

Industry-scale application and evaluation of deep learning for drug target prediction
- PMID: 33430964
- PMCID: PMC7169028
- DOI: 10.1186/s13321-020-00428-5
Industry-scale application and evaluation of deep learning for drug target prediction
Abstract
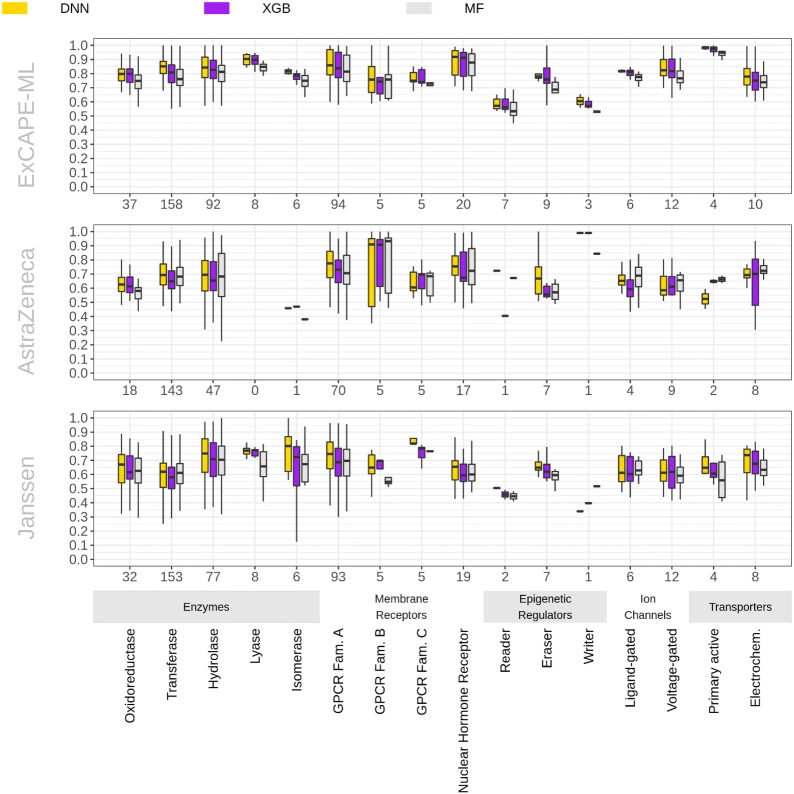
Artificial intelligence (AI) is undergoing a revolution thanks to the breakthroughs of machine learning algorithms in computer vision, speech recognition, natural language processing and generative modelling. Recent works on publicly available pharmaceutical data showed that AI methods are highly promising for Drug Target prediction. However, the quality of public data might be different than that of industry data due to different labs reporting measurements, different measurement techniques, fewer samples and less diverse and specialized assays. As part of a European funded project (ExCAPE), that brought together expertise from pharmaceutical industry, machine learning, and high-performance computing, we investigated how well machine learning models obtained from public data can be transferred to internal pharmaceutical industry data. Our results show that machine learning models trained on public data can indeed maintain their predictive power to a large degree when applied to industry data. Moreover, we observed that deep learning derived machine learning models outperformed comparable models, which were trained by other machine learning algorithms, when applied to internal pharmaceutical company datasets. To our knowledge, this is the first large-scale study evaluating the potential of machine learning and especially deep learning directly at the level of industry-scale settings and moreover investigating the transferability of publicly learned target prediction models towards industrial bioactivity prediction pipelines.
Keywords: Big data; ChEMBL; Cheminformatics; Deep learning; Machine learning; Prospective evaluation; PubChem; QSAR; Retrospective evaluation; Structure-based virtual screening.
Conflict of interest statement
The authors declare no competing interests.
Figures
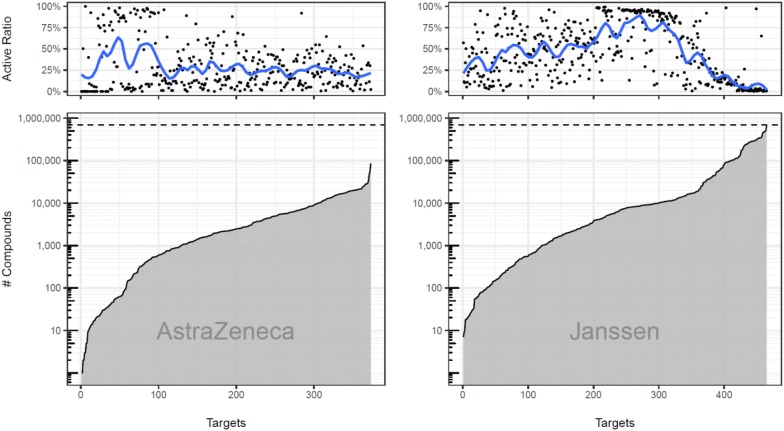
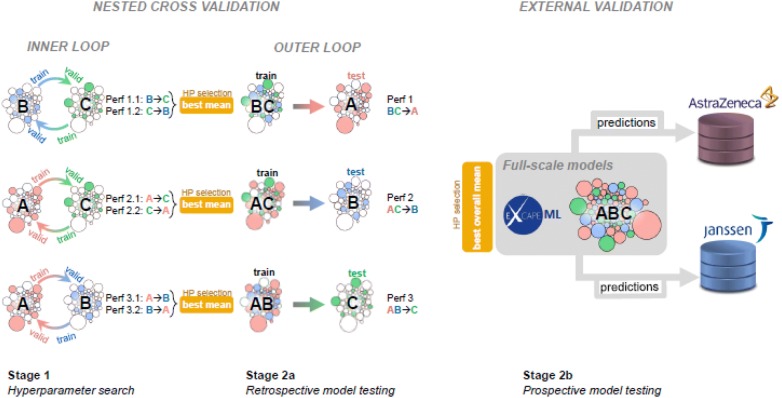
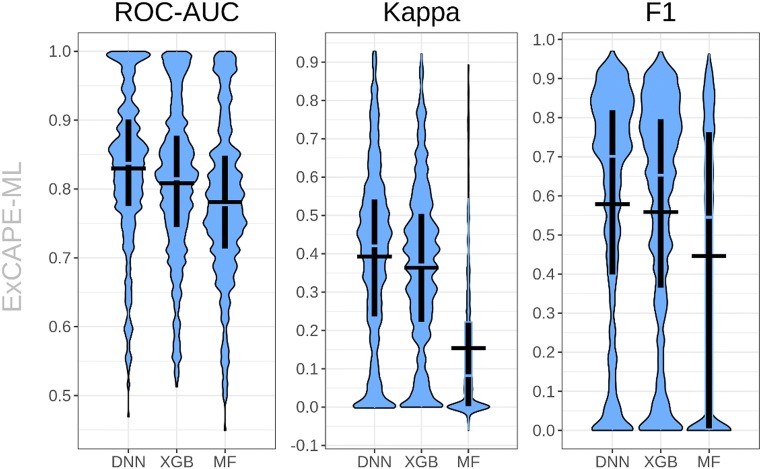
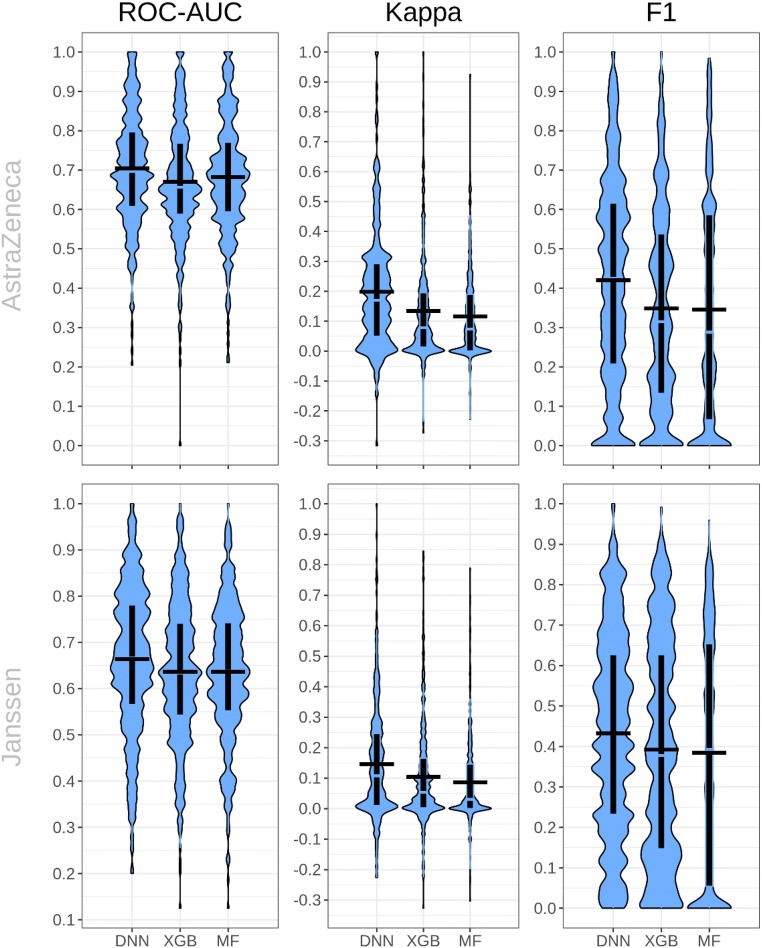
References
-
- Wang L, Ding J, Pan L, et al. Artificial intelligence facilitates drug design in the big data era. Chemometrics Intell Lab Syst. 2019;194:103850. doi: 10.1016/j.chemolab.2019.103850. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
