

A neuroimaging biomarker for sustained experimental and clinical pain
- PMID: 33398159
- PMCID: PMC8447264
- DOI: 10.1038/s41591-020-1142-7
A neuroimaging biomarker for sustained experimental and clinical pain
Abstract
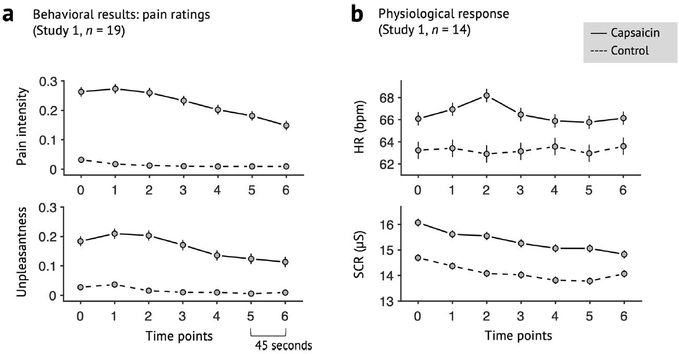
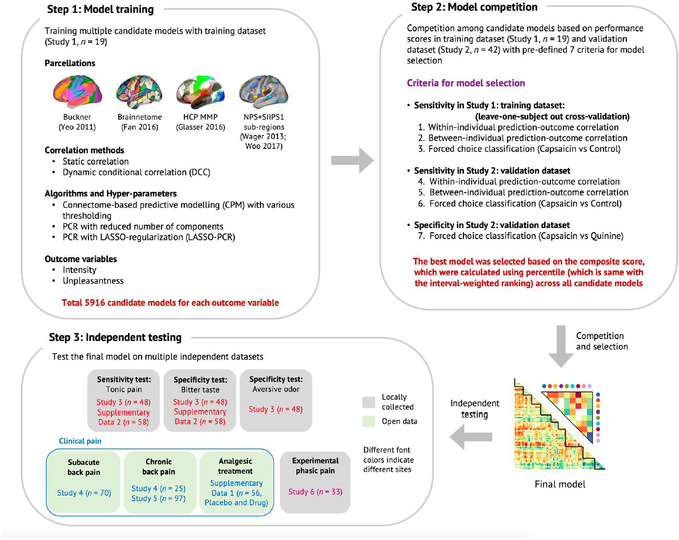
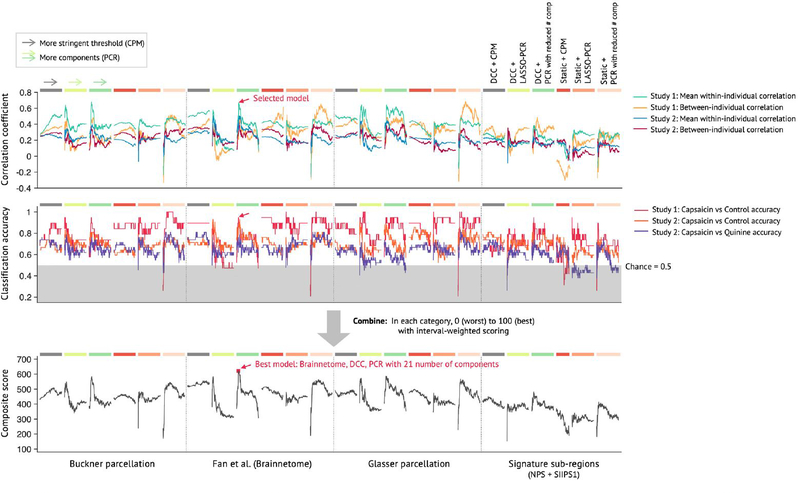
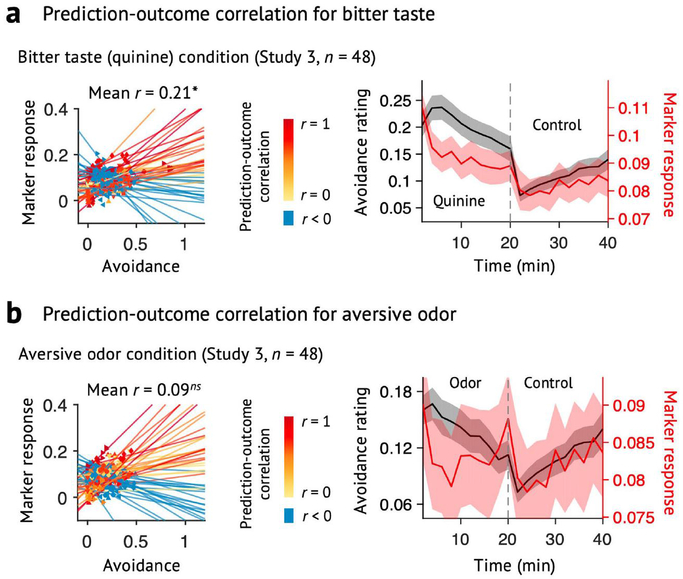
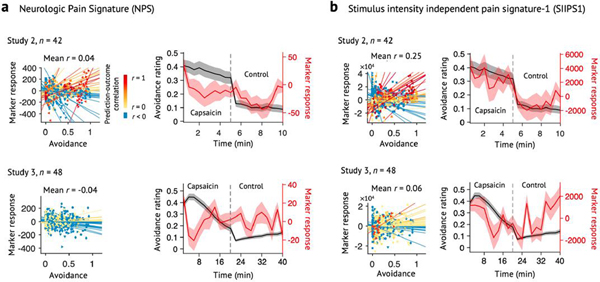
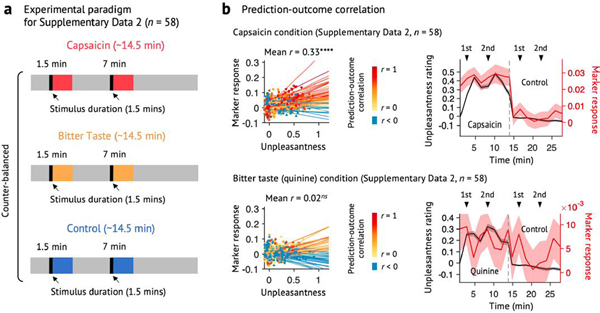
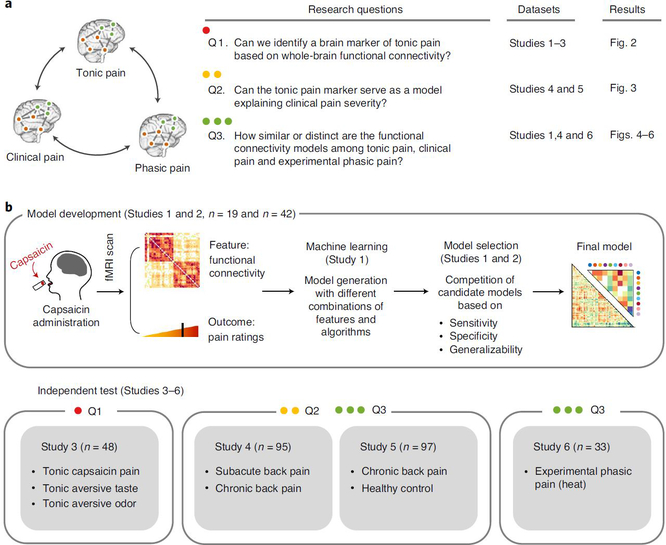
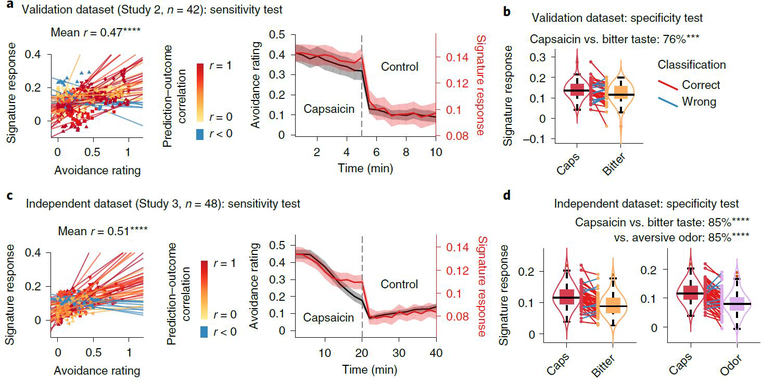
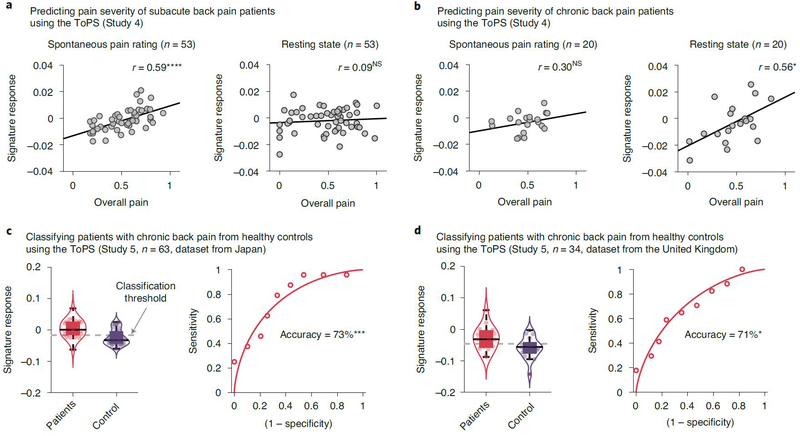
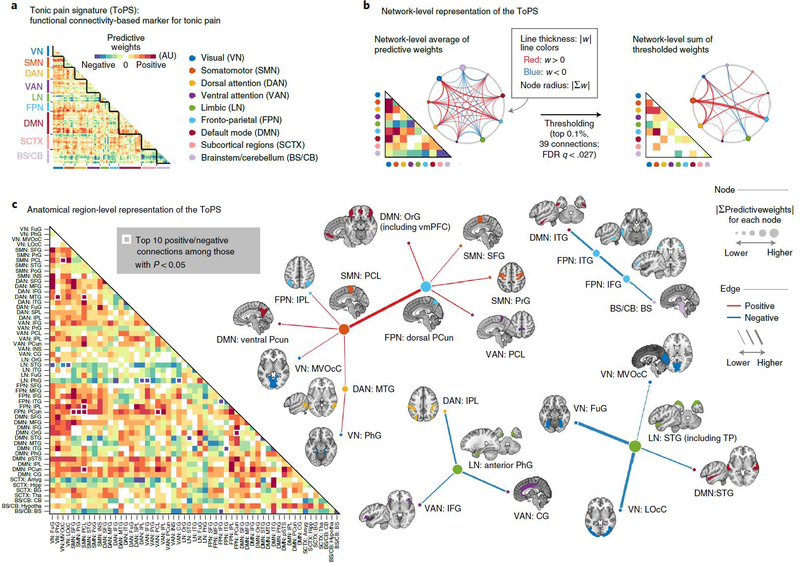
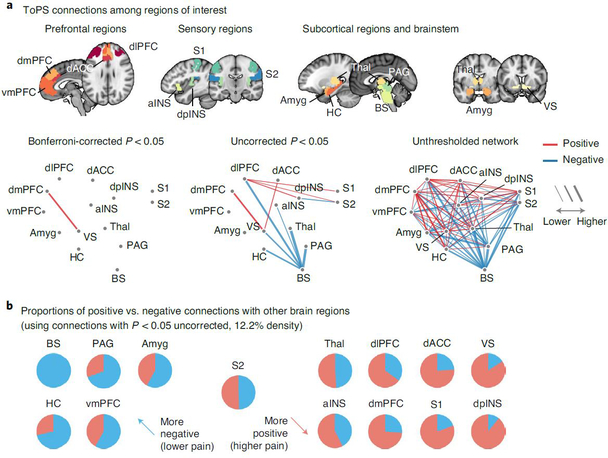
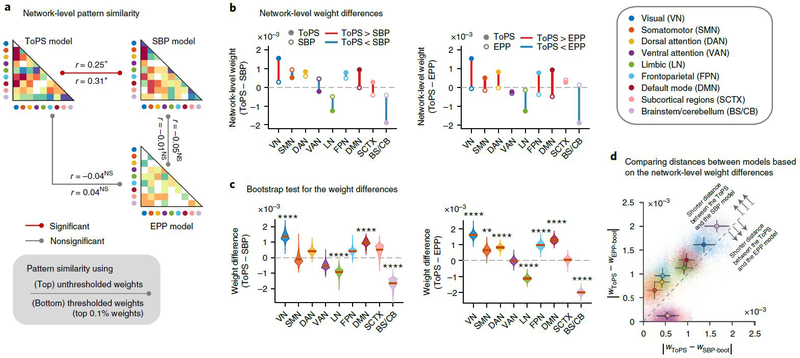
Sustained pain is a major characteristic of clinical pain disorders, but it is difficult to assess in isolation from co-occurring cognitive and emotional features in patients. In this study, we developed a functional magnetic resonance imaging signature based on whole-brain functional connectivity that tracks experimentally induced tonic pain intensity and tested its sensitivity, specificity and generalizability to clinical pain across six studies (total n = 334). The signature displayed high sensitivity and specificity to tonic pain across three independent studies of orofacial tonic pain and aversive taste. It also predicted clinical pain severity and classified patients versus controls in two independent studies of clinical low back pain. Tonic and clinical pain showed similar network-level representations, particularly in somatomotor, frontoparietal and dorsal attention networks. These patterns were distinct from representations of experimental phasic pain. This study identified a brain biomarker for sustained pain with high potential for clinical translation.
Conflict of interest statement
Competing interests
The authors declare no competing interests.
Figures
Comment in
-
Exploring Dynamic Connectivity Biomarkers of Neuropsychiatric Disorders.Trends Cogn Sci. 2021 May;25(5):336-338. doi: 10.1016/j.tics.2021.03.005. Epub 2021 Mar 12. Trends Cogn Sci. 2021. PMID: 33722480
References
Publication types
MeSH terms
Substances
Grants and funding
- 2019R1C1C1004512/National Research Foundation of Korea (NRF)/International
- R01DA035484/U.S. Department of Health & Human Services | NIH | National Institute on Drug Abuse (NIDA)/International
- R01MH076136/U.S. Department of Health & Human Services | NIH | National Institute of Mental Health (NIMH)/International
- R01 MH076136/MH/NIMH NIH HHS/United States
- R01 DA035484/DA/NIDA NIH HHS/United States
LinkOut - more resources
Full Text Sources
Other Literature Sources
