

Multicenter, Head-to-Head, Real-World Validation Study of Seven Automated Artificial Intelligence Diabetic Retinopathy Screening Systems
- PMID: 33402366
- PMCID: PMC8132324
- DOI: 10.2337/dc20-1877
Multicenter, Head-to-Head, Real-World Validation Study of Seven Automated Artificial Intelligence Diabetic Retinopathy Screening Systems
Abstract
Objective: With rising global prevalence of diabetic retinopathy (DR), automated DR screening is needed for primary care settings. Two automated artificial intelligence (AI)-based DR screening algorithms have U.S. Food and Drug Administration (FDA) approval. Several others are under consideration while in clinical use in other countries, but their real-world performance has not been evaluated systematically. We compared the performance of seven automated AI-based DR screening algorithms (including one FDA-approved algorithm) against human graders when analyzing real-world retinal imaging data.
Research design and methods: This was a multicenter, noninterventional device validation study evaluating a total of 311,604 retinal images from 23,724 veterans who presented for teleretinal DR screening at the Veterans Affairs (VA) Puget Sound Health Care System (HCS) or Atlanta VA HCS from 2006 to 2018. Five companies provided seven algorithms, including one with FDA approval, that independently analyzed all scans, regardless of image quality. The sensitivity/specificity of each algorithm when classifying images as referable DR or not were compared with original VA teleretinal grades and a regraded arbitrated data set. Value per encounter was estimated.
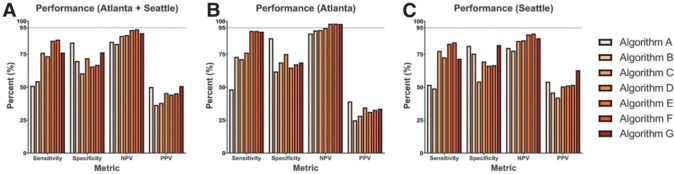
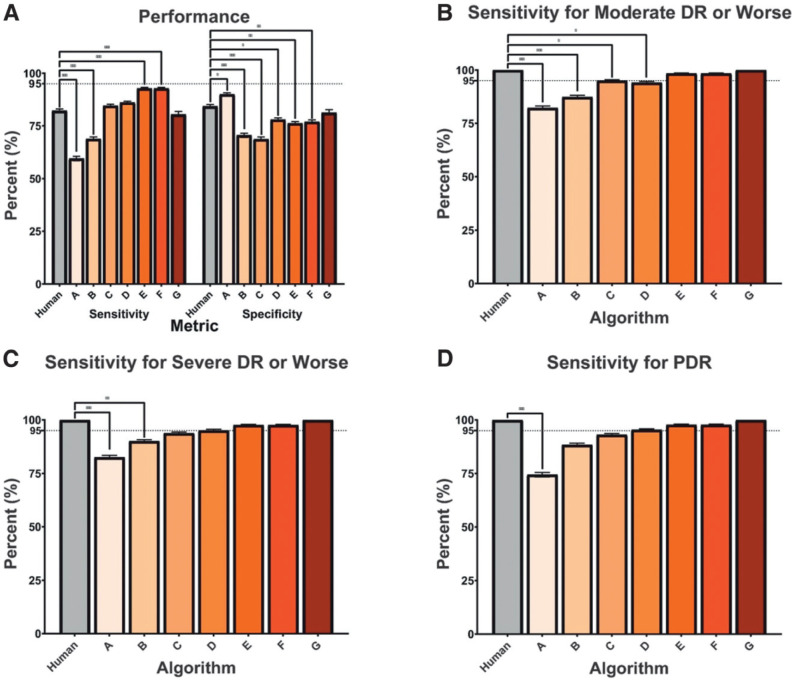
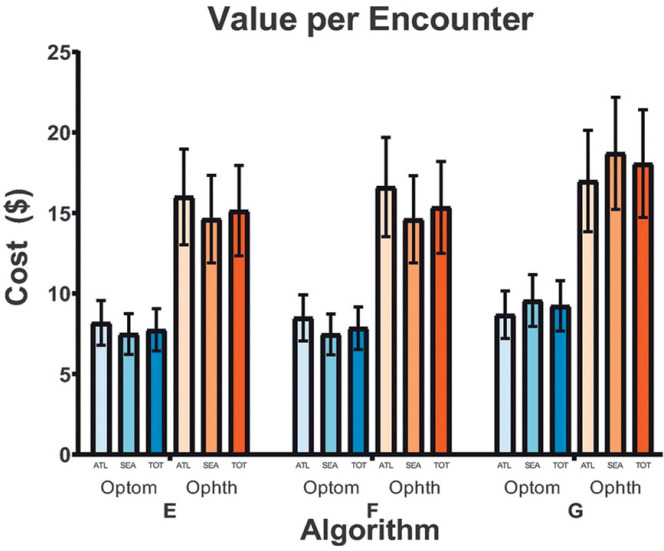
Results: Although high negative predictive values (82.72-93.69%) were observed, sensitivities varied widely (50.98-85.90%). Most algorithms performed no better than humans against the arbitrated data set, but two achieved higher sensitivities, and one yielded comparable sensitivity (80.47%, P = 0.441) and specificity (81.28%, P = 0.195). Notably, one had lower sensitivity (74.42%) for proliferative DR (P = 9.77 × 10-4) than the VA teleretinal graders. Value per encounter varied at $15.14-$18.06 for ophthalmologists and $7.74-$9.24 for optometrists.
Conclusions: The DR screening algorithms showed significant performance differences. These results argue for rigorous testing of all such algorithms on real-world data before clinical implementation.
© 2021 by the American Diabetes Association.
Figures
Comment in
-
Comment on Lee et al. Multicenter, Head-to-Head, Real-World Validation Study of Seven Automated Artificial Intelligence Diabetic Retinopathy Screening Systems. Diabetes Care 2021;44:1168-1175.Diabetes Care. 2021 May;44(5):e107. doi: 10.2337/dc21-0151. Diabetes Care. 2021. PMID: 33972324 Free PMC article. No abstract available.
-
Multicenter, Head-to-Head, Real-World Validation Study of Seven Automated Artificial Intelligence Diabetic Retinopathy Screening Systems. Diabetes Care 2021;44:XXXX-XXXX.Diabetes Care. 2021 May;44(5):e108-e109. doi: 10.2337/dci21-0007. Diabetes Care. 2021. PMID: 33972325 Free PMC article. No abstract available.
References
-
- Jampol LM, Glassman AR, Sun J. Evaluation and care of patients with diabetic retinopathy. N Engl J Med 2020;382:1629–1637 - PubMed
-
- Flaxel CJ, Adelman RA, Bailey ST, et al. Diabetic retinopathy preferred practice pattern®. Ophthalmology 2020;127:66–P145 - PubMed
-
- American Diabetes Association . 11. Microvascular complications and foot care: Standards of Medical Care in Diabetes—2020. Diabetes Care 2020;43(Suppl. 1):S135–S151 - PubMed
Publication types
MeSH terms
Associated data
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
