

Belief dynamics extraction
Abstract
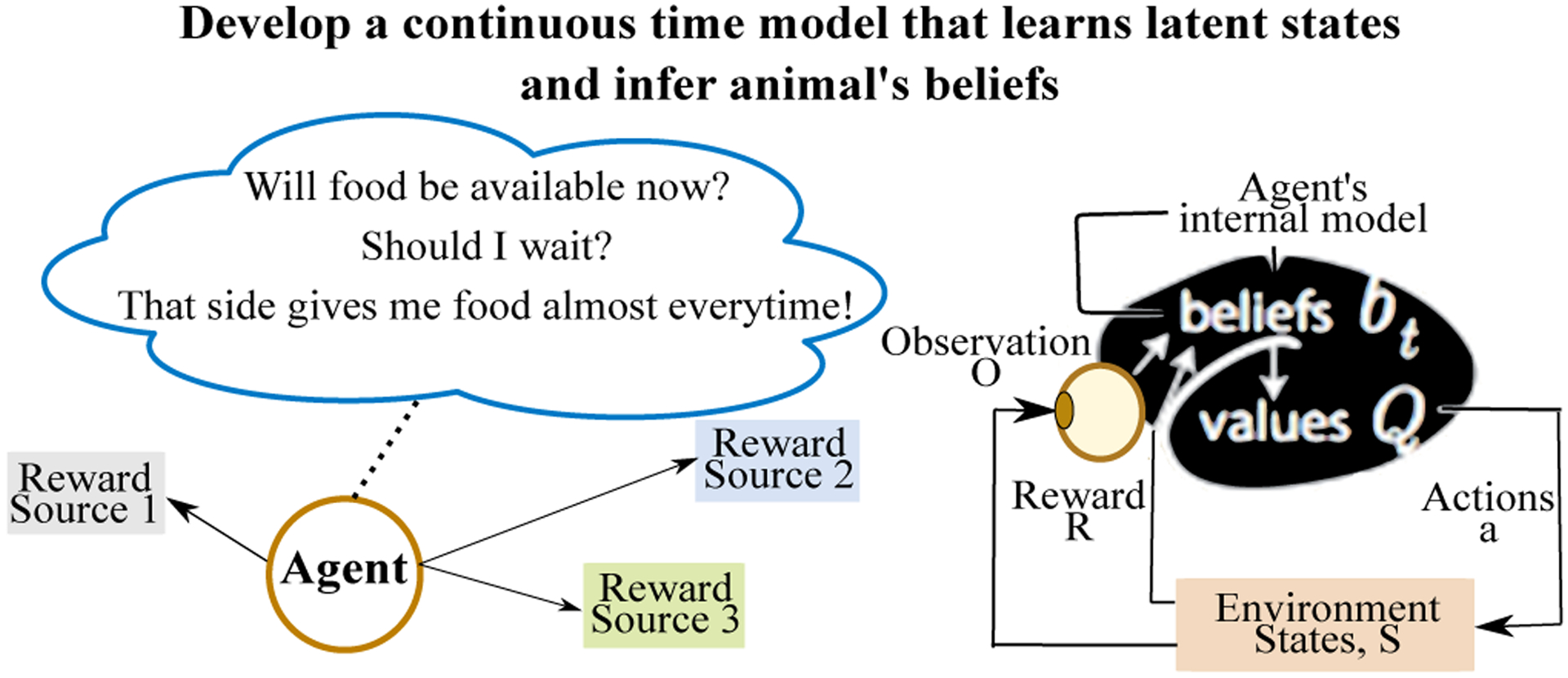
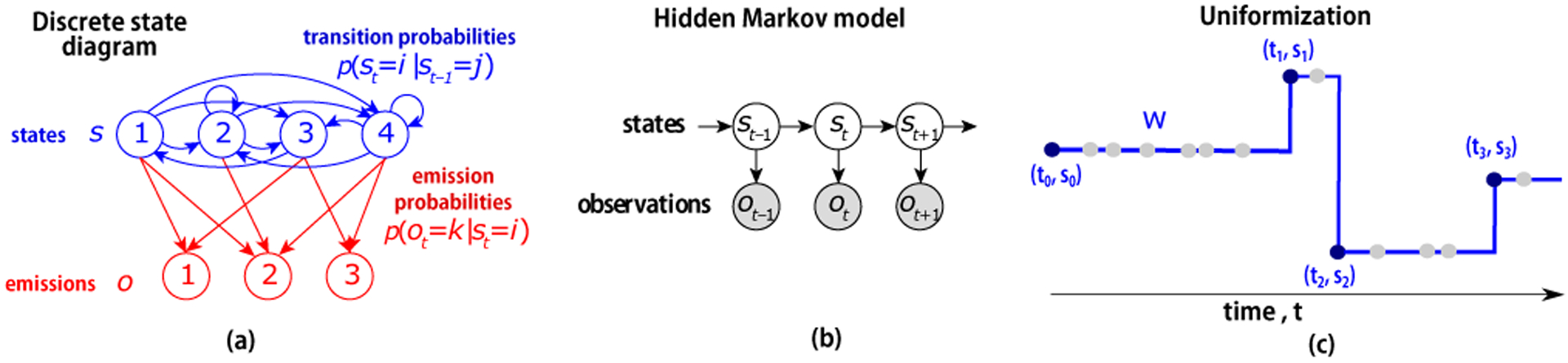
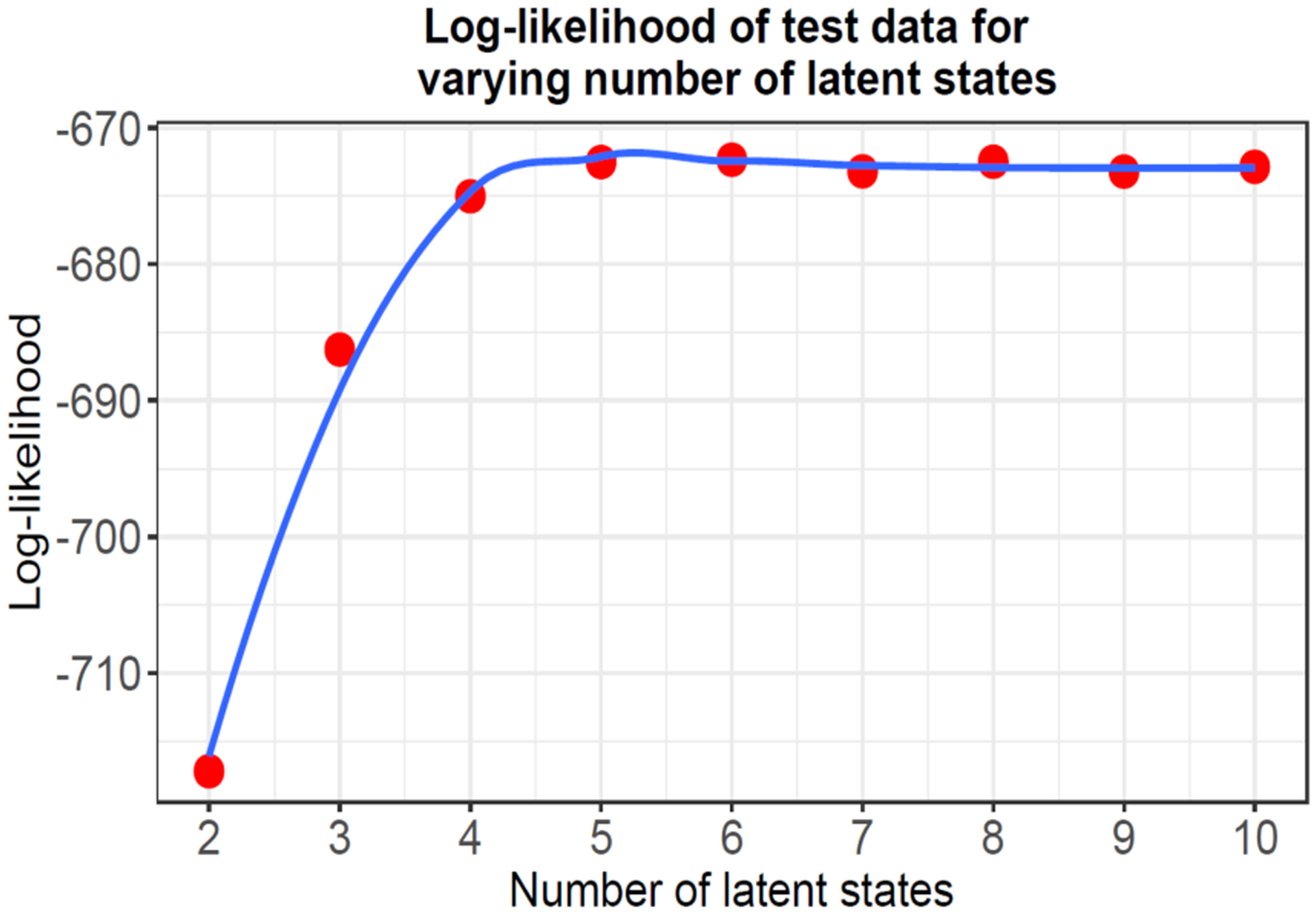
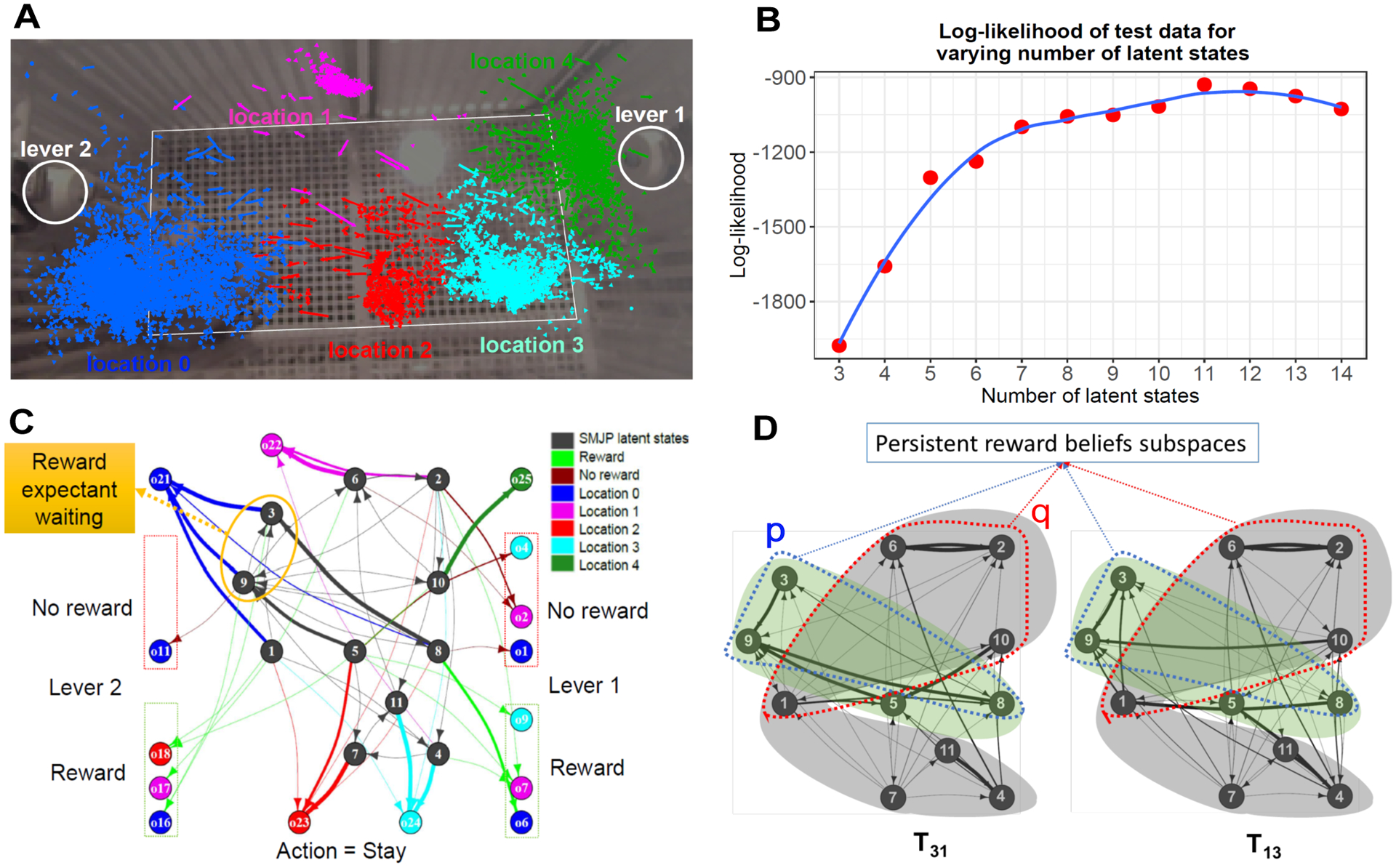
Animal behavior is not driven simply by its current observations, but is strongly influenced by internal states. Estimating the structure of these internal states is crucial for understanding the neural basis of behavior. In principle, internal states can be estimated by inverting behavior models, as in inverse model-based Reinforcement Learning. However, this requires careful parameterization and risks model-mismatch to the animal. Here we take a data-driven approach to infer latent states directly from observations of behavior, using a partially observable switching semi-Markov process. This process has two elements critical for