

Structural and functional characterization of the Spo11 core complex
- PMID: 33398171
- PMCID: PMC7855791
- DOI: 10.1038/s41594-020-00534-w
Structural and functional characterization of the Spo11 core complex
Abstract
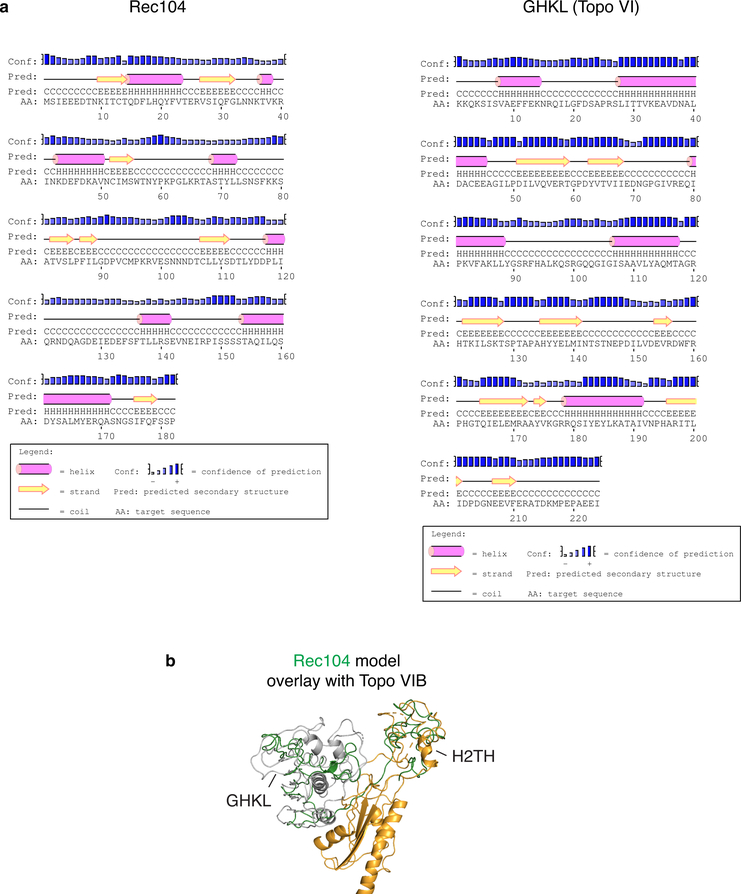
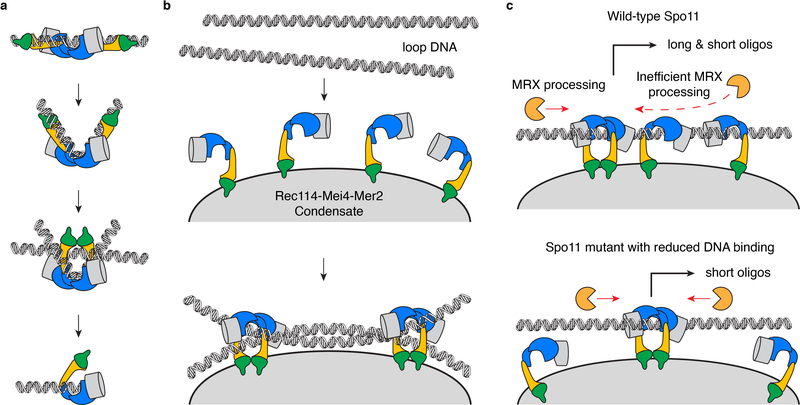
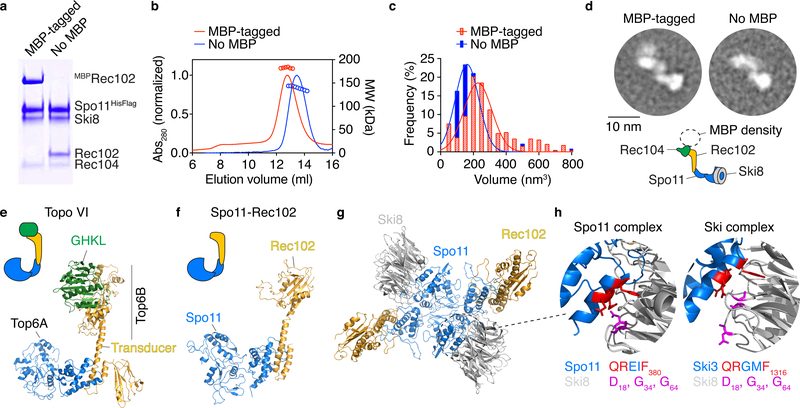
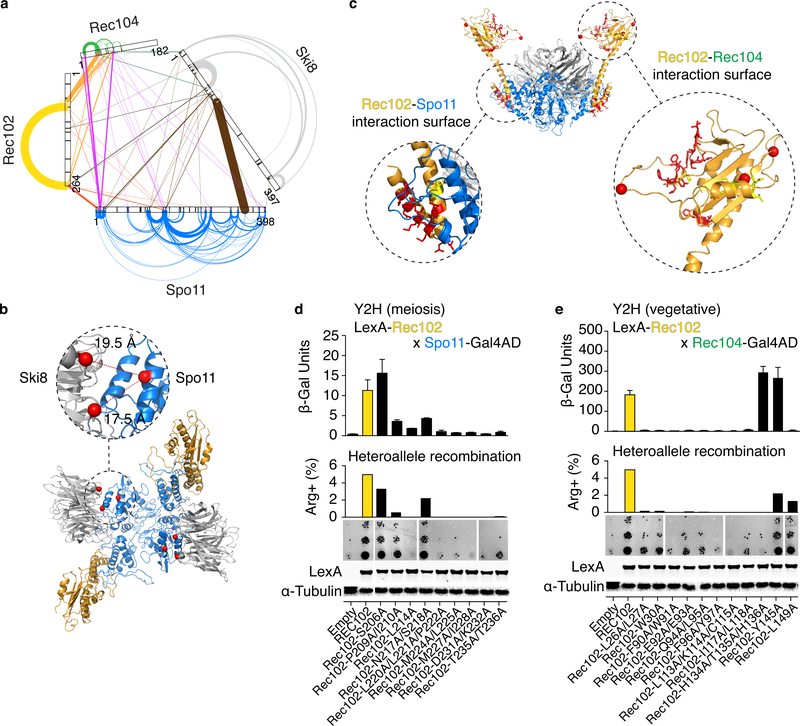
Spo11, which makes DNA double-strand breaks (DSBs) that are essential for meiotic recombination, has long been recalcitrant to biochemical study. We provide molecular analysis of Saccharomyces cerevisiae Spo11 purified with partners Rec102, Rec104 and Ski8. Rec102 and Rec104 jointly resemble the B subunit of archaeal topoisomerase VI, with Rec104 occupying a position similar to the Top6B GHKL-type ATPase domain. Unexpectedly, the Spo11 complex is monomeric (1:1:1:1 stoichiometry), consistent with dimerization controlling DSB formation. Reconstitution of DNA binding reveals topoisomerase-like preferences for duplex-duplex junctions and bent DNA. Spo11 also binds noncovalently but with high affinity to DNA ends mimicking cleavage products, suggesting a mechanism to cap DSB ends. Mutations that reduce DNA binding in vitro attenuate DSB formation, alter DSB processing and reshape the DSB landscape in vivo. Our data reveal structural and functional similarities between the Spo11 core complex and Topo VI, but also highlight differences reflecting their distinct biological roles.
Conflict of interest statement
Figures
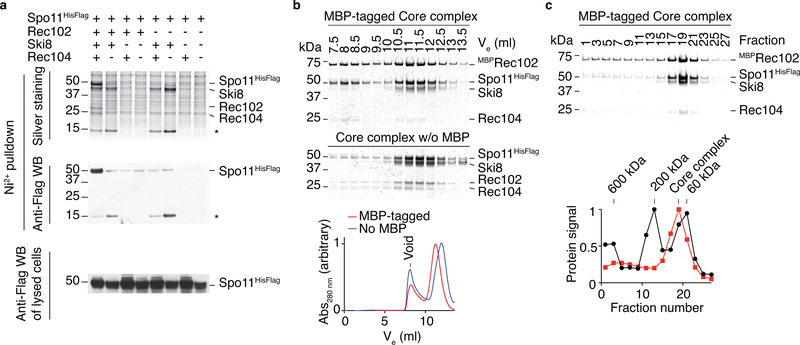
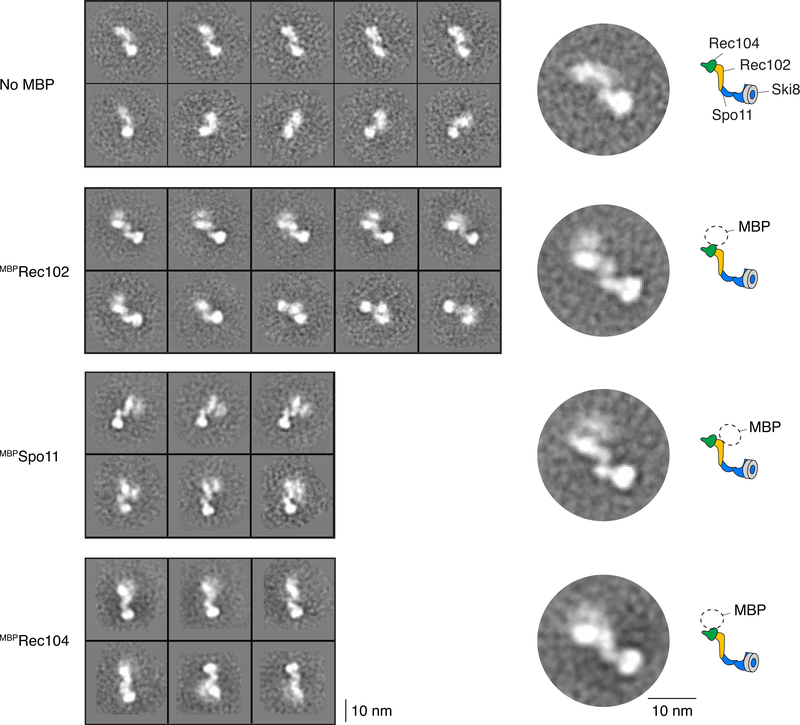
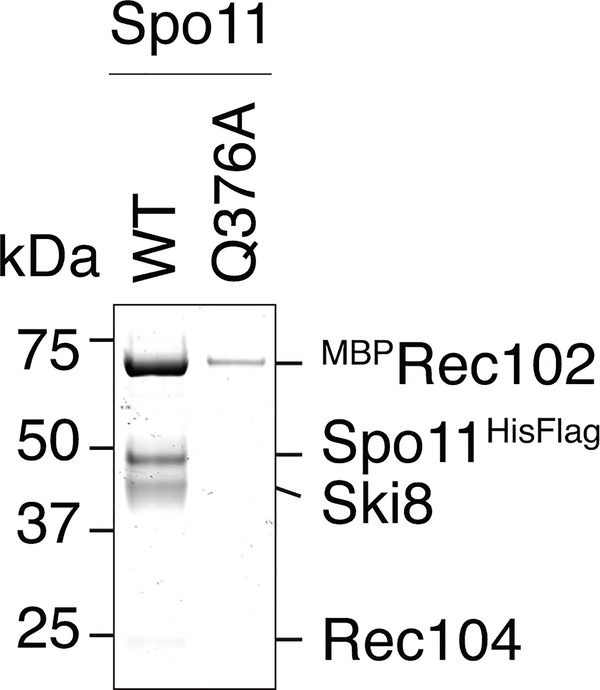
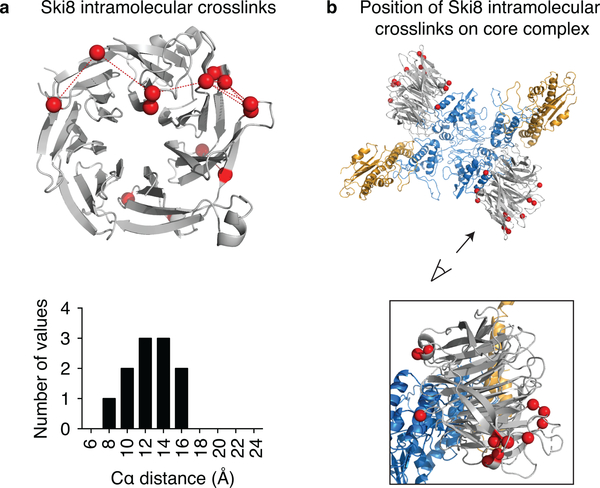
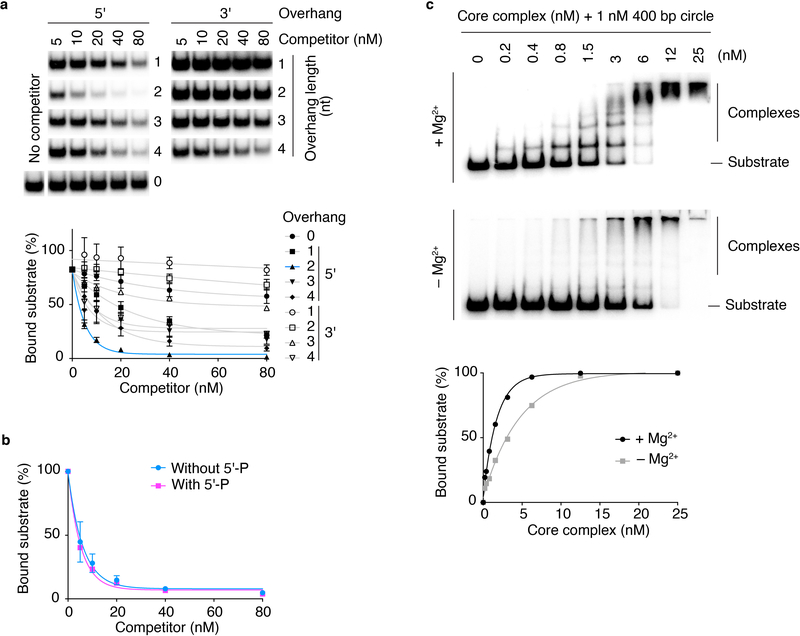
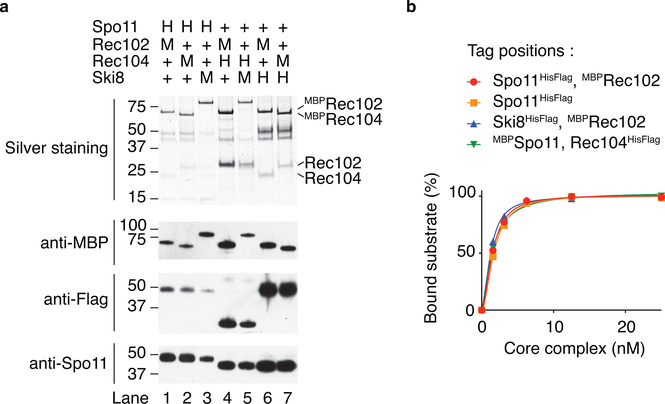
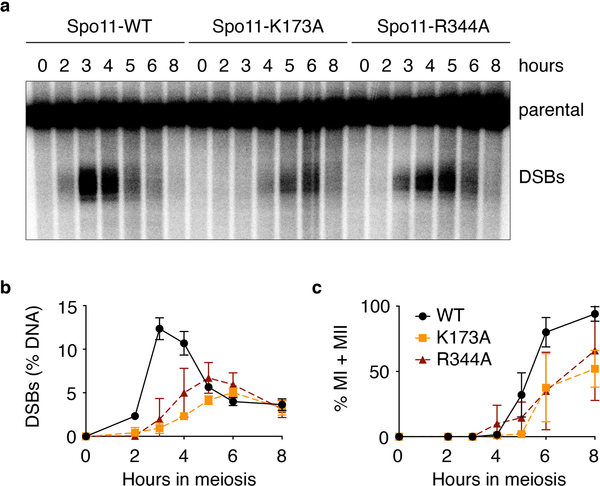
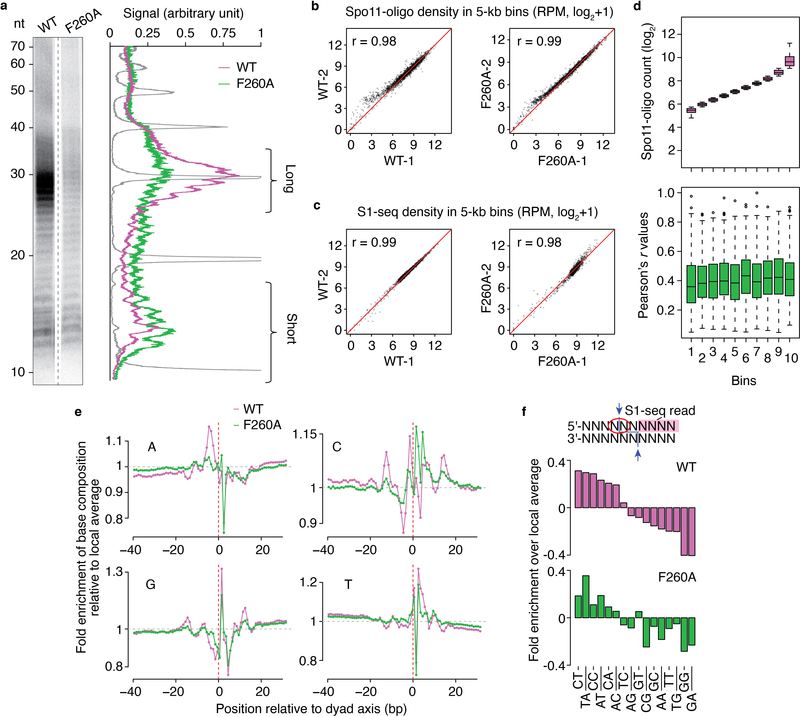
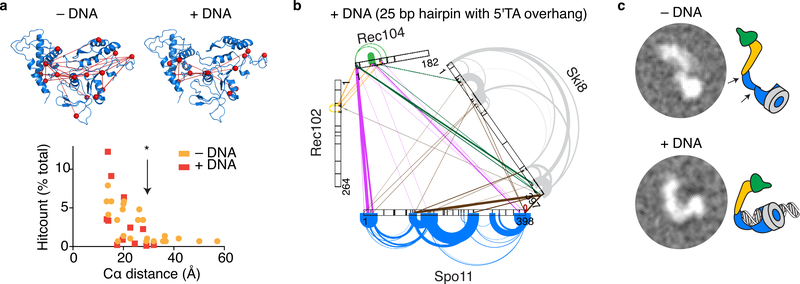
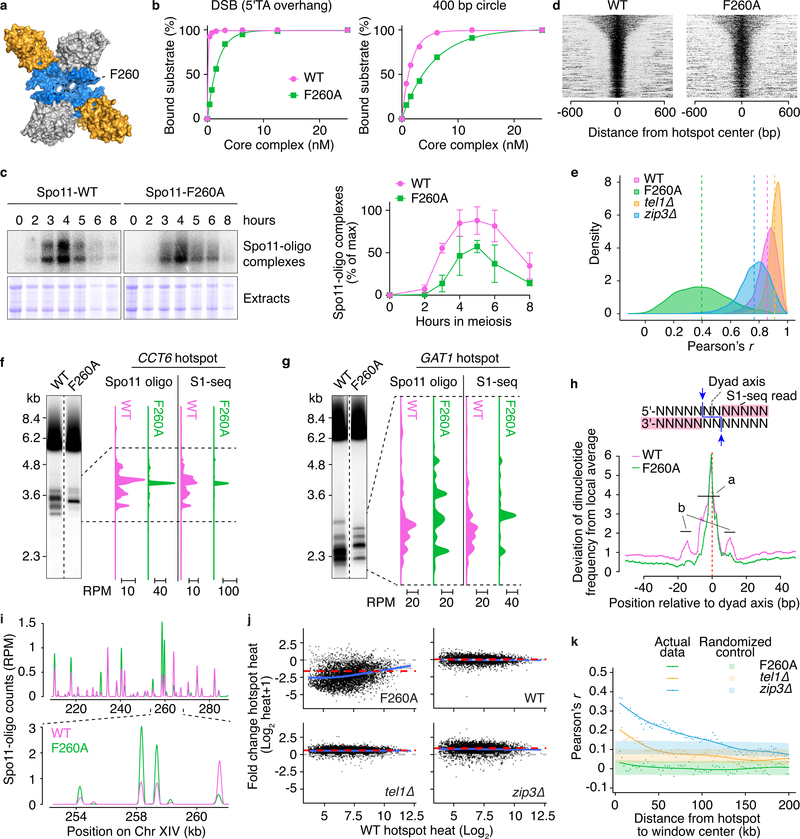
References
-
- Bergerat A et al. An atypical topoisomerase II from Archaea with implications for meiotic recombination. Nature 386, 414–7 (1997). - PubMed
-
- Keeney S, Giroux CN & Kleckner N Meiosis-specific DNA double-strand breaks are catalyzed by Spo11, a member of a widely conserved protein family. Cell 88, 375–84 (1997). - PubMed
-
- Corbett KD, Benedetti P & Berger JM Holoenzyme assembly and ATP-mediated conformational dynamics of topoisomerase VI. Nat Struct Mol Biol 14, 611–9 (2007). - PubMed
-
- Graille M et al. Crystal structure of an intact type II DNA topoisomerase: insights into DNA transfer mechanisms. Structure 16, 360–70 (2008). - PubMed
-
- Buhler C, Lebbink JH, Bocs C, Ladenstein R & Forterre P DNA topoisomerase VI generates ATP-dependent double-strand breaks with two-nucleotide overhangs. J Biol Chem 276, 37215–22 (2001). - PubMed
Methods-only References
-
- McGuffin LJ, Bryson K & Jones DT The PSIPRED protein structure prediction server. Bioinformatics 16, 404–5 (2000). - PubMed
-
- Richards FM Calculation of molecular volumes and areas for structures of known geometry. Methods Enzymol 115, 440–64 (1985). - PubMed
-
- Sebastiaan Winkler G et al. Isolation and mass spectrometry of transcription factor complexes. Methods 26, 260–9 (2002). - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Research Materials
Miscellaneous
