

Hidden Stratification Causes Clinically Meaningful Failures in Machine Learning for Medical Imaging
- PMID: 33196064
- PMCID: PMC7665161
- DOI: 10.1145/3368555.3384468
Hidden Stratification Causes Clinically Meaningful Failures in Machine Learning for Medical Imaging
Abstract
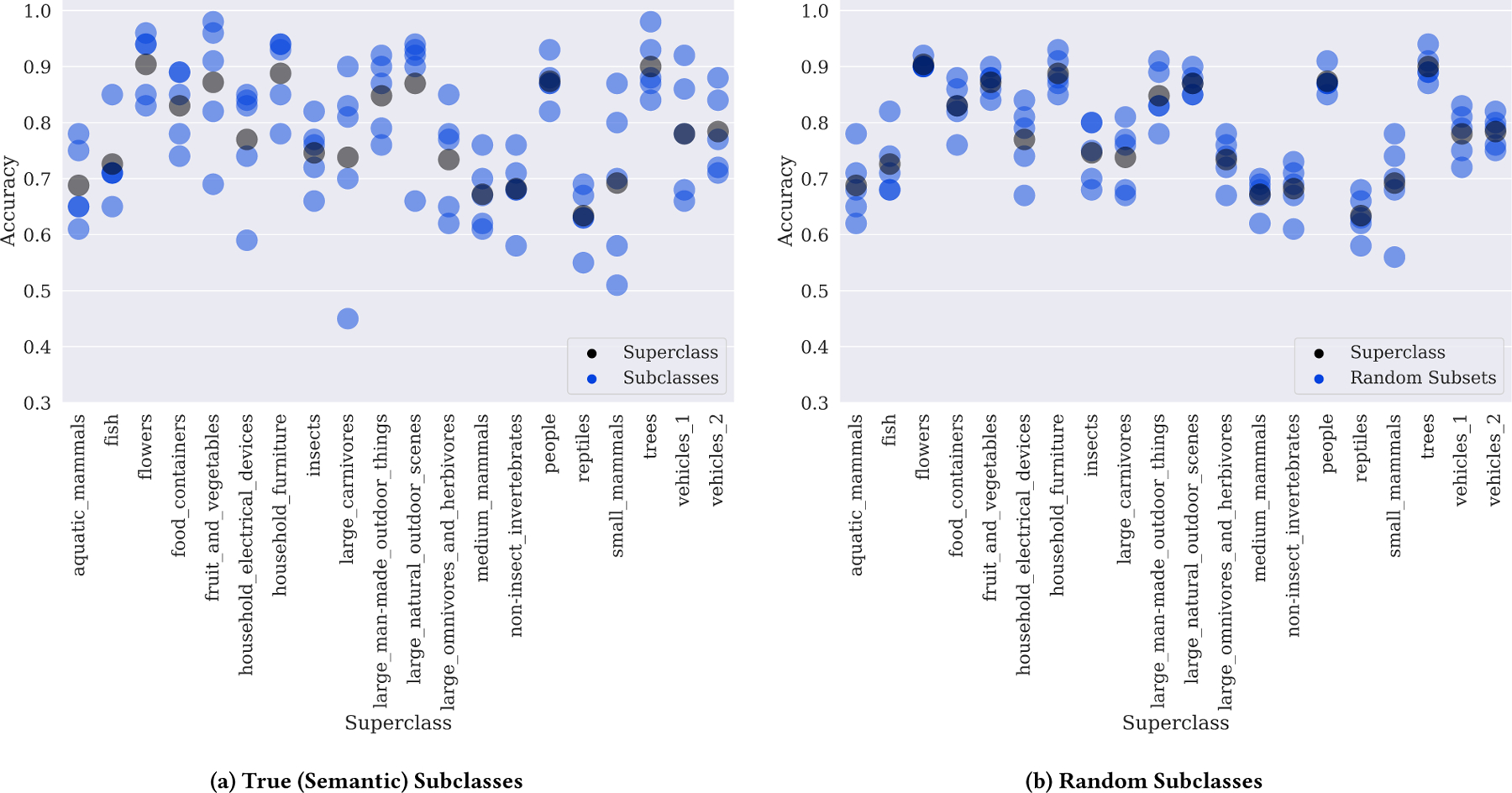
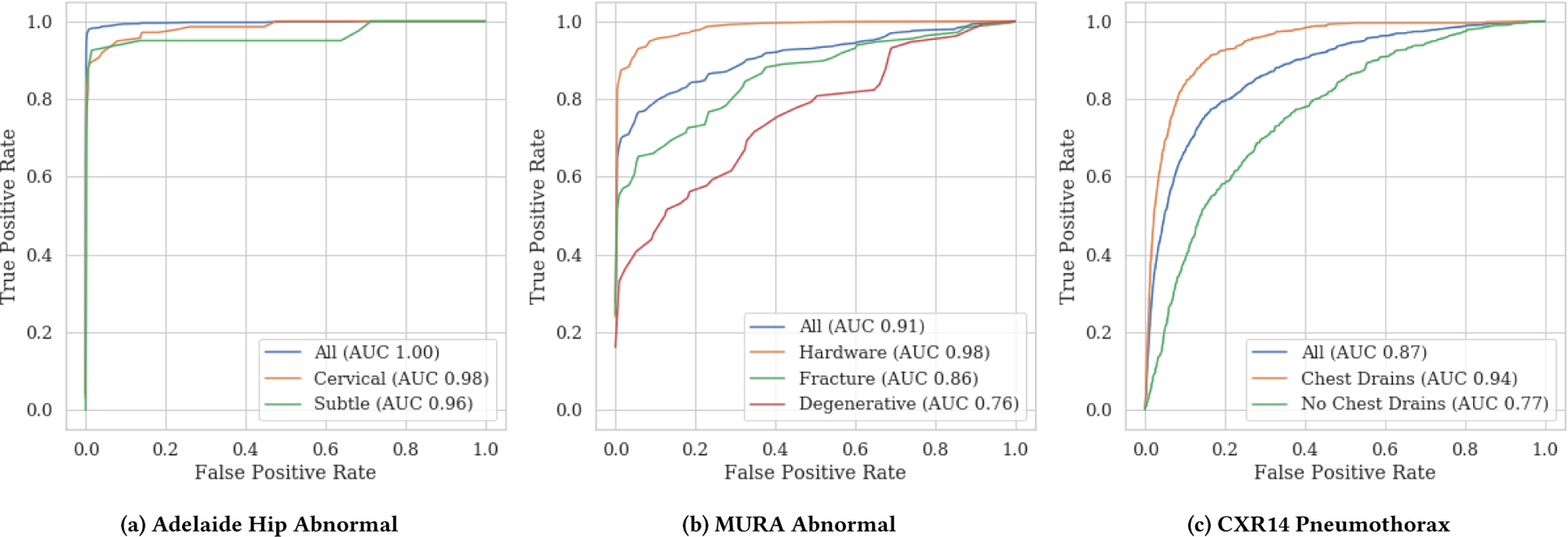
Machine learning models for medical image analysis often suffer from poor performance on important subsets of a population that are not identified during training or testing. For example, overall performance of a cancer detection model may be high, but the model may still consistently miss a rare but aggressive cancer subtype. We refer to this problem as hidden stratification, and observe that it results from incompletely describing the meaningful variation in a dataset. While hidden stratification can substantially reduce the clinical efficacy of machine learning models, its effects remain difficult to measure. In this work, we assess the utility of several possible techniques for measuring hidden stratification effects, and characterize these effects both via synthetic experiments on the CIFAR-100 benchmark dataset and on multiple real-world medical imaging datasets. Using these measurement techniques, we find evidence that hidden stratification can occur in unidentified imaging subsets with low prevalence, low label quality, subtle distinguishing features, or spurious correlates, and that it can result in relative performance differences of over 20% on clinically important subsets. Finally, we discuss the clinical implications of our findings, and suggest that evaluation of hidden stratification should be a critical component of any machine learning deployment in medical imaging.
Keywords: Computing methodologies → Machine learning; convolutional neural networks; hidden stratification; machine learning.
Figures
References
-
- Badgeley Marcus A, Zech John R, Oakden-Rayner Luke, Glicksberg Benjamin S, Liu Manway, Gale William, McConnell Michael V, Percha Bethany, Snyder Thomas M, and Dudley Joel T. 2019 Deep learning predicts hip fracture using confounding patient and healthcare variables. NPJ Digit Med 2 (April 2019), 31. - PMC - PubMed
-
- Bien Nicholas, Rajpurkar Pranav, Robyn L Ball Jeremy Irvin, Park Allison, Jones Erik, Bereket Michael, Patel Bhavik N, Yeom Kristen W, Shpanskaya Katie, Halabi Safwan, Zucker Evan, Fanton Gary, Amanatullah Derek F, Beaulieu Christopher F, Riley Geoffrey M, Stewart Russell J, Blankenberg Francis G, Larson David B, Jones Ricky H, Langlotz Curtis P, Ng Andrew Y, and Lungren Matthew P. 2018 Deep-learning-assisted diagnosis for knee magnetic resonance imaging: Development and retrospective validation of MRNet. PLoS Med 15, 11 (November 2018), e1002699. - PMC - PubMed
-
- Buda Mateusz, Maki Atsuto, and Mazurowski Maciej A. 2018 A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw 106 (October 2018), 249–259. - PubMed
-
- Caliński Tadeusz and Jerzy Harabasz. 1974 A dendrite method for cluster analysis. Communications in Statistics-Theory and Methods 3, 1 (1974), 1–27.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources