

Robust breast cancer detection in mammography and digital breast tomosynthesis using an annotation-efficient deep learning approach
- PMID: 33432172
- PMCID: PMC9426656
- DOI: 10.1038/s41591-020-01174-9
Robust breast cancer detection in mammography and digital breast tomosynthesis using an annotation-efficient deep learning approach
Abstract
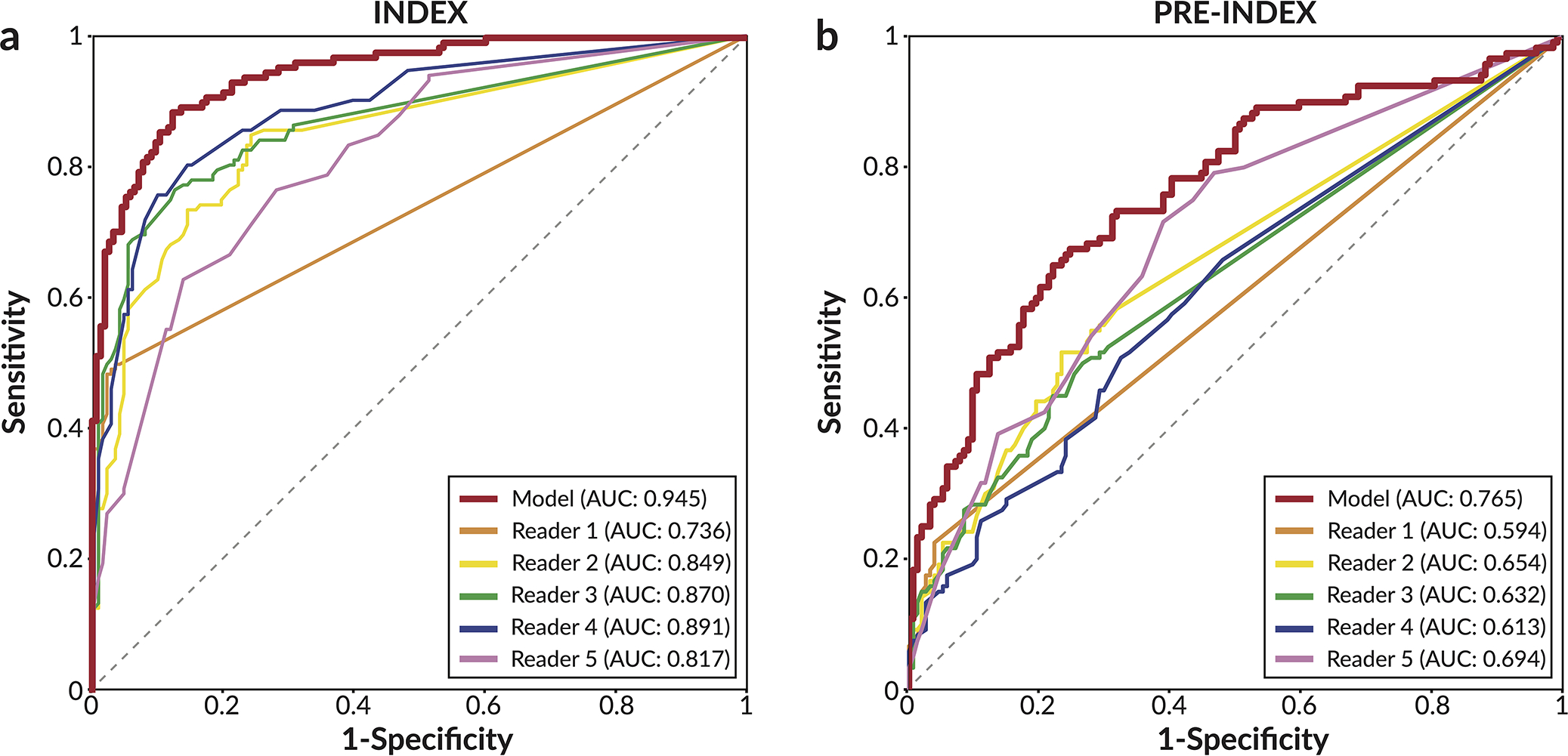
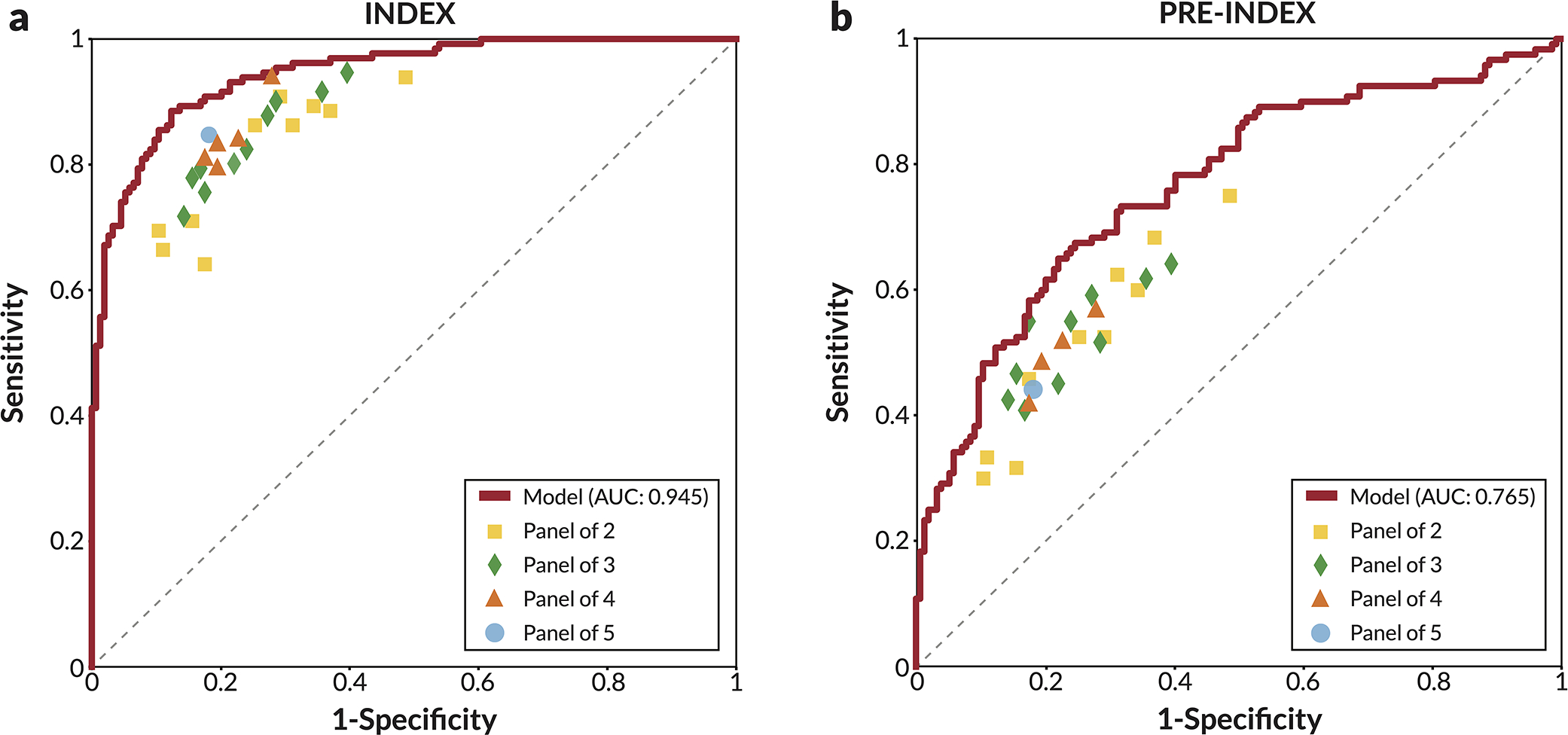
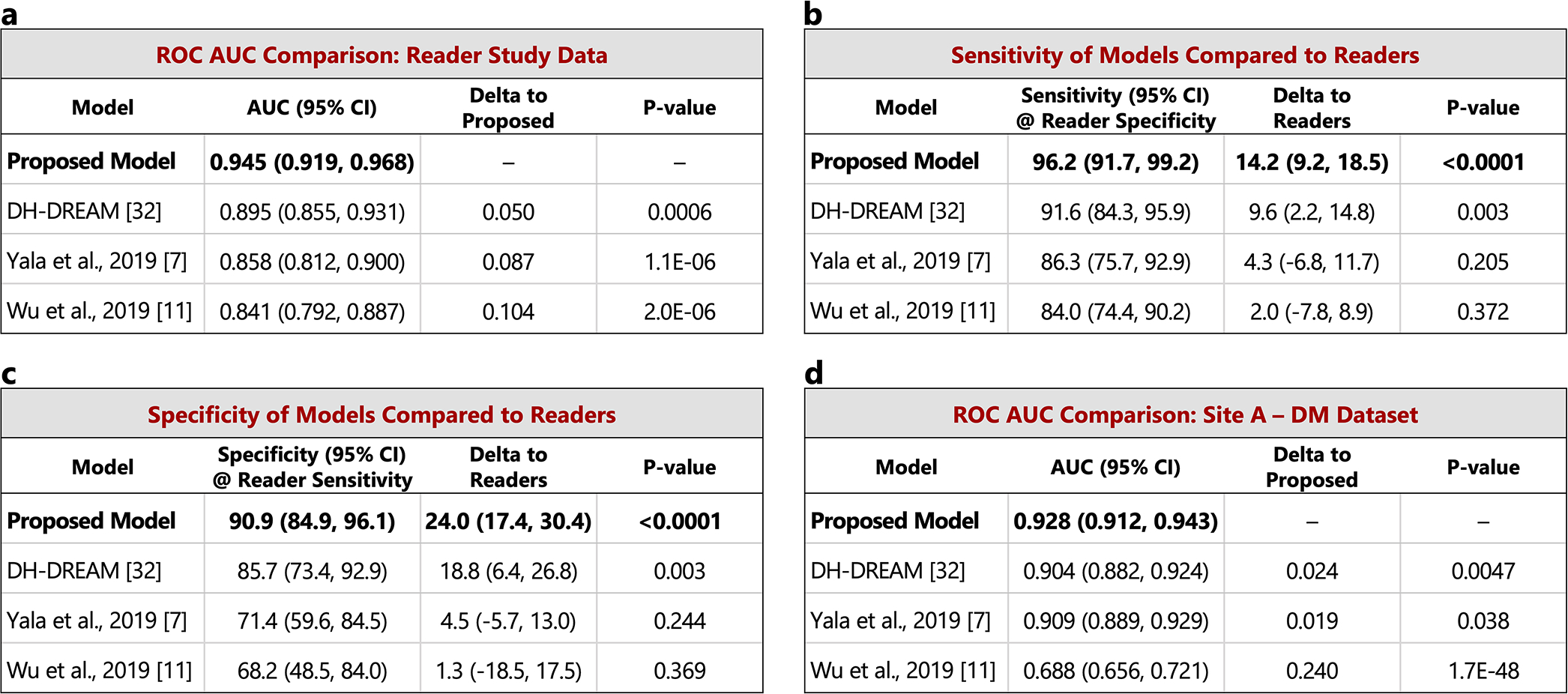
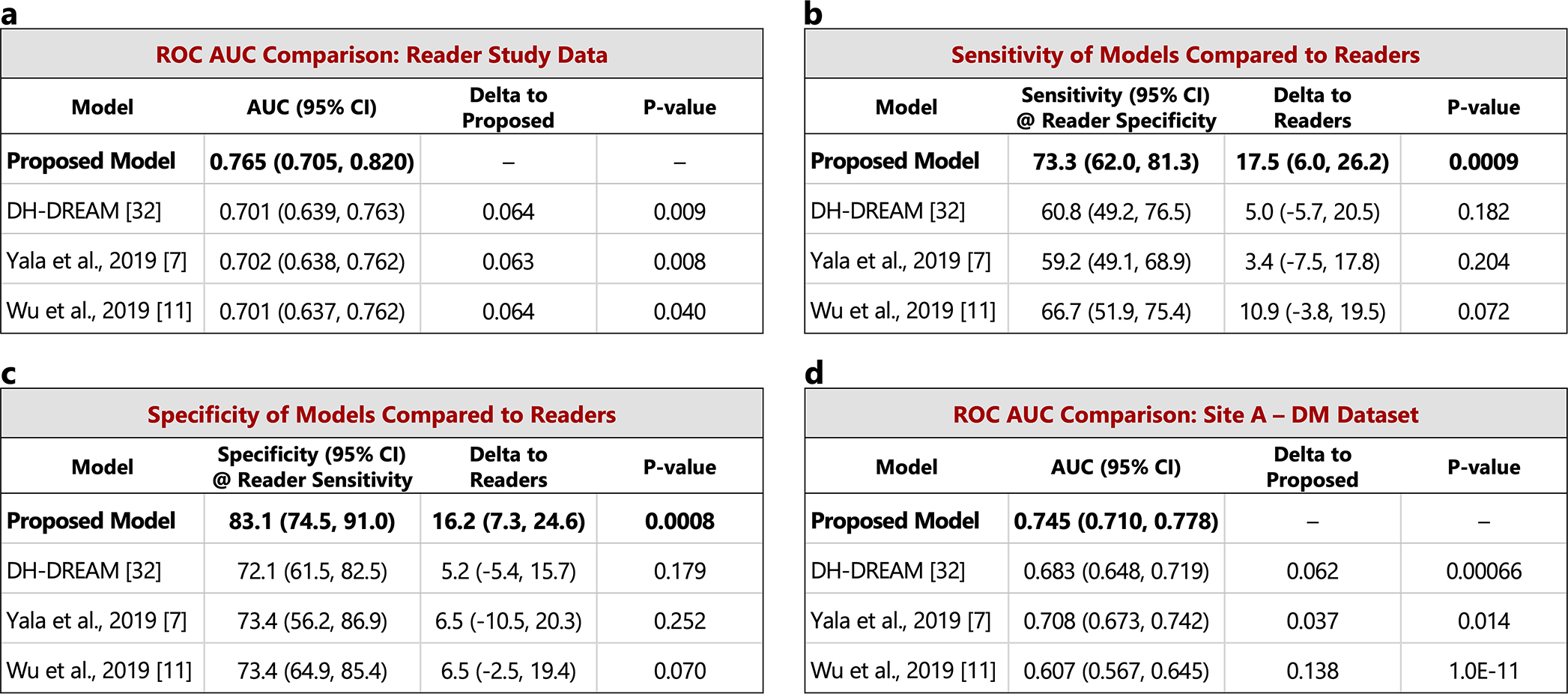
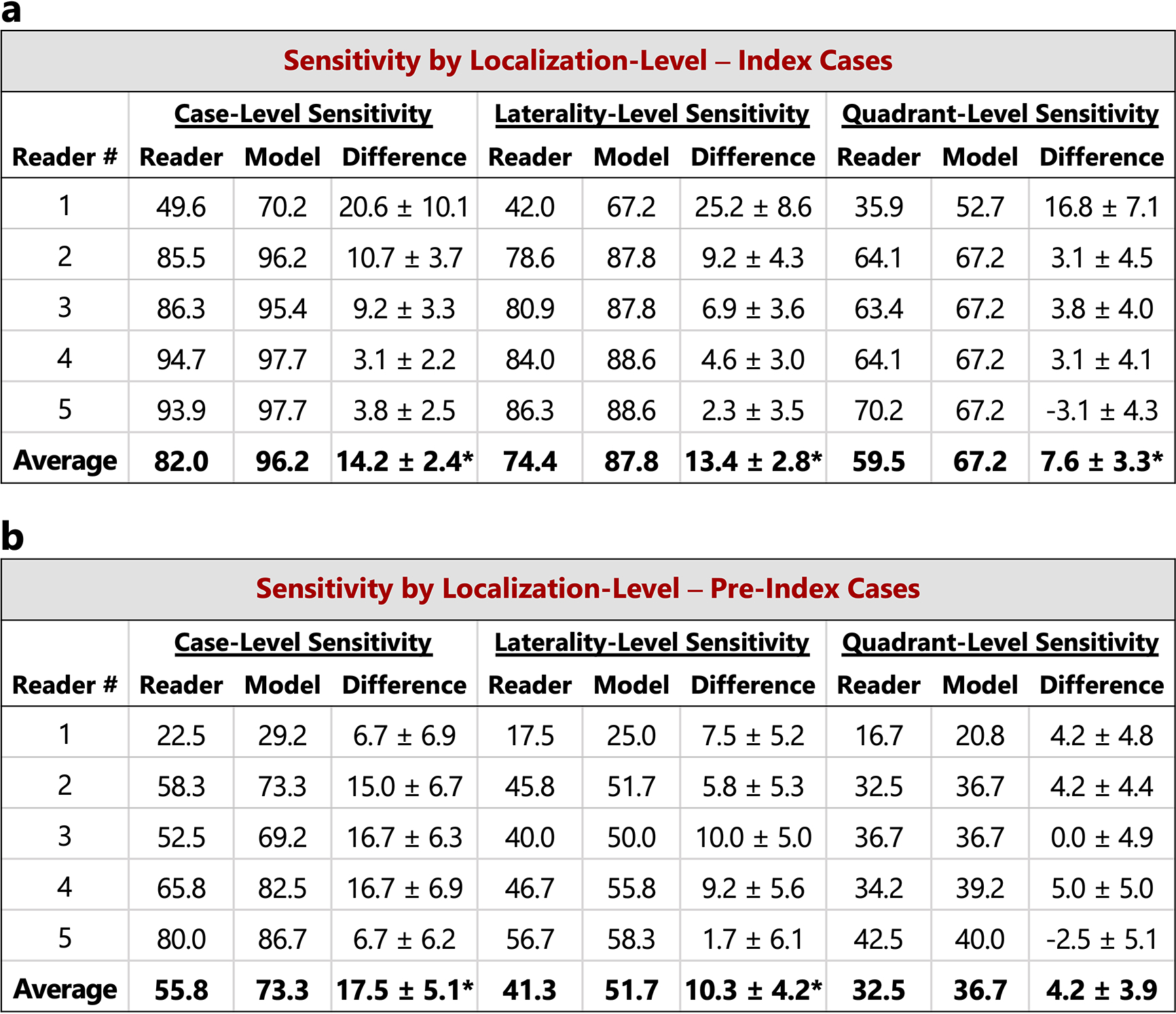
