

Learning to Cooperate via an Attention-Based Communication Neural Network in Decentralized Multi-Robot Exploration
- PMID: 33267009
- PMCID: PMC7514775
- DOI: 10.3390/e21030294
Learning to Cooperate via an Attention-Based Communication Neural Network in Decentralized Multi-Robot Exploration
Abstract
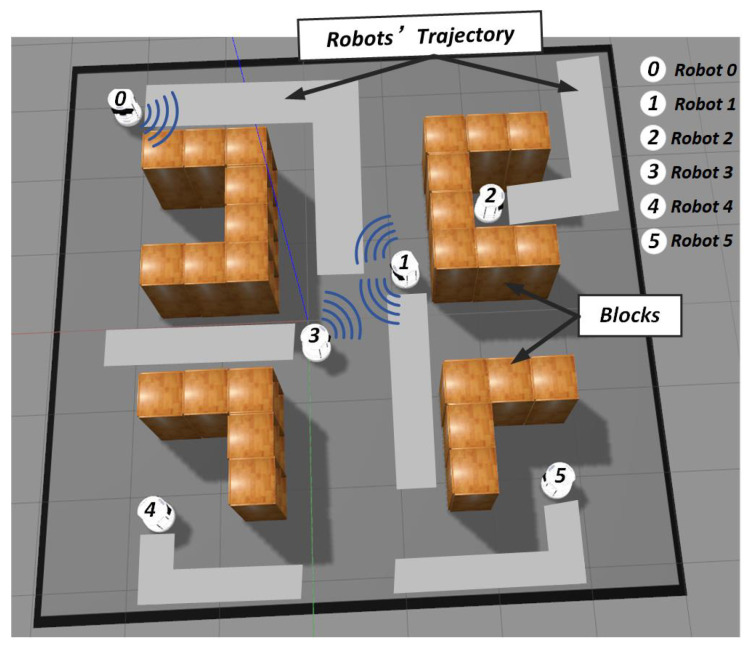
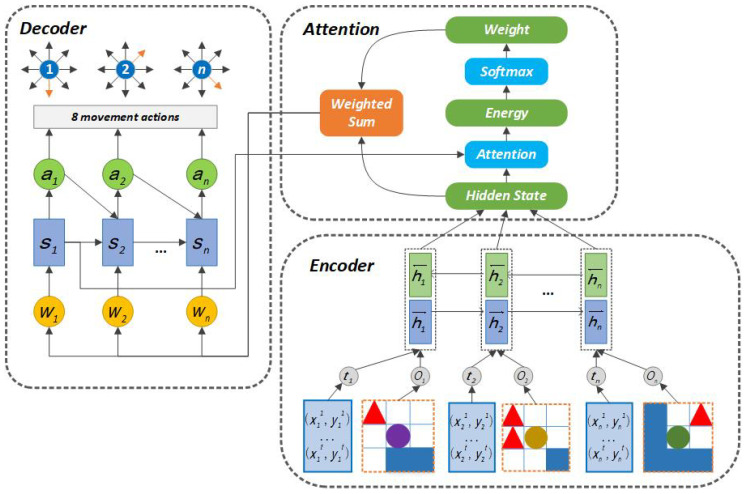
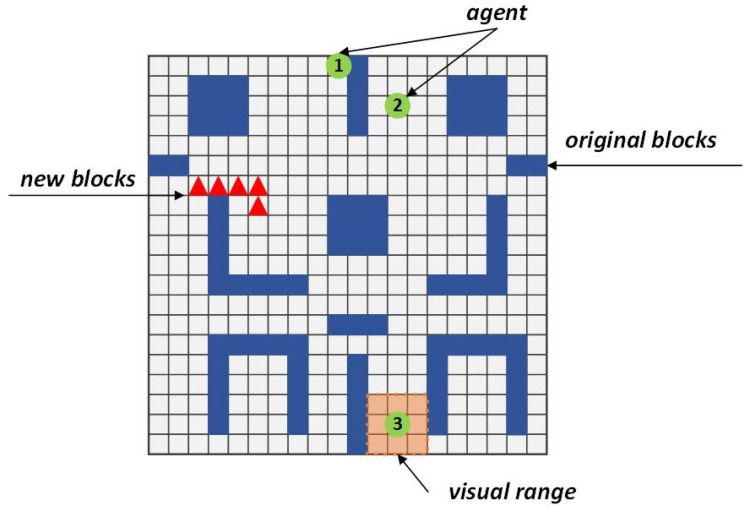
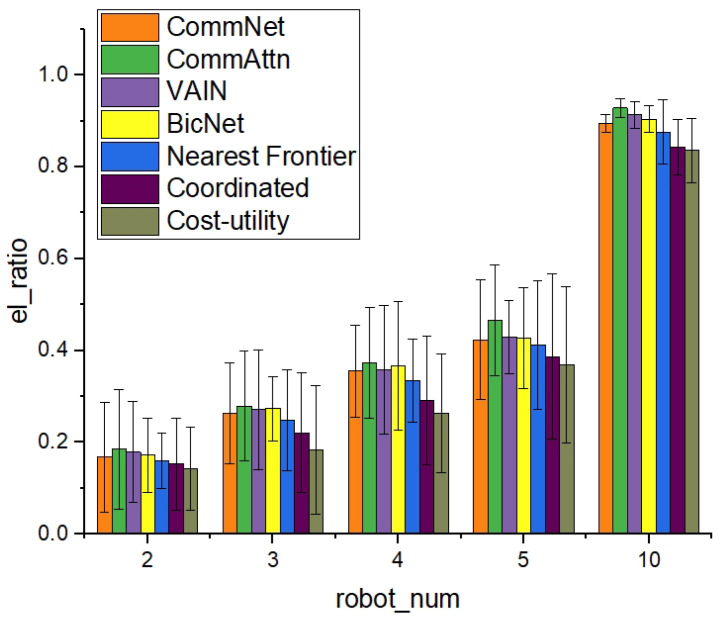
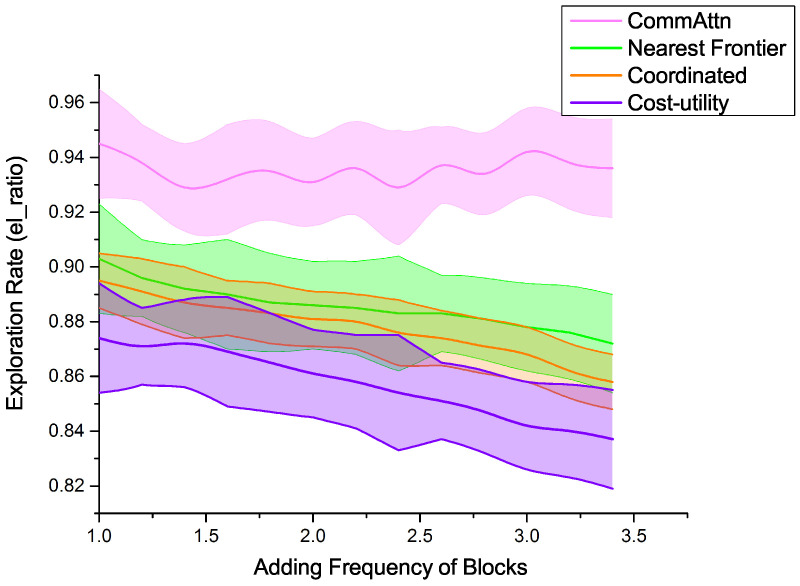
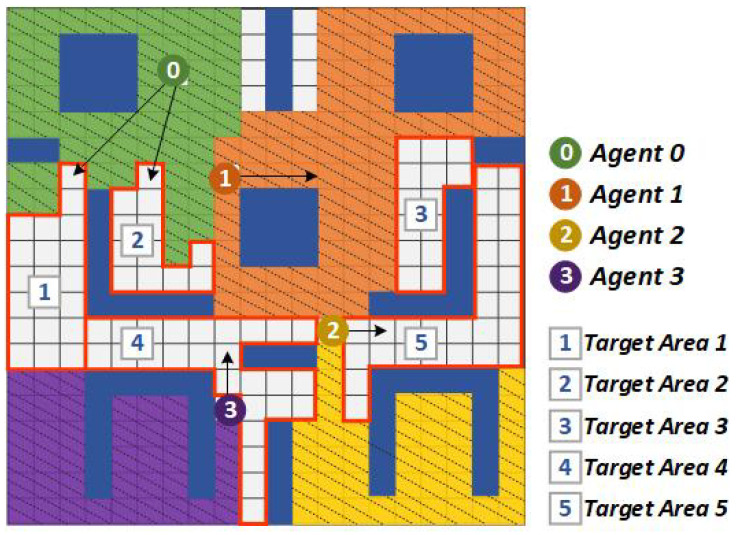
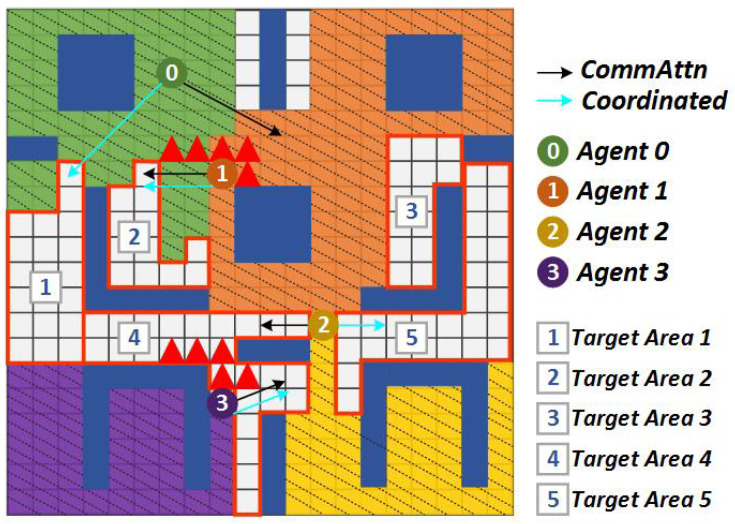
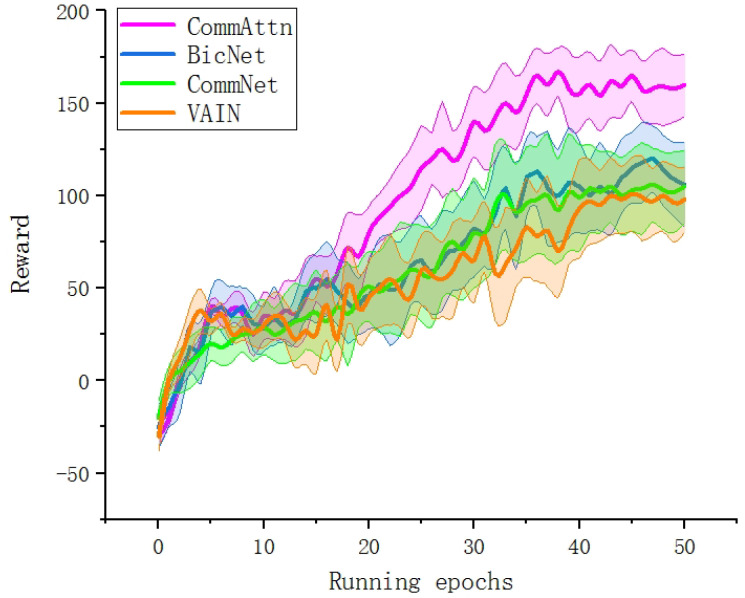
In a decentralized multi-robot exploration problem, the robots have to cooperate effectively to map a strange environment as soon as possible without a centralized controller. In the past few decades, a set of "human-designed" cooperation strategies have been proposed to address this problem, such as the well-known frontier-based approach. However, many real-world settings, especially the ones that are constantly changing, are too complex for humans to design efficient and decentralized strategies. This paper presents a novel approach, the Attention-based Communication neural network (CommAttn), to "learn" the cooperation strategies automatically in the decentralized multi-robot exploration problem. The communication neural network enables the robots to learn the cooperation strategies with explicit communication. Moreover, the attention mechanism we introduced additionally can precisely calculate whether the communication is necessary for each pair of agents by considering the relevance of each received message, which enables the robots to communicate only with the necessary partners. The empirical results on a simulated multi-robot disaster exploration scenario demonstrate that our proposal outperforms the traditional "human-designed" methods, as well as other competing "learning-based" methods in the exploration task.
