

Decoding spoken English from intracortical electrode arrays in dorsal precentral gyrus
- PMID: 33236720
- PMCID: PMC8293867
- DOI: 10.1088/1741-2552/abbfef
Decoding spoken English from intracortical electrode arrays in dorsal precentral gyrus
Abstract
Objective: To evaluate the potential of intracortical electrode array signals for brain-computer interfaces (BCIs) to restore lost speech, we measured the performance of decoders trained to discriminate a comprehensive basis set of 39 English phonemes and to synthesize speech sounds via a neural pattern matching method. We decoded neural correlates of spoken-out-loud words in the 'hand knob' area of precentral gyrus, a step toward the eventual goal of decoding attempted speech from ventral speech areas in patients who are unable to speak.
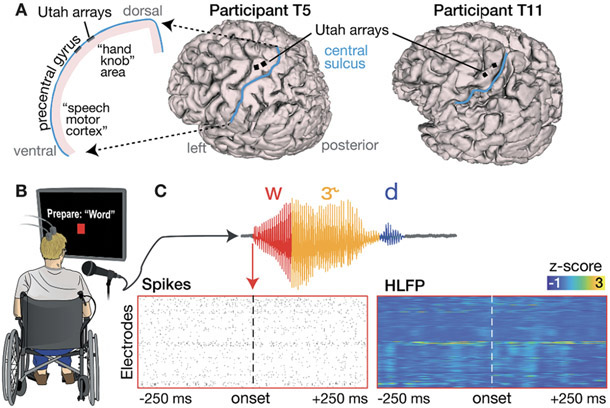
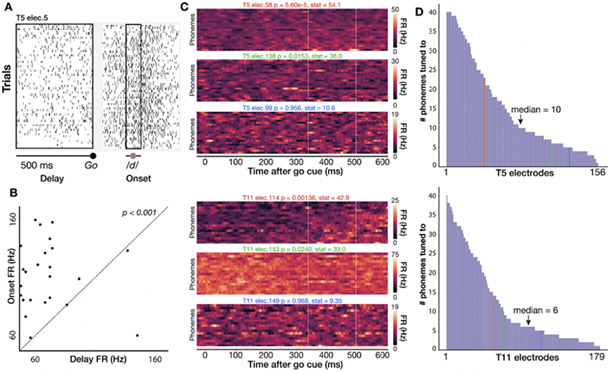
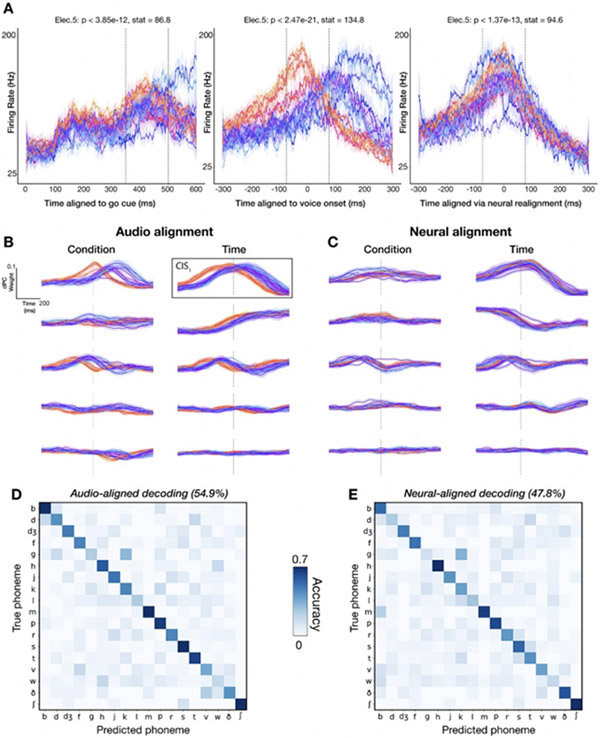
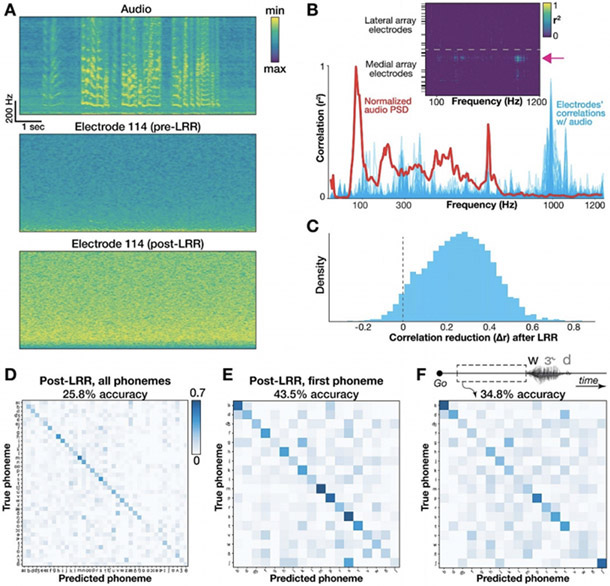
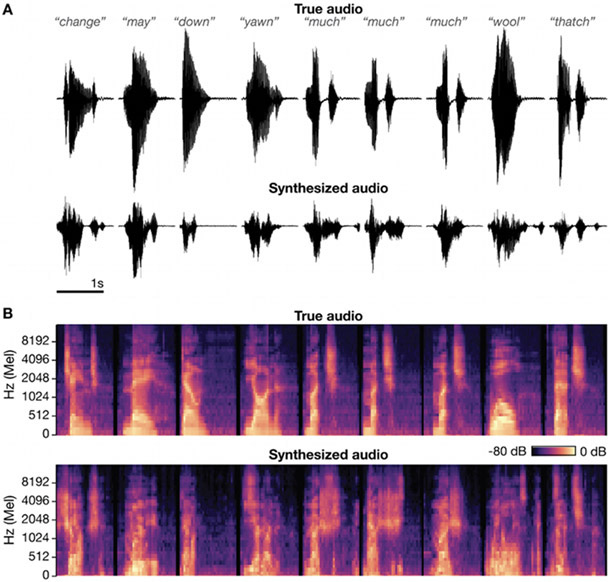
Approach: Neural and audio data were recorded while two BrainGate2 pilot clinical trial participants, each with two chronically-implanted 96-electrode arrays, spoke 420 different words that broadly sampled English phonemes. Phoneme onsets were identified from audio recordings, and their identities were then classified from neural features consisting of each electrode's binned action potential counts or high-frequency local field potential power. Speech synthesis was performed using the 'Brain-to-Speech' pattern matching method. We also examined two potential confounds specific to decoding overt speech: acoustic contamination of neural signals and systematic differences in labeling different phonemes' onset times.
