

HERB: a high-throughput experiment- and reference-guided database of traditional Chinese medicine
- PMID: 33264402
- PMCID: PMC7779036
- DOI: 10.1093/nar/gkaa1063
HERB: a high-throughput experiment- and reference-guided database of traditional Chinese medicine
Abstract
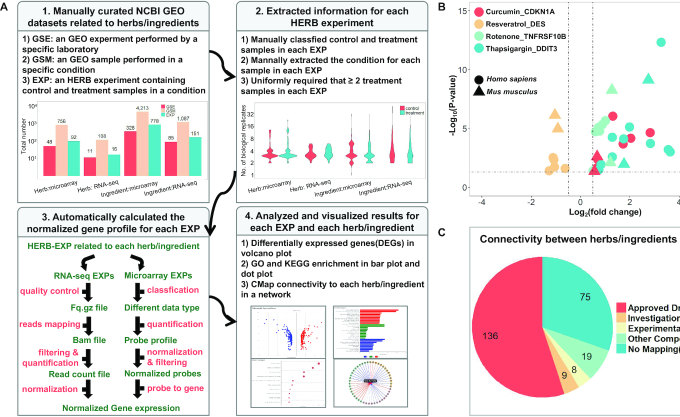
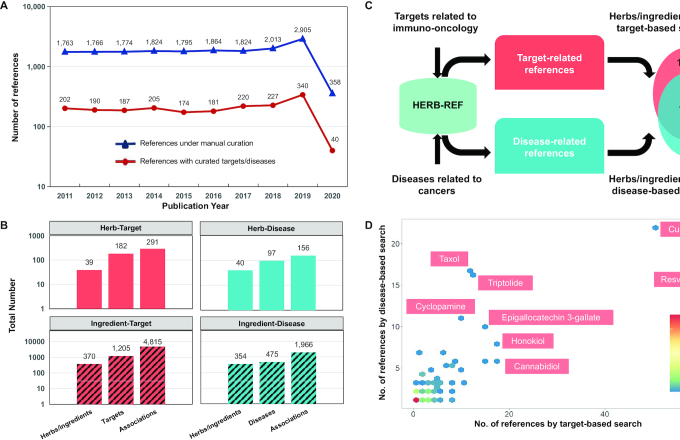
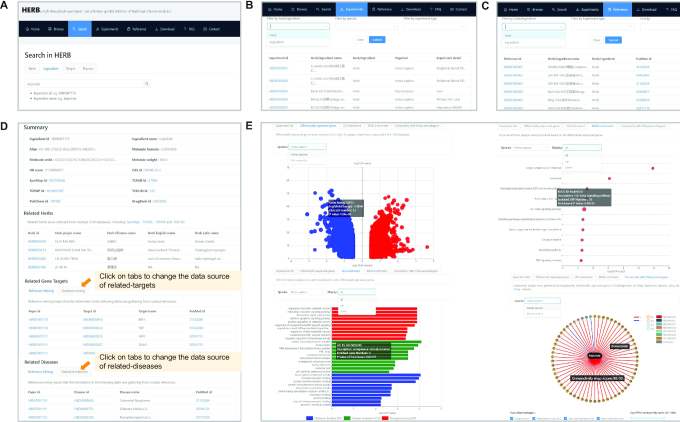
Pharmacotranscriptomics has become a powerful approach for evaluating the therapeutic efficacy of drugs and discovering new drug targets. Recently, studies of traditional Chinese medicine (TCM) have increasingly turned to high-throughput transcriptomic screens for molecular effects of herbs/ingredients. And numerous studies have examined gene targets for herbs/ingredients, and link herbs/ingredients to various modern diseases. However, there is currently no systematic database organizing these data for TCM. Therefore, we built HERB, a high-throughput experiment- and reference-guided database of TCM, with its Chinese name as BenCaoZuJian. We re-analyzed 6164 gene expression profiles from 1037 high-throughput experiments evaluating TCM herbs/ingredients, and generated connections between TCM herbs/ingredients and 2837 modern drugs by mapping the comprehensive pharmacotranscriptomics dataset in HERB to CMap, the largest such dataset for modern drugs. Moreover, we manually curated 1241 gene targets and 494 modern diseases for 473 herbs/ingredients from 1966 references published recently, and cross-referenced this novel information to databases containing such data for drugs. Together with database mining and statistical inference, we linked 12 933 targets and 28 212 diseases to 7263 herbs and 49 258 ingredients and provided six pairwise relationships among them in HERB. In summary, HERB will intensively support the modernization of TCM and guide rational modern drug discovery efforts. And it is accessible through http://herb.ac.cn/.
© The Author(s) 2020. Published by Oxford University Press on behalf of Nucleic Acids Research.
Figures
References
-
- Kwon O.S., Kim W., Cha H.J., Lee H.. In silico drug repositioning: from large-scale transcriptome data to therapeutics. Arch. Pharm. Res. 2019; 42:879–889. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