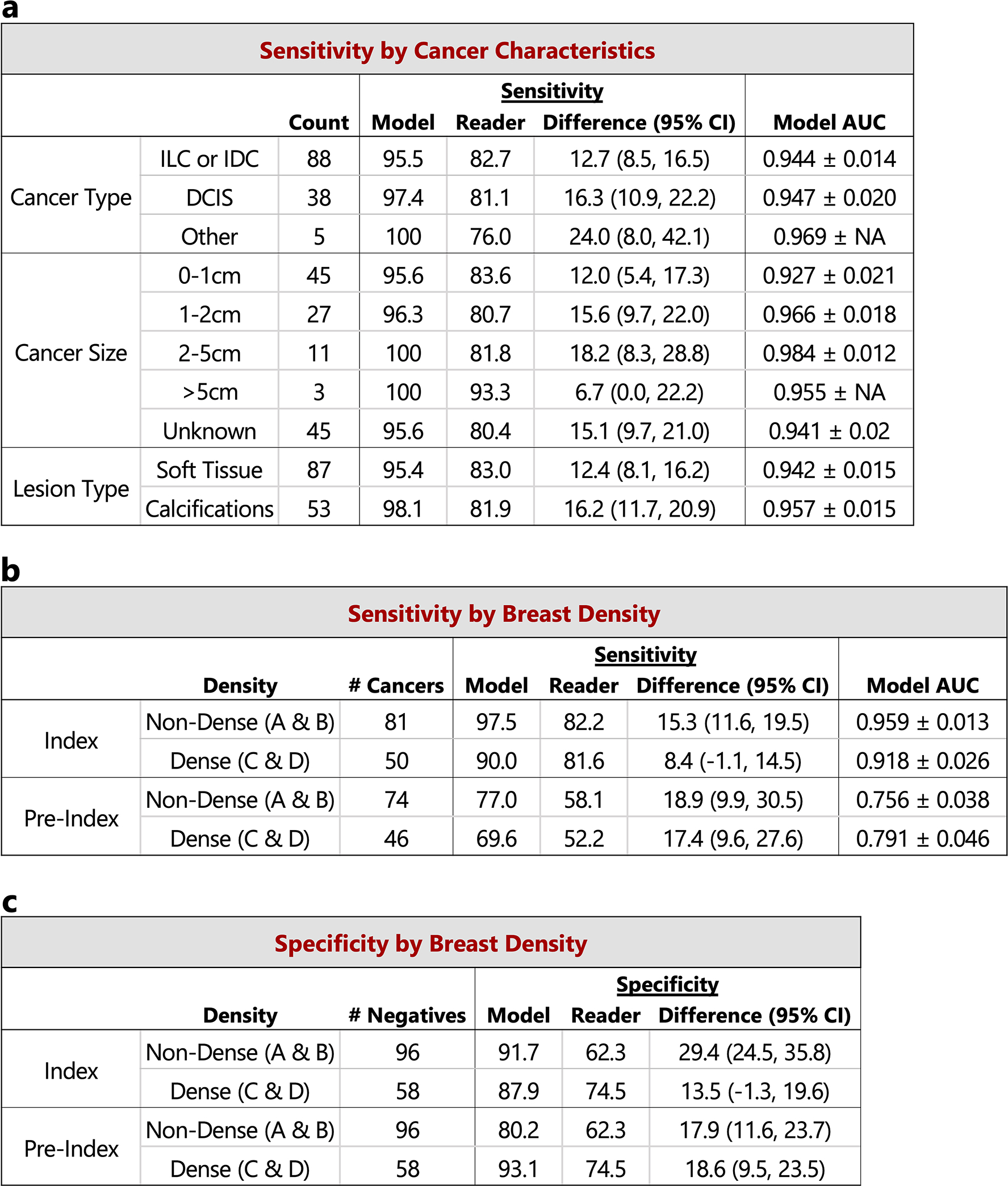
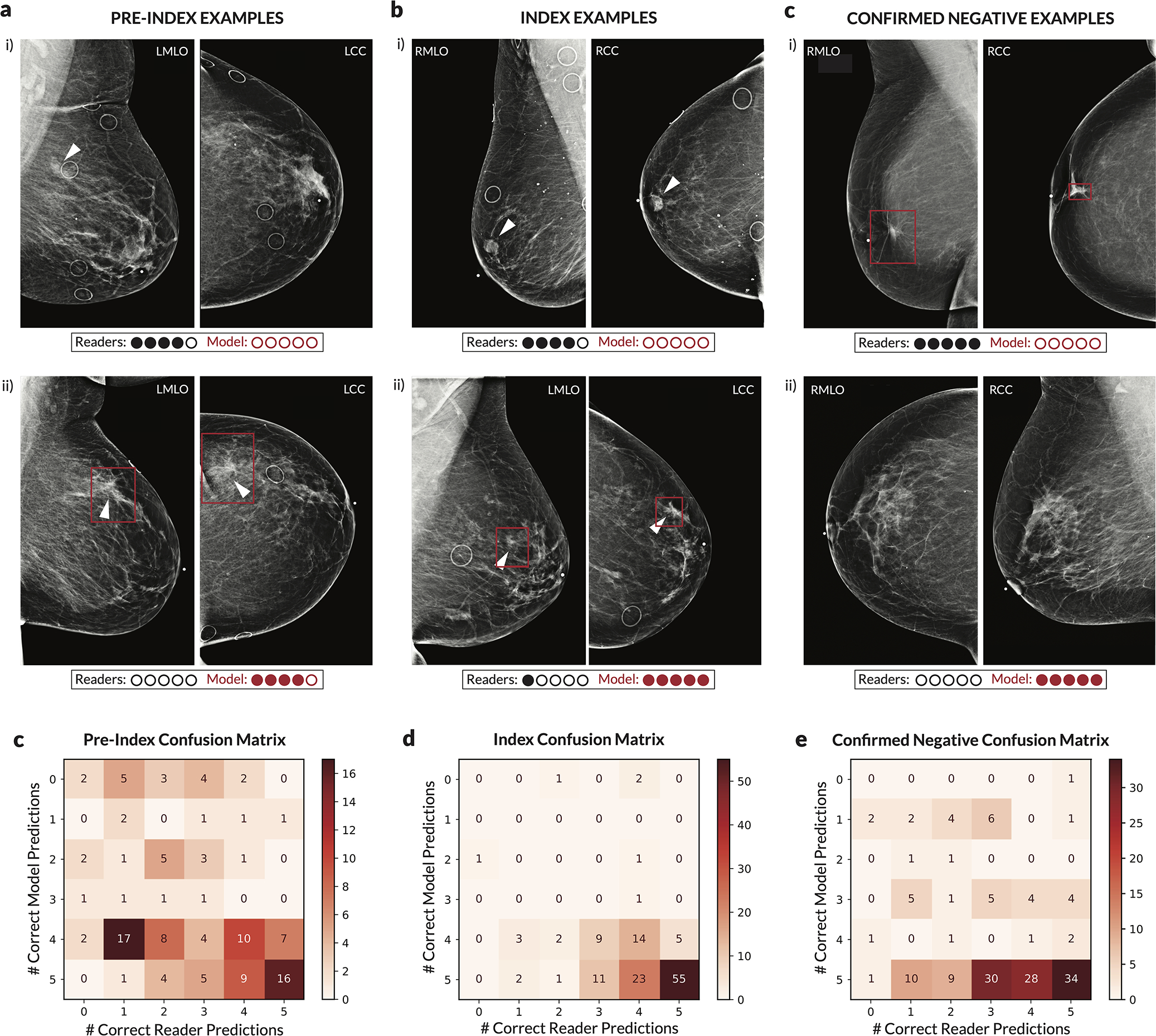
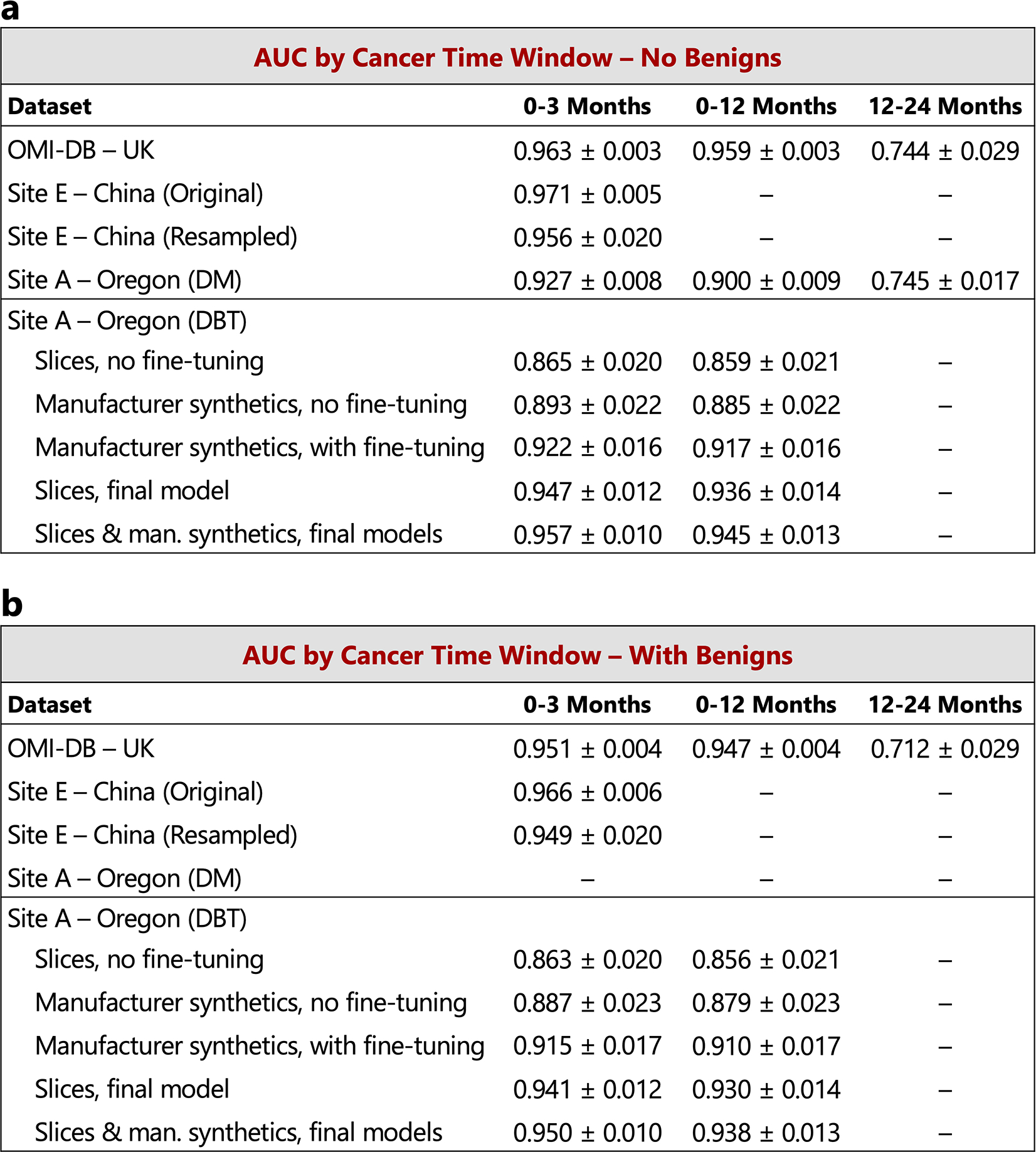
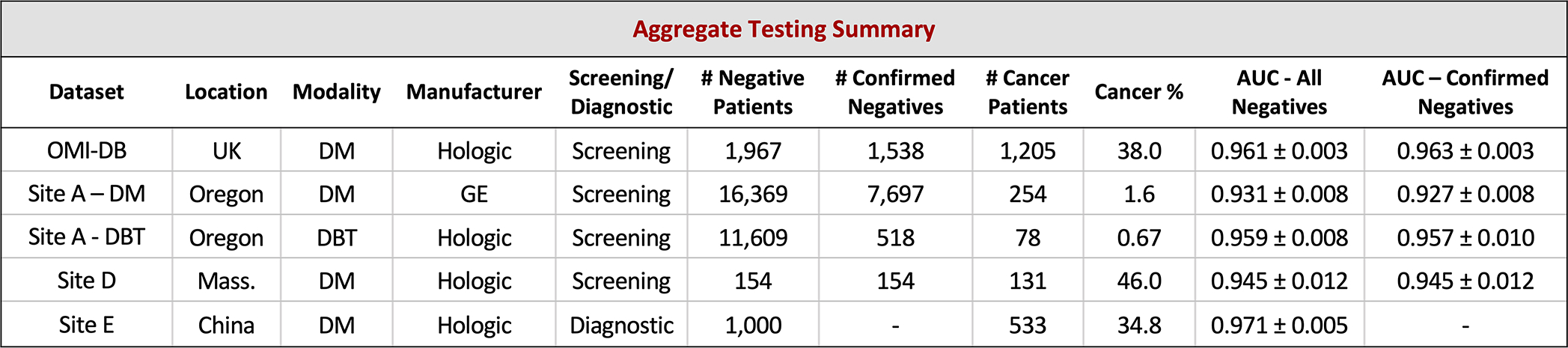
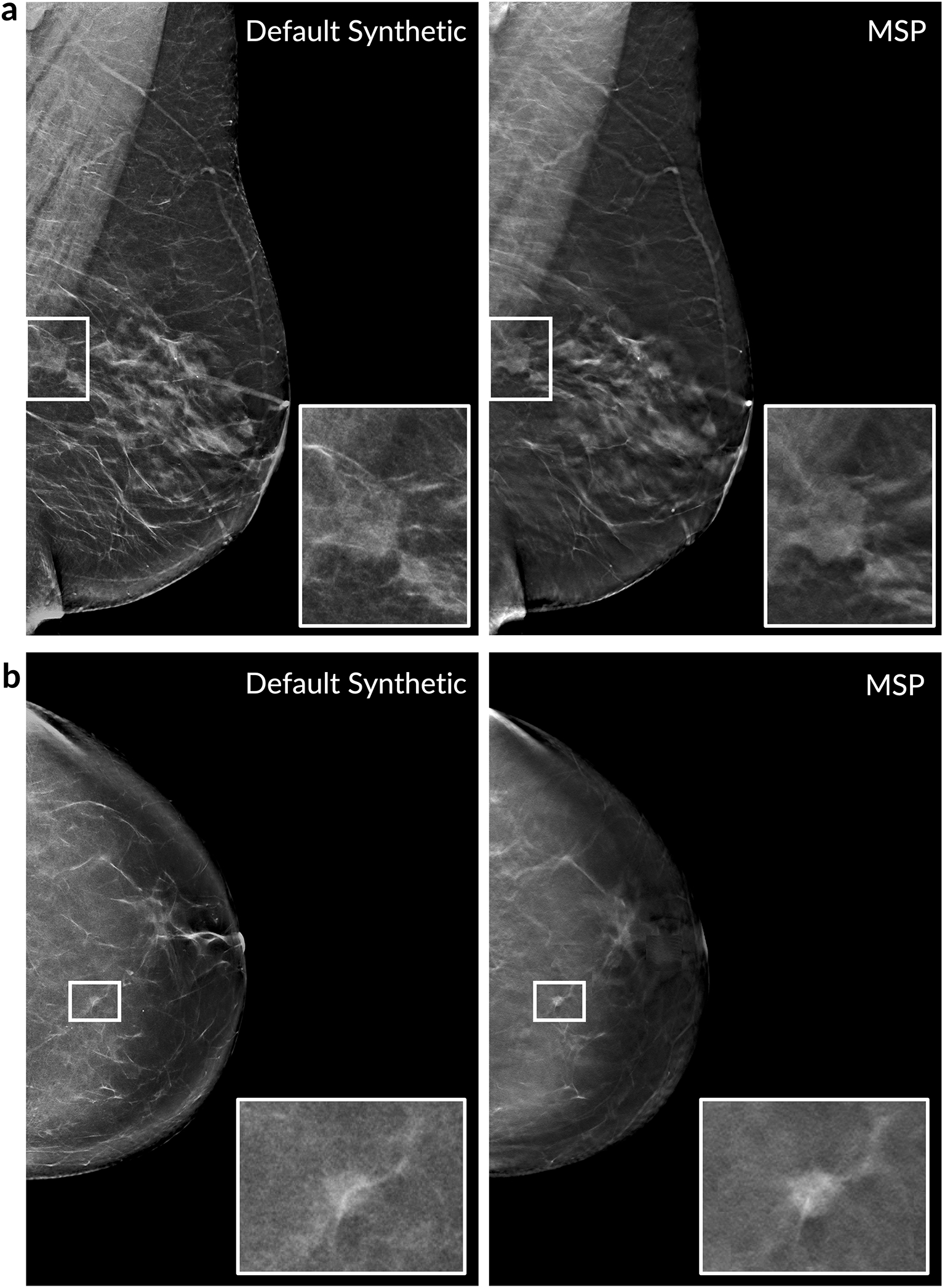
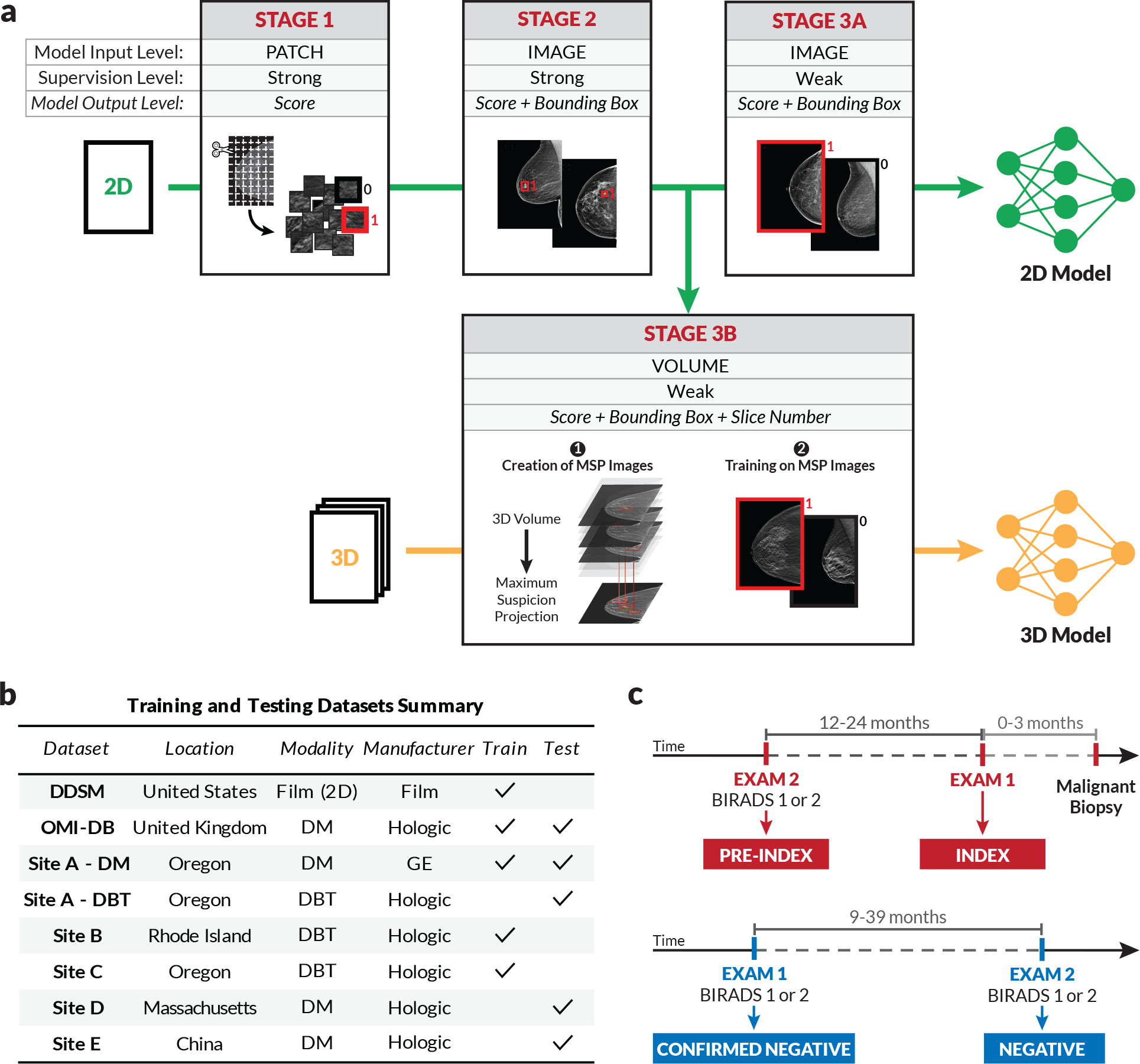
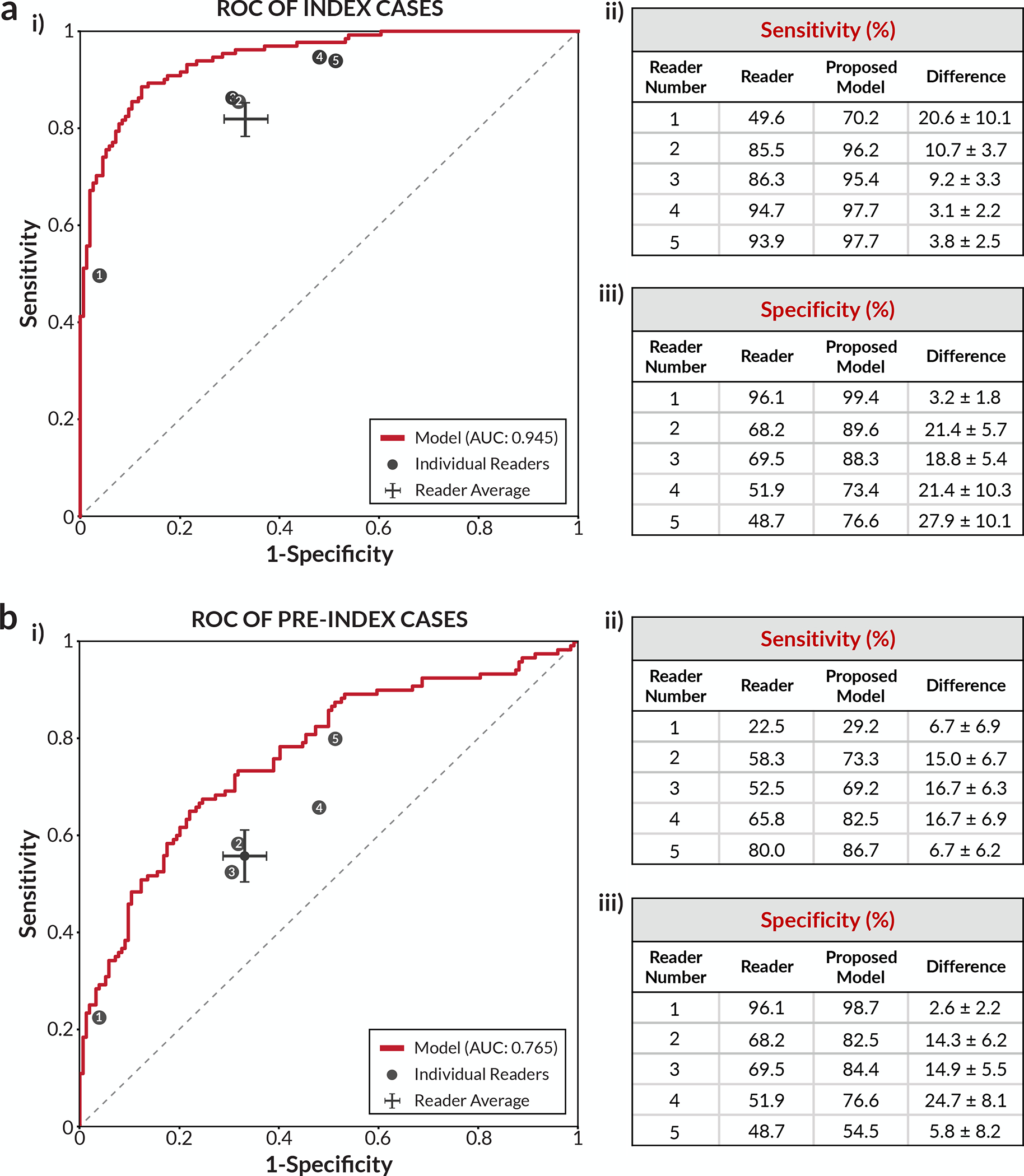
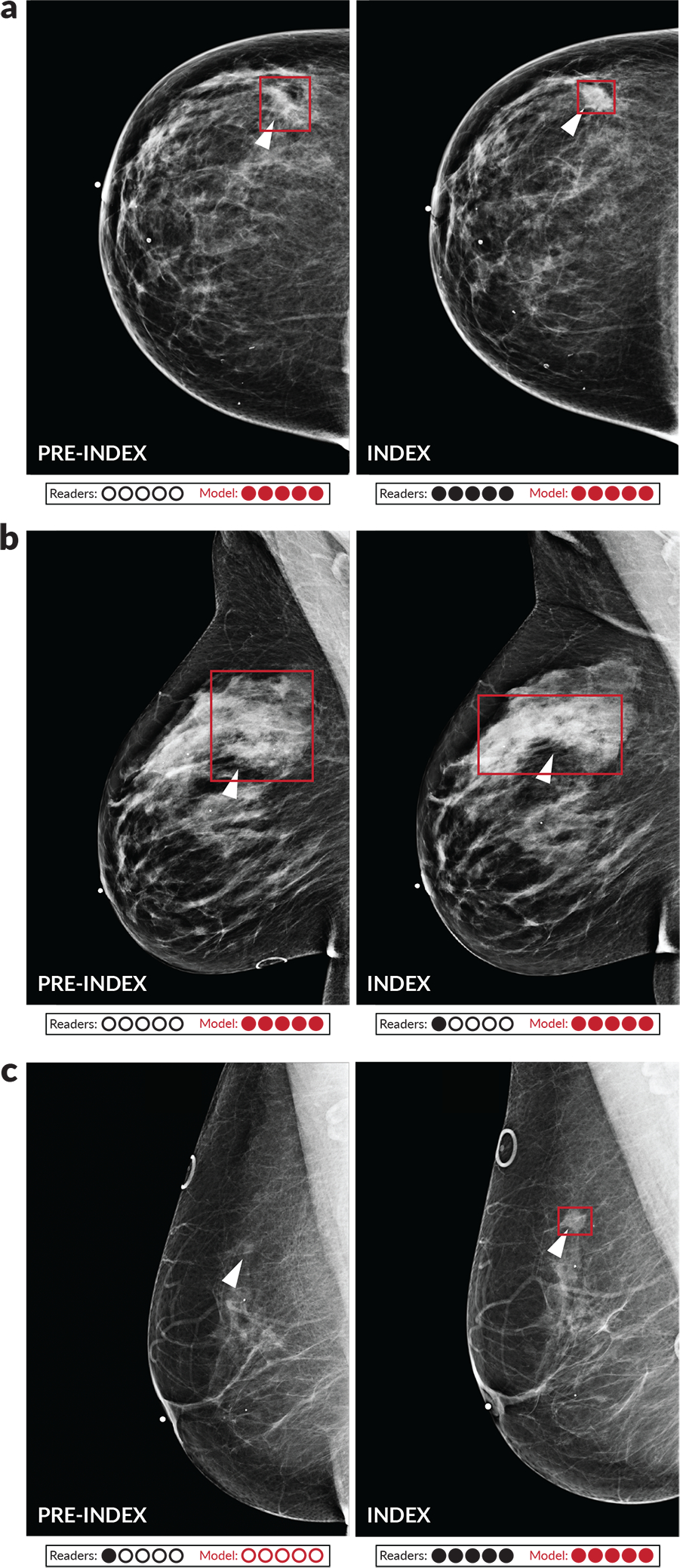
Breast cancer remains a global challenge, causing over 600,000 deaths in 2018 (ref. 1). To achieve earlier cancer detection, health organizations worldwide recommend screening mammography, which is estimated to decrease breast cancer