capturing animal behavior: it captures non-exponential distribution of times between observations, and transitions between latent states depend on the animal's actions, features that require more complex non-markovian models to represent. To demonstrate the utility of our approach, we apply it to the observations of a simulated optimal agent performing a foraging task, and find that latent dynamics extracted by the model has correspondences with the belief dynamics of the agent. Finally, we apply our model to identify latent states in the behaviors of monkey performing a foraging task, and find clusters of latent states that identify periods of time consistent with expectant waiting. This data-driven behavioral model will be valuable for inferring latent cognitive states, and thereby for measuring neural representations of those states.
Keywords: Animal behavior; Belief dynamics; Foraging; Partially observable switching semi-Markov process.
Figures



References
-
- Anderson DJ, & Perona P (2014). Toward a science of computational ethology. Neuron, 84(1), 18–31. - PubMed
-
- Bellman R (1957). Dynamic programming: Princeton univ. press. Princeton.
-
- Brandes U, Delling D, Gaertler M, Gorke R, Hoefer M, Nikoloski Z, & Wagner D (2008). On modularity clustering. IEEE transactions on knowledge and data engineering, 20(2), 172–188.
-
- Charnov E, & Orians GH (2006). Optimal foraging: some theoretical explorations.
-
- Dhillon IS, Mallela S, & Modha DS (2003). Information-theoretic co-clustering. In Proceedings of the ninth acm sigkdd international conference on knowledge discovery and data mining (pp. 89–98).
Grants and funding
LinkOut - more resources
Full Text Sources