

Comprehensive prediction of secondary metabolite structure and biological activity from microbial genome sequences
- PMID: 33247171
- PMCID: PMC7699628
- DOI: 10.1038/s41467-020-19986-1
Comprehensive prediction of secondary metabolite structure and biological activity from microbial genome sequences
Abstract
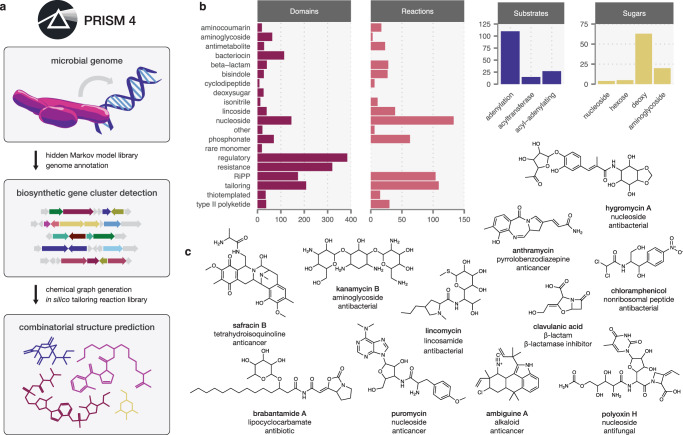
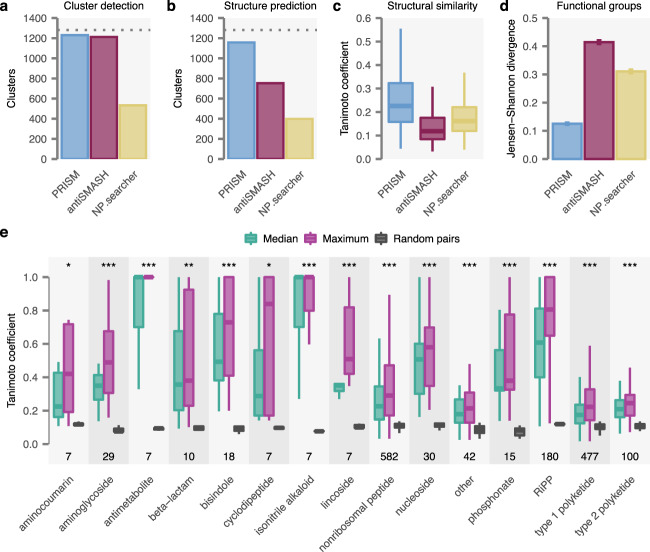
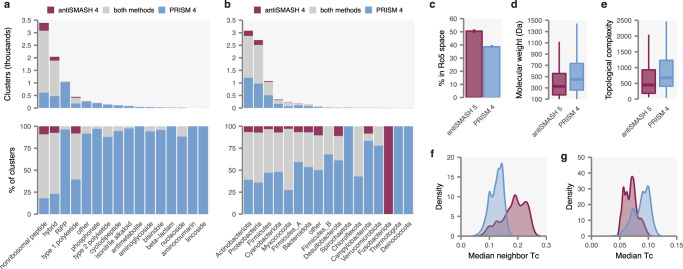
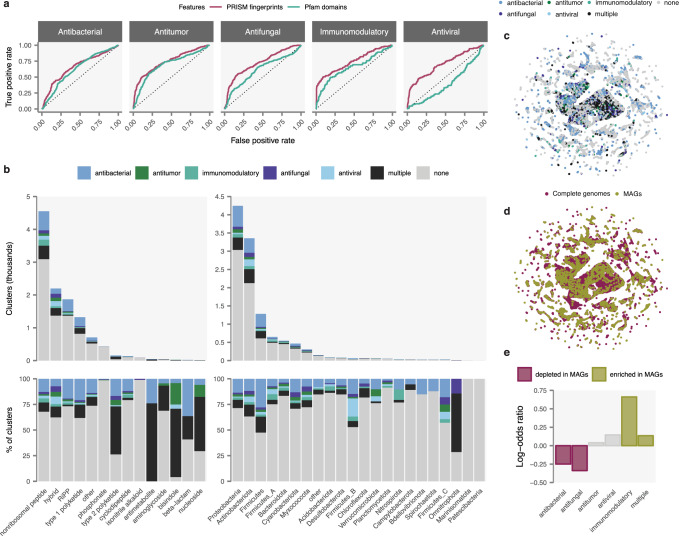
Novel antibiotics are urgently needed to address the looming global crisis of antibiotic resistance. Historically, the primary source of clinically used antibiotics has been microbial secondary metabolism. Microbial genome sequencing has revealed a plethora of uncharacterized natural antibiotics that remain to be discovered. However, the isolation of these molecules is hindered by the challenge of linking sequence information to the chemical structures of the encoded molecules. Here, we present PRISM 4, a comprehensive platform for prediction of the chemical structures of genomically encoded antibiotics, including all classes of bacterial antibiotics currently in clinical use. The accuracy of chemical structure prediction enables the development of machine-learning methods to predict the likely biological activity of encoded molecules. We apply PRISM 4 to chart secondary metabolite biosynthesis in a collection of over 10,000 bacterial genomes from both cultured isolates and metagenomic datasets, revealing thousands of encoded antibiotics. PRISM 4 is freely available as an interactive web application at http://prism.adapsyn.com .
Conflict of interest statement
N.A.M. is a founder of Adapsyn Bioscience. M.A.S. and C.W.J. are or were at one time consultants to Adapsyn Bioscience. M.G., N.J.M., A.M.K., R.J.M., H.L., A.P., N.S., D.P.W., and C.A.D. are or were at one time employed by Adapsyn Bioscience. The remaining authors declare no competing interests.
Figures
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