Keywords: attention mechanism; deep reinforcement learning; dynamic environments; multi-robot exploration.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
Similar articles
-
Distributed Non-Communicating Multi-Robot Collision Avoidance via Map-Based Deep Reinforcement Learning.Sensors (Basel). 2020 Aug 27;20(17):4836. doi: 10.3390/s20174836. Sensors (Basel). 2020. PMID: 32867080 Free PMC article.
-
Non-Communication Decentralized Multi-Robot Collision Avoidance in Grid Map Workspace with Double Deep Q-Network.Sensors (Basel). 2021 Jan 27;21(3):841. doi: 10.3390/s21030841. Sensors (Basel). 2021. PMID: 33513856 Free PMC article.
-
Mobile robots exploration through cnn-based reinforcement learning.Robotics Biomim. 2016;3(1):24. doi: 10.1186/s40638-016-0055-x. Epub 2016 Dec 21. Robotics Biomim. 2016. PMID: 28066702 Free PMC article.
-
Multi-Agent Deep Reinforcement Learning for Multi-Robot Applications: A Survey.Sensors (Basel). 2023 Mar 30;23(7):3625. doi: 10.3390/s23073625. Sensors (Basel). 2023. PMID: 37050685 Free PMC article. Review.
-
Reinforcement Learning Approaches in Social Robotics.Sensors (Basel). 2021 Feb 11;21(4):1292. doi: 10.3390/s21041292. Sensors (Basel). 2021. PMID: 33670257 Free PMC article. Review.
Cited by
-
Attention-Based Fault-Tolerant Approach for Multi-Agent Reinforcement Learning Systems.Entropy (Basel). 2021 Aug 31;23(9):1133. doi: 10.3390/e23091133. Entropy (Basel). 2021. PMID: 34573757 Free PMC article.
-
Object Detection Method for Grasping Robot Based on Improved YOLOv5.Micromachines (Basel). 2021 Oct 20;12(11):1273. doi: 10.3390/mi12111273. Micromachines (Basel). 2021. PMID: 34832685 Free PMC article.
References
-
- Juliá M., Gil A., Reinoso O. A comparison of path planning strategies for autonomous exploration and mapping of unknown environments. Auton. Robot. 2012;33:427–444. doi: 10.1007/s10514-012-9298-8. - DOI
-
- Arai T., Pagello E., Parker L.E. Advances in multi-robot systems. IEEE Trans. Robot. Autom. 2002;18:655–661. doi: 10.1109/TRA.2002.806024. - DOI
-
- Peng Z., Zhang L., Luo T. Learning to Communicate via Supervised Attentional Message Processing; Proceedings of the 31st International Conference on Computer Animation and Social Agents; Beijing, China. 21–23 May 2018; New York, NY, USA: ACM; 2018. pp. 11–16.
-
- Khamis A., Hussein A., Elmogy A. Cooperative Robots and Sensor Networks 2015. Springer; Cham, Switzerland: 2015. Multi-robot task allocation: A review of the state-of-the-art; pp. 31–51.
-
- Geng M., Li Y., Ding B., Wang H. Deep Learning-based Cooperative Trail Following for Multi-Robot System; Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN); Rio de Janeiro, Brazil. 8–13 July 2018; pp. 1–8.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
