

A generative spiking neural-network model of goal-directed behaviour and one-step planning
- PMID: 33290414
- PMCID: PMC7748287
- DOI: 10.1371/journal.pcbi.1007579
A generative spiking neural-network model of goal-directed behaviour and one-step planning
Abstract
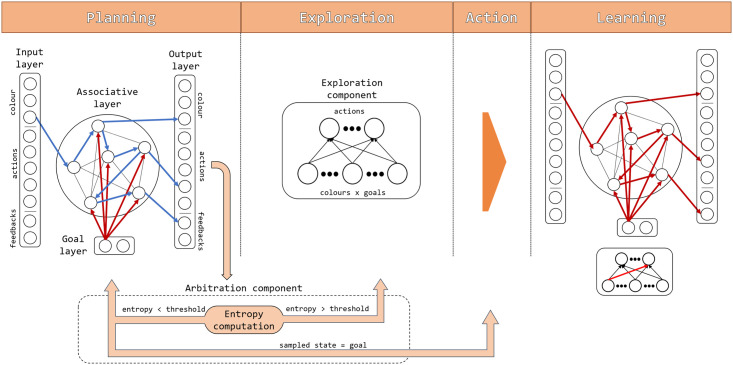
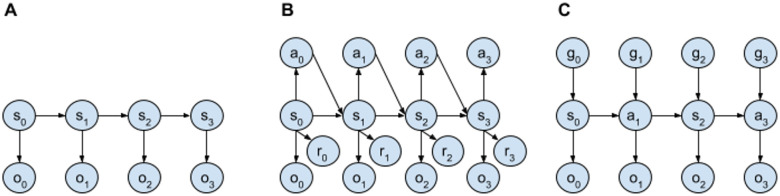
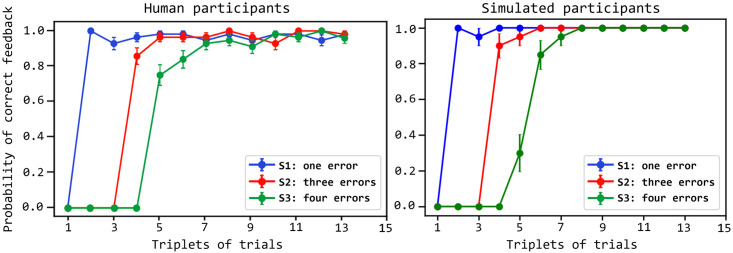
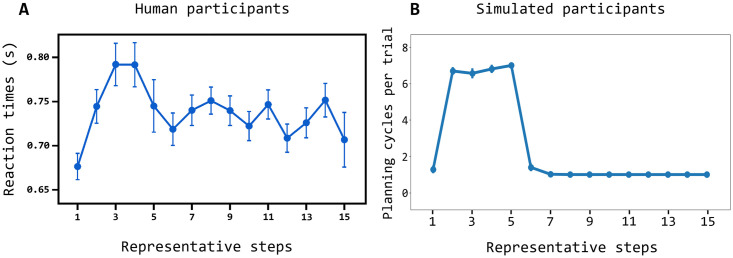
In mammals, goal-directed and planning processes support flexible behaviour used to face new situations that cannot be tackled through more efficient but rigid habitual behaviours. Within the Bayesian modelling approach of brain and behaviour, models have been proposed to perform planning as probabilistic inference but this approach encounters a crucial problem: explaining how such inference might be implemented in brain spiking networks. Recently, the literature has proposed some models that face this problem through recurrent spiking neural networks able to internally simulate state trajectories, the core function at the basis of planning. However, the proposed models have relevant limitations that make them biologically implausible, namely their world model is trained 'off-line' before solving the target tasks, and they are trained with supervised learning procedures that are biologically and ecologically not plausible. Here we propose two novel hypotheses on how brain might overcome these problems, and operationalise them in a novel architecture pivoting on a spiking recurrent neural network. The first hypothesis allows the architecture to learn the world model in parallel with its use for planning: to this purpose, a new arbitration mechanism decides when to explore, for learning the world model, or when to exploit it, for planning, based on the entropy of the world model itself. The second hypothesis allows the architecture to use an unsupervised learning process to learn the world model by observing the effects of actions. The architecture is validated by reproducing and accounting for the learning profiles and reaction times of human participants learning to solve a visuomotor learning task that is new for them. Overall, the architecture represents the first instance of a model bridging probabilistic planning and spiking-processes that has a degree of autonomy analogous to the one of real organisms.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures

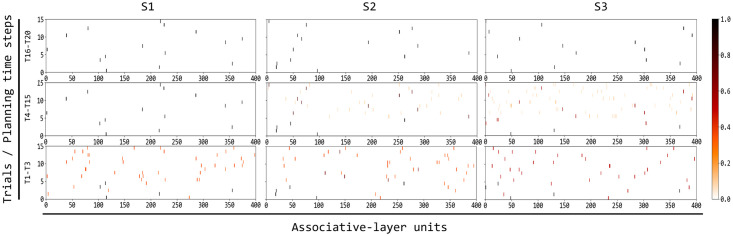
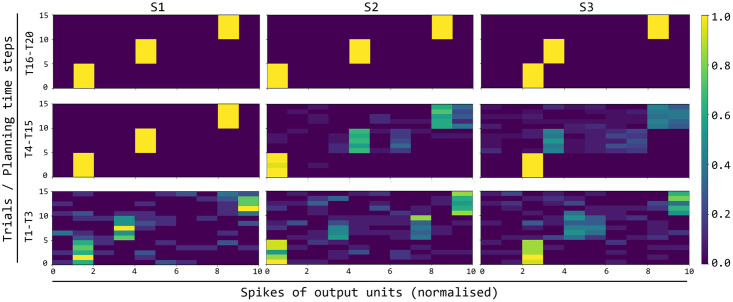
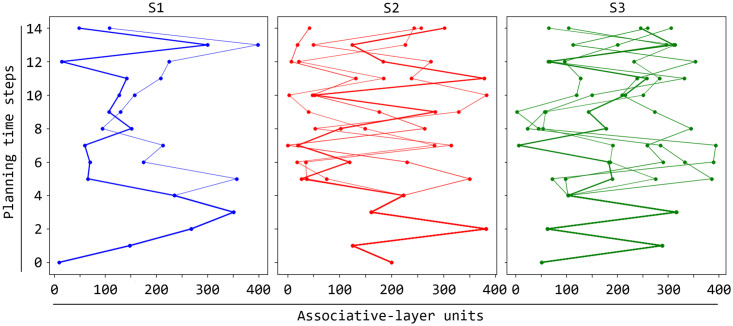
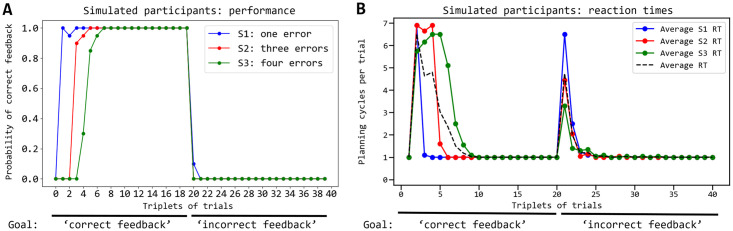
References
-
- Dickinson A, Balleine B. Motivational control of goal-directed action. Animal Learning & Behavior. 1994; 22(1):1–18.
-
- Sutton RS, Barto AG. Reinforcement learning: an introduction. Cambridge, MA: The MIT Press; 1998.
-
- Sutton RS. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. In: Proceedings of the seventh international conference on machine learning. Vol. 216; 1990. p. 216–224.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
