

Patterns, Profiles, and Parsimony: Dissecting Transcriptional Signatures From Minimal Single-Cell RNA-Seq Output With SALSA
- PMID: 33193599
- PMCID: PMC7586319
- DOI: 10.3389/fgene.2020.511286
Patterns, Profiles, and Parsimony: Dissecting Transcriptional Signatures From Minimal Single-Cell RNA-Seq Output With SALSA
Abstract
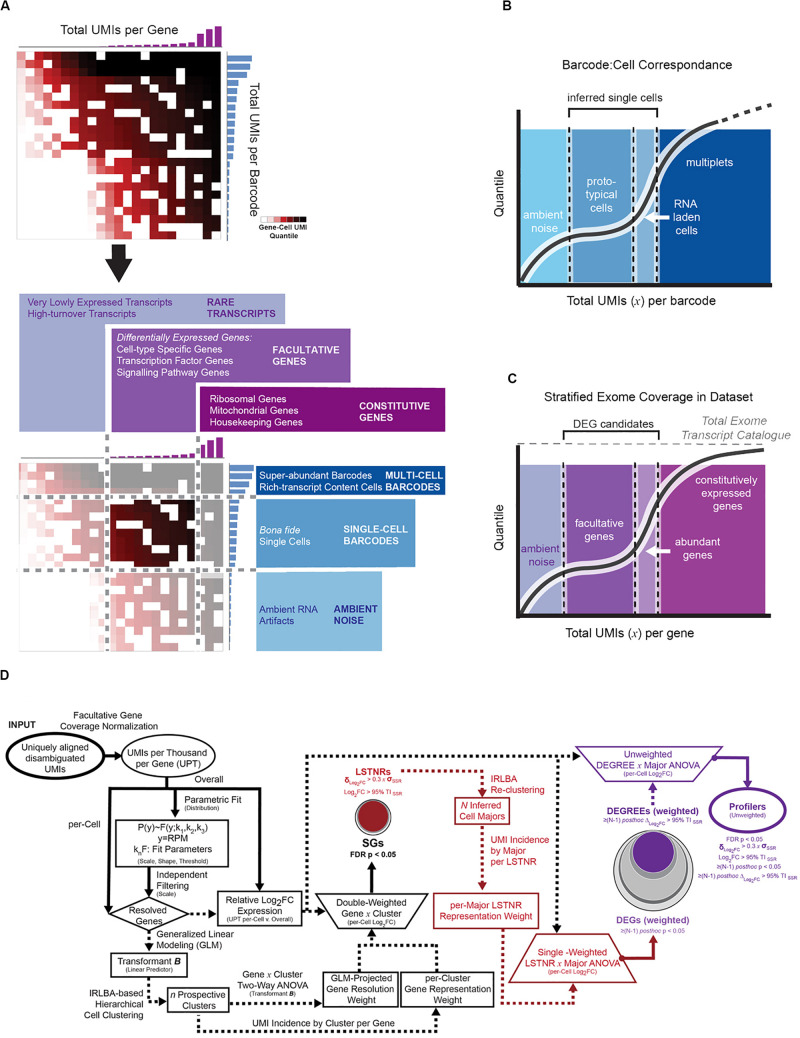
Single-cell RNA sequencing (scRNA-seq) technologies have precipitated the development of bioinformatic tools to reconstruct cell lineage specification and differentiation processes with single-cell precision. However, current start-up costs and recommended data volumes for statistical analysis remain prohibitively expensive, preventing scRNA-seq technologies from becoming mainstream. Here, we introduce single-cell amalgamation by latent semantic analysis (SALSA), a versatile workflow that combines measurement reliability metrics with latent variable extraction to infer robust expression profiles from ultra-sparse sc-RNAseq data. SALSA uses a matrix focusing approach that starts by identifying facultative genes with expression levels greater than experimental measurement precision and ends with cell clustering based on a minimal set of Profiler genes, each one a putative biomarker of cluster-specific expression profiles. To benchmark how SALSA performs in experimental settings, we used the publicly available 10X Genomics PBMC 3K dataset, a pre-curated silver standard from human frozen peripheral blood comprising 2,700 single-cell barcodes, and identified 7 major cell groups matching transcriptional profiles of peripheral blood cell types and driven agnostically by < 500 Profiler genes. Finally, we demonstrate successful implementation of SALSA in a replicative scRNA-seq scenario by using previously published DropSeq data from a multi-batch mouse retina experimental design, thereby identifying 10 transcriptionally distinct cell types from > 64,000 single cells across 7 independent biological replicates based on < 630 Profiler genes. With these results, SALSA demonstrates that robust pattern detection from scRNA-seq expression matrices only requires a fraction of the accrued data, suggesting that single-cell sequencing technologies can become affordable and widespread if meant as hypothesis-generation tools to extract large-scale differential expression effects.
Keywords: NGS; RNA; biomarker discovery and validation; heterogeneity; hypothesis generation; reproducibility; scRNA-seq; single cells; sparsity; transcriptomics analysis.
Copyright © 2020 Lozoya, McClelland, Papas, Li and Yao.
Figures






References
-
- Aitkin M., Clayton D. (1980). The fitting of exponential, weibull and extreme value distributions to complex censored survival data using GLIM. J. R. Statist. Soc. Ser. C 29 156–163. 10.2307/2986301 - DOI
-
- Baglama J., Reichel L. (2005). Augmented implicitly restarted Lanczos bidiagonalization methods. SIAM J. Sci. Comput. 27 19–42. 10.1137/04060593x - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources