

Large expert-curated database for benchmarking document similarity detection in biomedical literature search
- PMID: 33326193
- PMCID: PMC7291946
- DOI: 10.1093/database/baz085
Large expert-curated database for benchmarking document similarity detection in biomedical literature search
Abstract
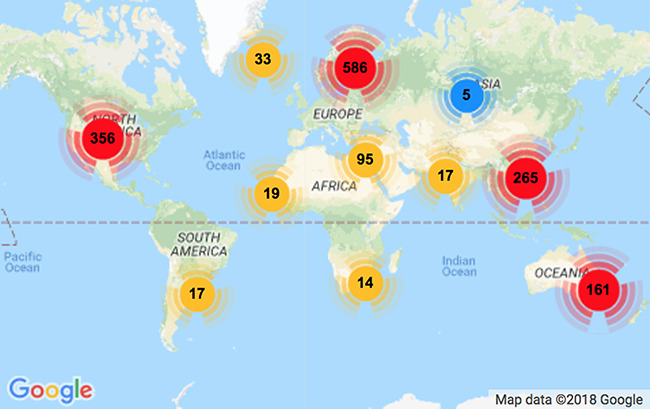
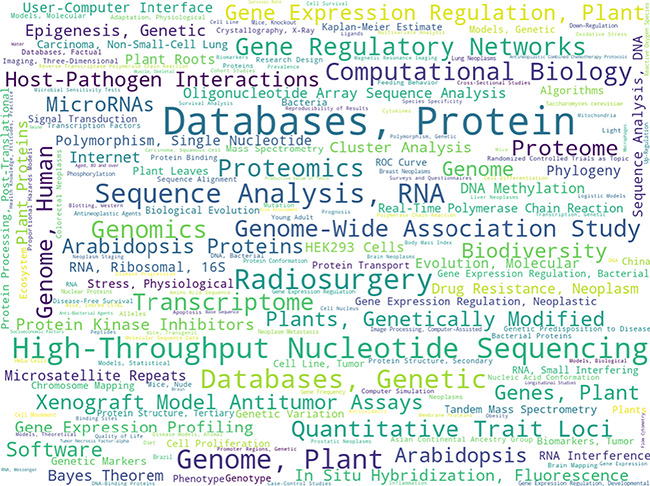
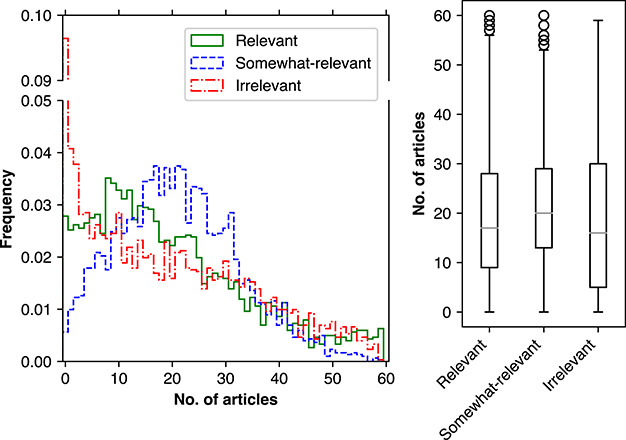
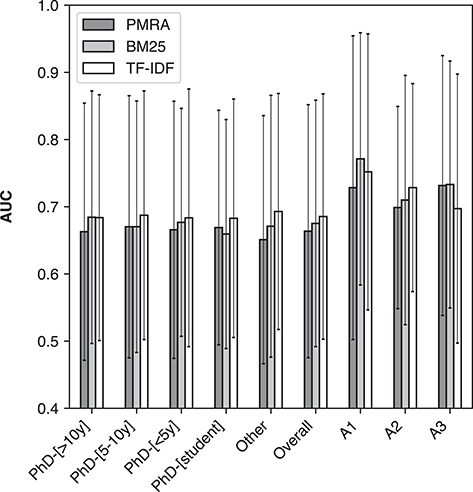
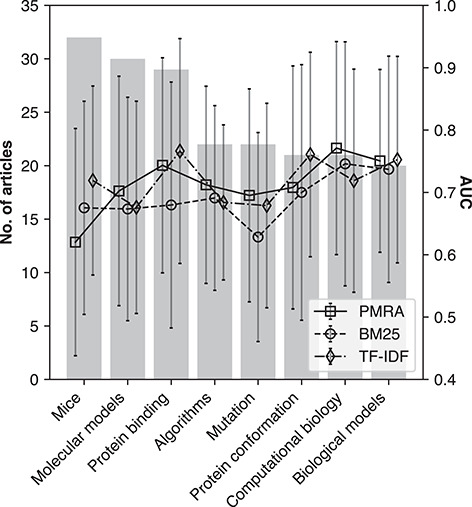
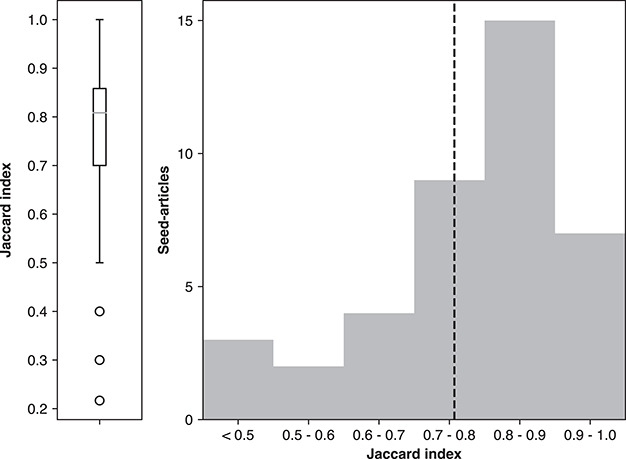
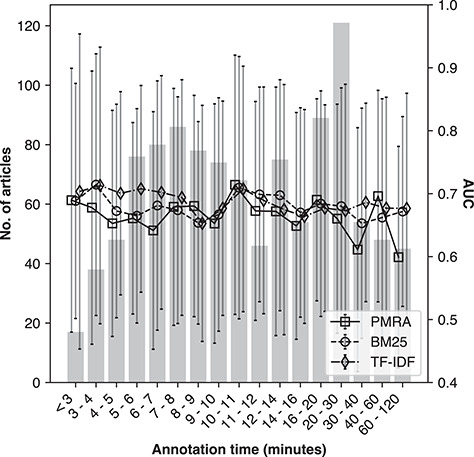
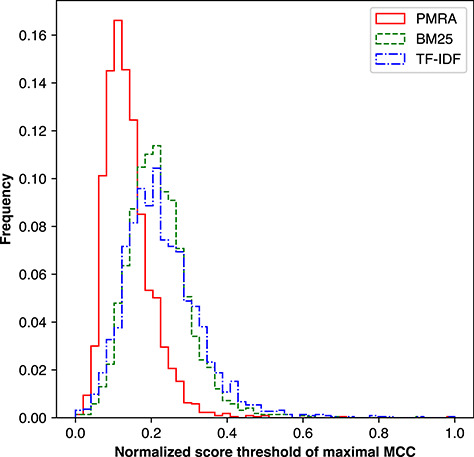
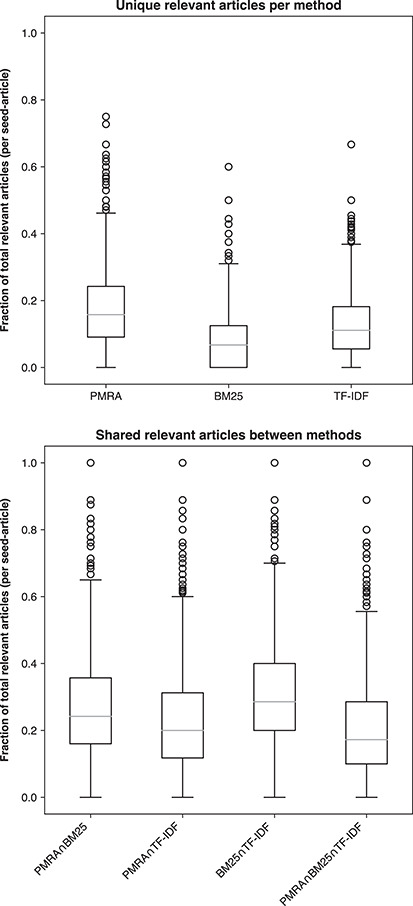
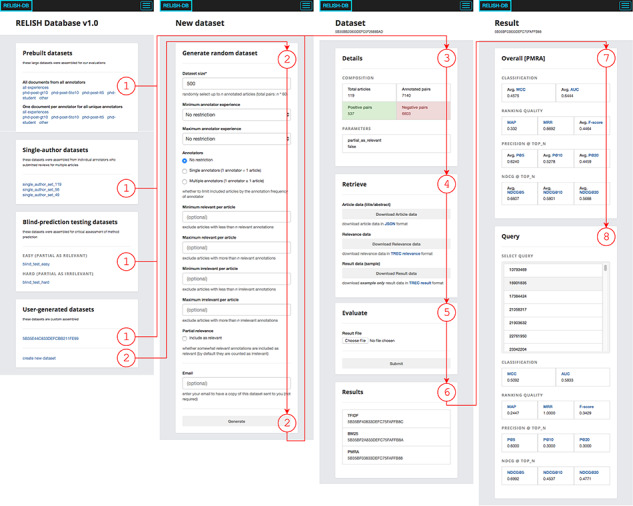
Document recommendation systems for locating relevant literature have mostly relied on methods developed a decade ago. This is largely due to the lack of a large offline gold-standard benchmark of relevant documents that cover a variety of research fields such that newly developed literature search techniques can be compared, improved and translated into practice. To overcome this bottleneck, we have established the RElevant LIterature SearcH consortium consisting of more than 1500 scientists from 84 countries, who have collectively annotated the relevance of over 180 000 PubMed-listed articles with regard to their respective seed (input) article/s. The majority of annotations were contributed by highly experienced, original authors of the seed articles. The collected data cover 76% of all unique PubMed Medical Subject Headings descriptors. No systematic biases were observed across different experience levels, research fields or time spent on annotations. More importantly, annotations of the same document pairs contributed by different scientists were highly concordant. We further show that the three representative baseline methods used to generate recommended articles for evaluation (Okapi Best Matching 25, Term Frequency-Inverse Document Frequency and PubMed Related Articles) had similar overall performances. Additionally, we found that these methods each tend to produce distinct collections of recommended articles, suggesting that a hybrid method may be required to completely capture all relevant articles. The established database server located at https://relishdb.ict.griffith.edu.au is freely available for the downloading of annotation data and the blind testing of new methods. We expect that this benchmark will be useful for stimulating the development of new powerful techniques for title and title/abstract-based search engines for relevant articles in biomedical research.
© The Author(s) 2019. Published by Oxford University Press.
Figures
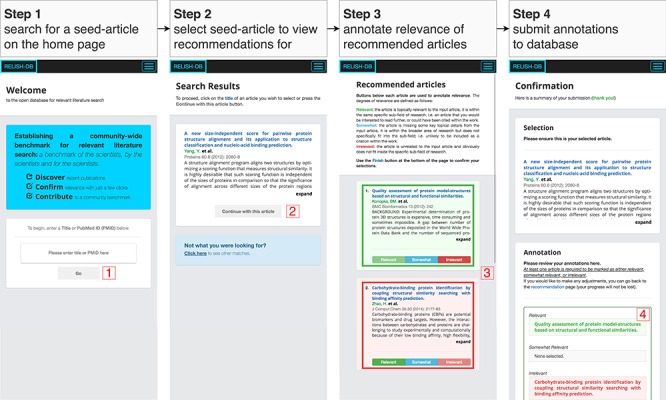
References
-
- Anderson D.P. (2004) BOINC: a system for public-resource computing and storage. In: Proceedings of the 5th IEEE/ACM International Workshop on Grid Computing. pp. 4–10. IEEE Computer Society, Washington, DC, USA.
-
- Baeza-Yates R., Hurtado C. and Mendoza M. (2004) Query recommendation using query logs in search engines. In: International Conference on Extending Database Technology. Springer, Berlin, Heidelberg, pp. 588–596.
-
- Beel J., Breitinger C., Langer S. et al. (2016) Towards reproducibility in recommender-systems research. User Model. User-adapt. Interact., 26, 69–101.
-
- Beel J., Gipp B., Langer S. et al. (2016) Research paper recommender systems: a literature survey. Int. J. Digit. Libr., 17, 305–338.
