

A random forest based biomarker discovery and power analysis framework for diagnostics research
- PMID: 33228632
- PMCID: PMC7685541
- DOI: 10.1186/s12920-020-00826-6
A random forest based biomarker discovery and power analysis framework for diagnostics research
Abstract
Background: Biomarker identification is one of the major and important goal of functional genomics and translational medicine studies. Large scale -omics data are increasingly being accumulated and can provide vital means for the identification of biomarkers for the early diagnosis of complex disease and/or for advanced patient/diseases stratification. These tasks are clearly interlinked, and it is essential that an unbiased and stable methodology is applied in order to address them. Although, recently, many, primarily machine learning based, biomarker identification approaches have been developed, the exploration of potential associations between biomarker identification and the design of future experiments remains a challenge.
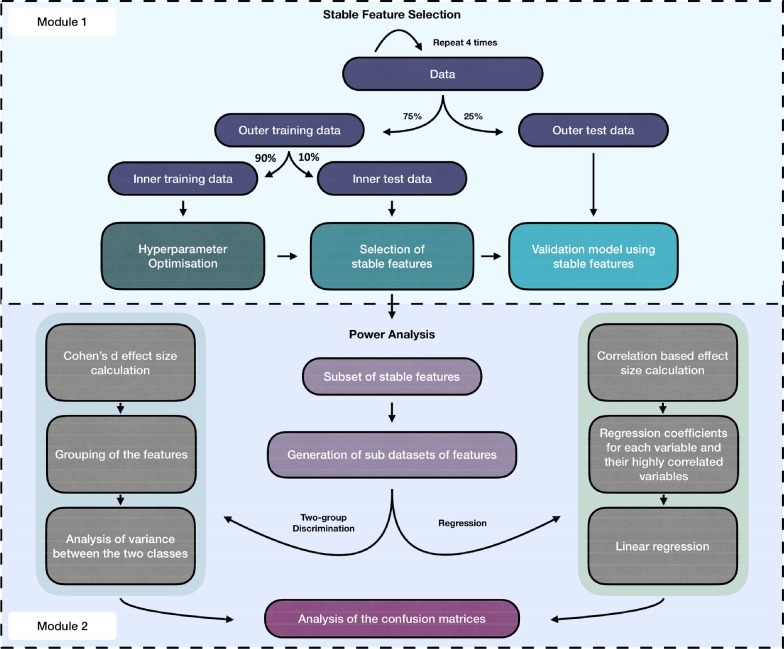
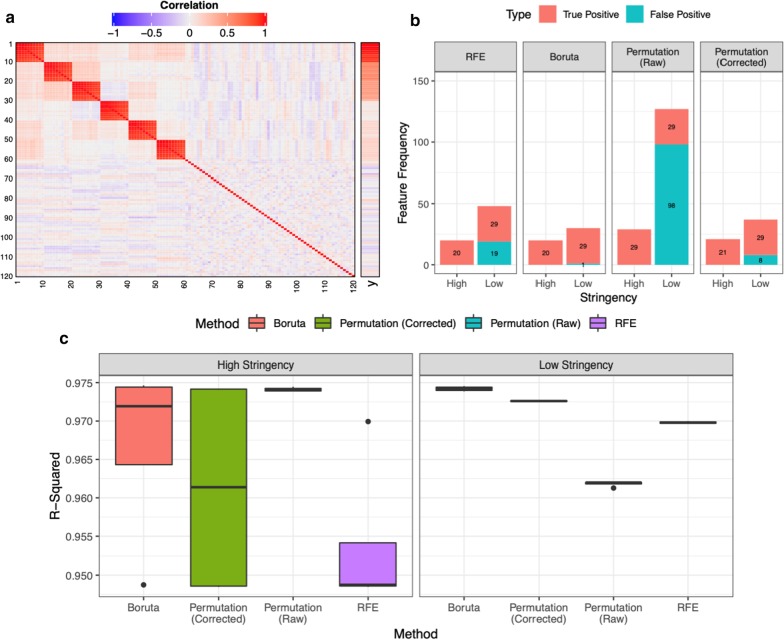
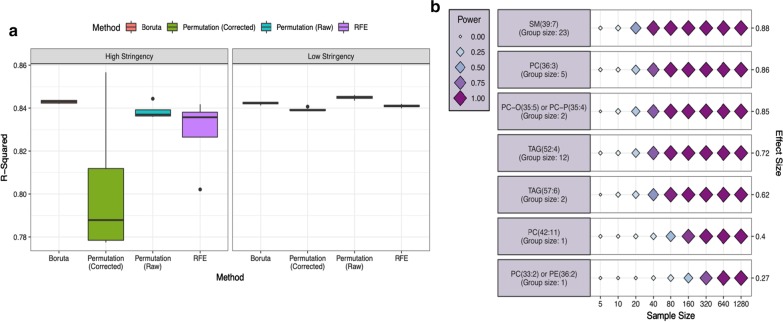
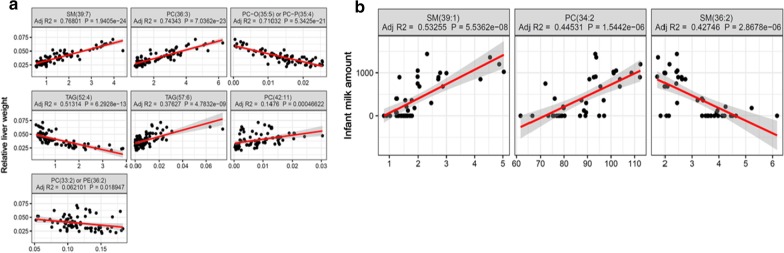
Methods: In this study, using both simulated and published experimentally derived datasets, we assessed the performance of several state-of-the-art Random Forest (RF) based decision approaches, namely the Boruta method, the permutation based feature selection without correction method, the permutation based feature selection with correction method, and the backward elimination based feature selection method. Moreover, we conducted a power analysis to estimate the number of samples required for potential future studies.
Results: We present a number of different RF based stable feature selection methods and compare their performances using simulated, as well as published, experimentally derived, datasets. Across all of the scenarios considered, we found the Boruta method to be the most stable methodology, whilst the Permutation (Raw) approach offered the largest number of relevant features, when allowed to stabilise over a number of iterations. Finally, we developed and made available a web interface ( https://joelarkman.shinyapps.io/PowerTools/ ) to streamline power calculations thereby aiding the design of potential future studies within a translational medicine context.
Conclusions: We developed a RF-based biomarker discovery framework and provide a web interface for our framework, termed PowerTools, that caters the design of appropriate and cost-effective subsequent future omics study.
Keywords: Biomarker; Feature selection; Power study; Random forest.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