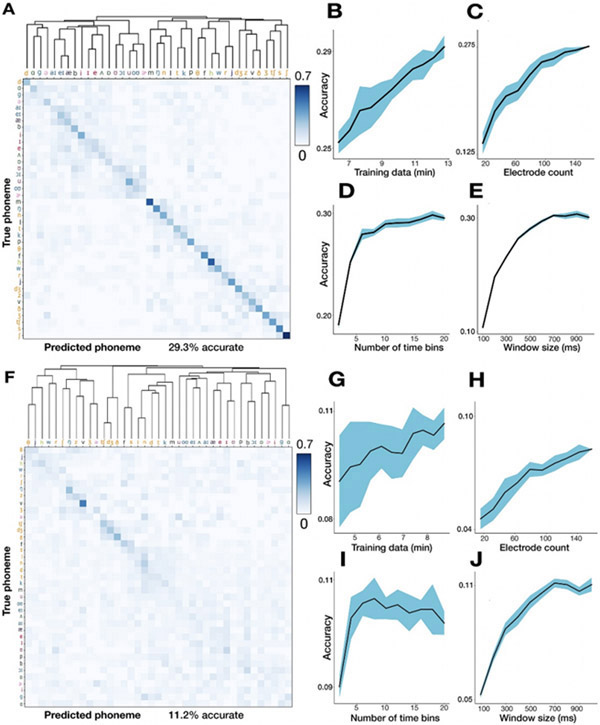
Main results: A linear decoder achieved up to 29.3% classification accuracy (chance = 6%) across 39 phonemes, while an RNN classifier achieved 33.9% accuracy. Parameter sweeps indicated that performance did not saturate when adding more electrodes or more training data, and that accuracy improved when utilizing time-varying structure in the data. Microphonic contamination and phoneme onset differences modestly increased decoding accuracy, but could be mitigated by acoustic artifact subtraction and using a neural speech onset marker, respectively. Speech synthesis achieved r = 0.523 correlation between true and reconstructed audio.
Significance: The ability to decode speech using intracortical electrode array signals from a nontraditional speech area suggests that placing electrode arrays in ventral speech areas is a promising direction for speech BCIs.
Conflict of interest statement
Declaration of interests
The MGH Translational Research Center has a clinical research support agreement with Neuralink, Paradromics, and Synchron, for which L.R.H. provides consultative input. JMH is a consultant for Neuralink Corp and Proteus Biomedical, and serves on the Medical Advisory Board of Enspire DBS. KVS consults for Neuralink Corp. and CTRL-Labs Inc. (part of Facebook Reality Labs) and is on the scientific advisory boards of MIND-X Inc., Inscopix Inc., and Heal Inc. All other authors have no competing interests.
Figures
References
-
- Abadi Martín, Barham Paul, Chen Jianmin, Chen Zhifeng, Davis Andy, Dean Jeffrey, Devin Matthieu, et al. 2016. “Tensorflow: A System for Large-Scale Machine Learning.” In 12th ${USENIX} Symposium on Operating Systems Design and Implementation ({OSDI}$ 16), 265–83.
-
- Abbott LF, and Dayan P. 1999. “The Effect of Correlated Variability on the Accuracy of a Population Code.” Neural Computation 11 (1): 91–101. - PubMed
-
- Ajiboye A. Bolu, Willett Francis R., Young Daniel R., Memberg William D., Murphy Brian A., Miller Jonathan P., Walter Benjamin L., et al. 2017. “Restoration of Reaching and Grasping Movements through Brain-Controlled Muscle Stimulation in a Person with Tetraplegia: A Proof-of-Concept Demonstration.” The Lancet 389 (10081): 1821–30. - PMC - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical