

BRENDA, the ELIXIR core data resource in 2021: new developments and updates
- PMID: 33211880
- PMCID: PMC7779020
- DOI: 10.1093/nar/gkaa1025
BRENDA, the ELIXIR core data resource in 2021: new developments and updates
Abstract
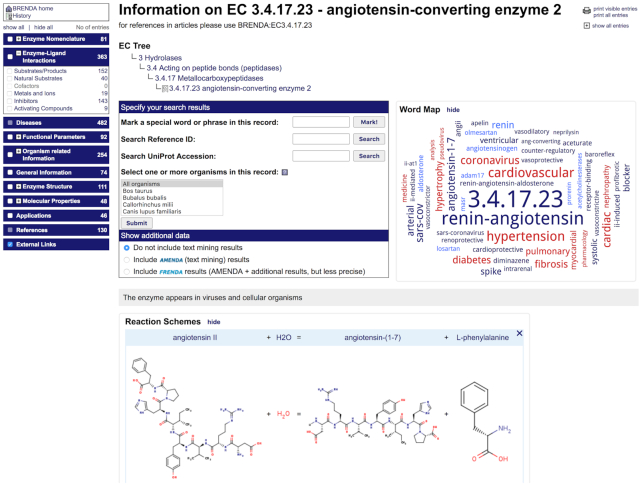
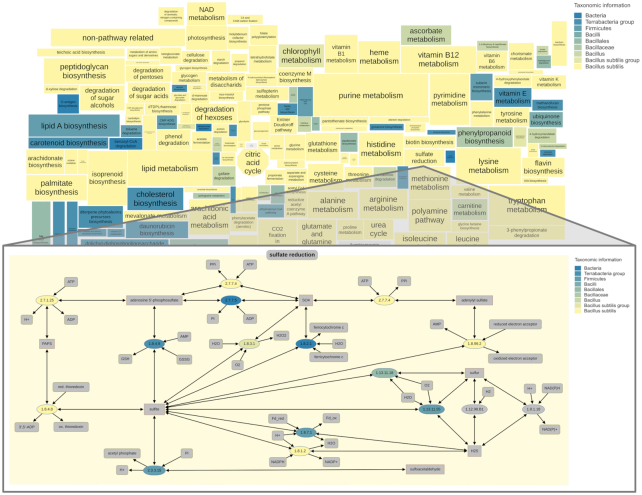
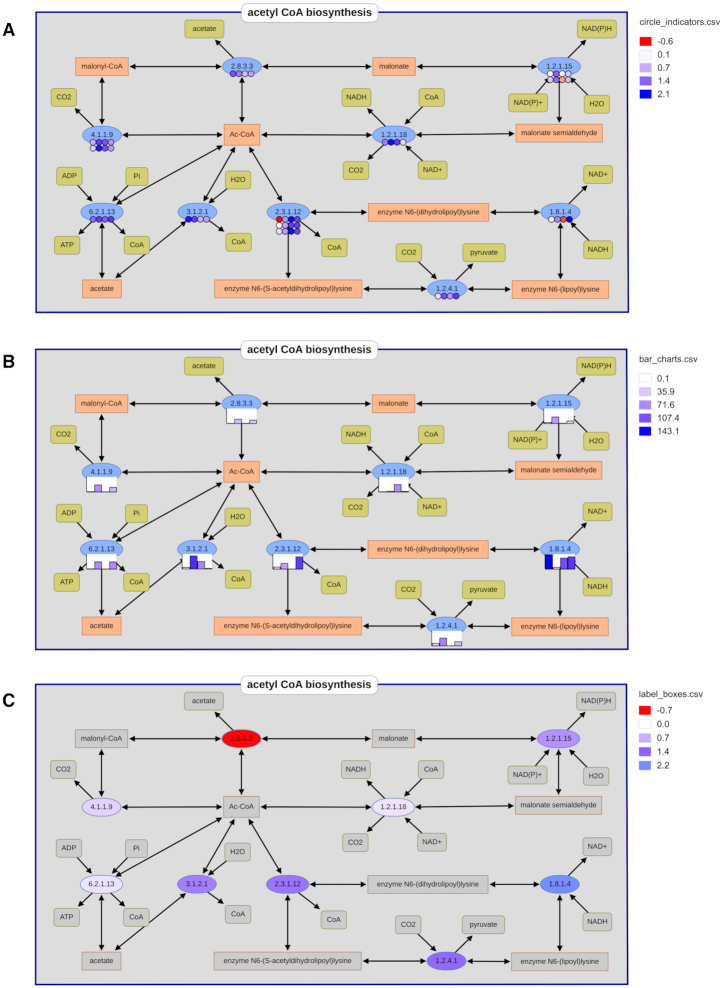
The BRENDA enzyme database (https://www.brenda-enzymes.org), established in 1987, has evolved into the main collection of functional enzyme and metabolism data. In 2018, BRENDA was selected as an ELIXIR Core Data Resource. BRENDA provides reliable data, continuous curation and updates of classified enzymes, and the integration of newly discovered enzymes. The main part contains >5 million data for ∼90 000 enzymes from ∼13 000 organisms, manually extracted from ∼157 000 primary literature references, combined with information of text and data mining, data integration, and prediction algorithms. Supplements comprise disease-related data, protein sequences, 3D structures, genome annotations, ligand information, taxonomic, bibliographic, and kinetic data. BRENDA offers an easy access to enzyme information from quick to advanced searches, text- and structured-based queries for enzyme-ligand interactions, word maps, and visualization of enzyme data. The BRENDA Pathway Maps are completely revised and updated for an enhanced interactive and intuitive usability. The new design of the Enzyme Summary Page provides an improved access to each individual enzyme. A new protein structure 3D viewer was integrated. The prediction of the intracellular localization of eukaryotic enzymes has been implemented. The new EnzymeDetector combines BRENDA enzyme annotations with protein and genome databases for the detection of eukaryotic and prokaryotic enzymes.
© The Author(s) 2020. Published by Oxford University Press on behalf of Nucleic Acids Research.
Figures




References
-
- Schomburg D., Schomburg I.. Springer Handbook of Enzymes. 2001-2009; 2nd ednHeidelberg: Springer.
-
- Schomburg I., Chang A., Placzek S., Söhngen C., Rother M., Lang M., Munaretto C., Ulas S., Stelzer M., Grote A. et al. .. BRENDA in 2013: integrated reactions, kinetic data, enzyme function data, improved disease classification: New options and contents in BRENDA. Nucleic Acids Res. 2013; 41:764–772. - PMC - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
