opin Neurobiol. 2019. PMID: 30785004 Review.
-
Are Deep Neural Networks Adequate Behavioral Models of Human Visual Perception?Annu Rev Vis Sci. 2023 Sep 15;9:501-524. doi: 10.1146/annurev-vision-120522-031739. Epub 2023 Mar 31. Annu Rev Vis Sci. 2023. PMID: 37001509 Review.
Cited by
-
Model metamers reveal divergent invariances between biological and artificial neural networks.Nat Neurosci. 2023 Nov;26(11):2017-2034. doi: 10.1038/s41593-023-01442-0. Epub 2023 Oct 16. Nat Neurosci. 2023. PMID: 37845543 Free PMC article.
-
The neuroconnectionist research programme.Nat Rev Neurosci. 2023 Jul;24(7):431-450. doi: 10.1038/s41583-023-00705-w. Epub 2023 May 30. Nat Rev Neurosci. 2023. PMID: 37253949 Review.
-
The topology and geometry of neural representations.Proc Natl Acad Sci U S A. 2024 Oct 15;121(42):e2317881121. doi: 10.1073/pnas.2317881121. Epub 2024 Oct 7. Proc Natl Acad Sci U S A. 2024. PMID: 39374397 Free PMC article.
-
Neural representations of the perception of handwritten digits and visual objects from a convolutional neural network compared to humans.Hum Brain Mapp. 2023 Apr 1;44(5):2018-2038. doi: 10.1002/hbm.26189. Epub 2023 Jan 13. Hum Brain Mapp. 2023. PMID: 36637109 Free PMC article.
-
The Presence of Background Noise Extends the Competitor Space in Native and Non-Native Spoken-Word Recognition: Insights from Computational Modeling.Cogn Sci. 2022 Feb;46(2):e13110. doi: 10.1111/cogs.13110. Cogn Sci. 2022. PMID: 35188686 Free PMC article.
References
-
- Schrimpf, M. et al. Brain-score: which artificial neural network for object recognition is most brain-like? Preprint at https://www.biorxiv.org/content/10.1101/407007v2bioRxiv (2018). - DOI
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