mortality by 20-40% (refs. 2,3). Despite the clear value of screening mammography, significant false positive and false negative rates along with non-uniformities in expert reader availability leave opportunities for improving quality and access4,5. To address these limitations, there has been much recent interest in applying deep learning to mammography6-18, and these efforts have highlighted two key difficulties: obtaining large amounts of annotated training data and ensuring generalization across populations, acquisition equipment and modalities. Here we present an annotation-efficient deep learning approach that (1) achieves state-of-the-art performance in mammogram classification, (2) successfully extends to digital breast tomosynthesis (DBT; '3D mammography'), (3) detects cancers in clinically negative prior mammograms of patients with cancer, (4) generalizes well to a population with low screening rates and (5) outperforms five out of five full-time breast-imaging specialists with an average increase in sensitivity of 14%. By creating new 'maximum suspicion projection' (MSP) images from DBT data, our progressively trained, multiple-instance learning approach effectively trains on DBT exams using only breast-level labels while maintaining localization-based interpretability. Altogether, our results demonstrate promise towards software that can improve the accuracy of and access to screening mammography worldwide.
Conflict of interest statement
Competing Interests Statement
W.L., A.R.D., B.H., J.G.K., G.G., J.O.O., Y.B., and A.G.S. are employees of RadNet Inc., the parent company of DeepHealth Inc. M.B. serves as a consultant for DeepHealth Inc. Two patent disclosures have been filed related to the study methods under inventor W.L.
Figures
References
-
- Bray F, Ferlay J, Soerjomataram I, Siegel RL, Torre LA, and Jemal A Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA: A Cancer Journal for Clinicians 68(6), 394–424 (2018). - PubMed
-
- Berry DA, Cronin KA, Plevritis SK, Fryback DG, Clarke L, Zelen M, Mandelblatt JS, Yakovlev AY, Habbema JDF, and Feuer EJ Effect of screening and adjuvant therapy on mortality from breast cancer. New England Journal of Medicine 353(17), 1784–1792 (2005). - PubMed
-
- Majid AS, Shaw De Paredes E, Doherty RD, Sharma NR, and Salvador X Missed breast carcinoma: pitfalls and pearls. RadioGraphics 23, 881–895 (2003). - PubMed
-
- Rosenberg RD, Yankaskas BC, Abraham LA, Sickles EA, Lehman CD, Geller BM, Carney PA, Kerlikowske K, Buist DS, Weaver DL, Barlow WE, and Ballard-Barbash R Performance benchmarks for screening mammography. Radiology 241(1), 55–66 (2006). - PubMed
METHODS-ONLY REFERENCES
-
- Otsu N A Threshold Selection Method from Gray-Level Histograms. IEEE Transactions on Systems, Man, and Cybernetics 9(1), 62–66 (1979).
-
- He K, Zhang X, Ren S, and Sun J Deep Residual Learning for Image Recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778, (2016).
-
- Kingma DP and Ba J Adam: a method for stochastic optimization. In The 3rd International Conference on Learning Representations (ICLR) (2015).
-
- Lin T, Goyal P, Girshick R, He K, and Dollár P Focal loss for dense object detection. In The IEEE International Conference on Computer Vision (ICCV), 2999–3007, (2017).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Research Materials
