

Deep learning encodes robust discriminative neuroimaging representations to outperform standard machine learning
- PMID: 33441557
- PMCID: PMC7806588
- DOI: 10.1038/s41467-020-20655-6
Deep learning encodes robust discriminative neuroimaging representations to outperform standard machine learning
Abstract
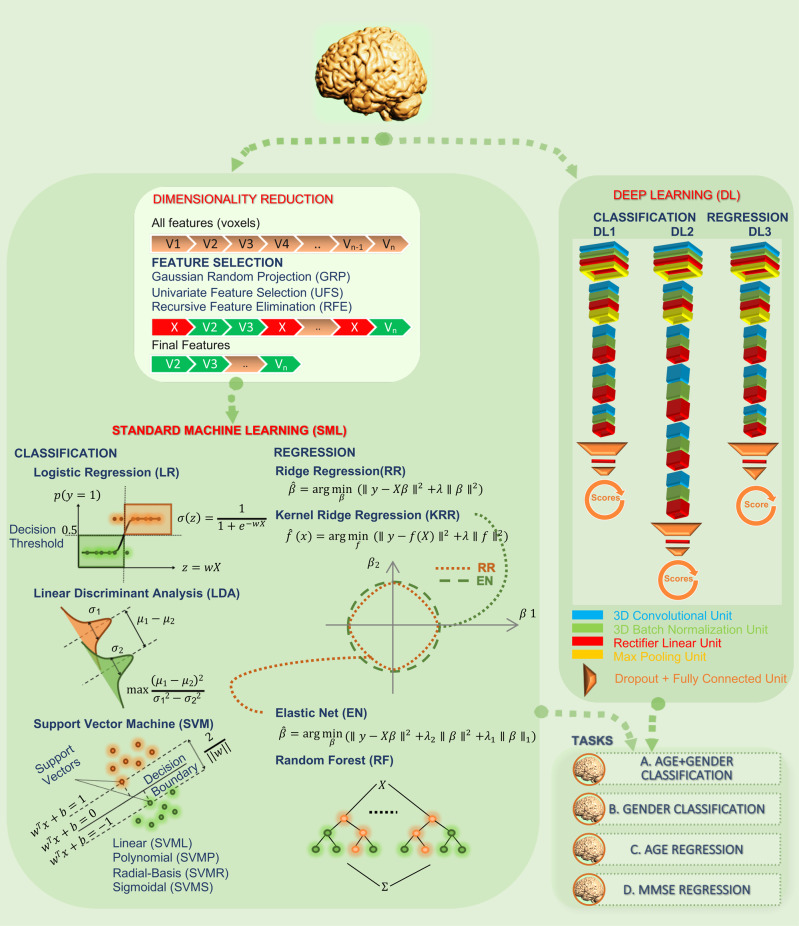
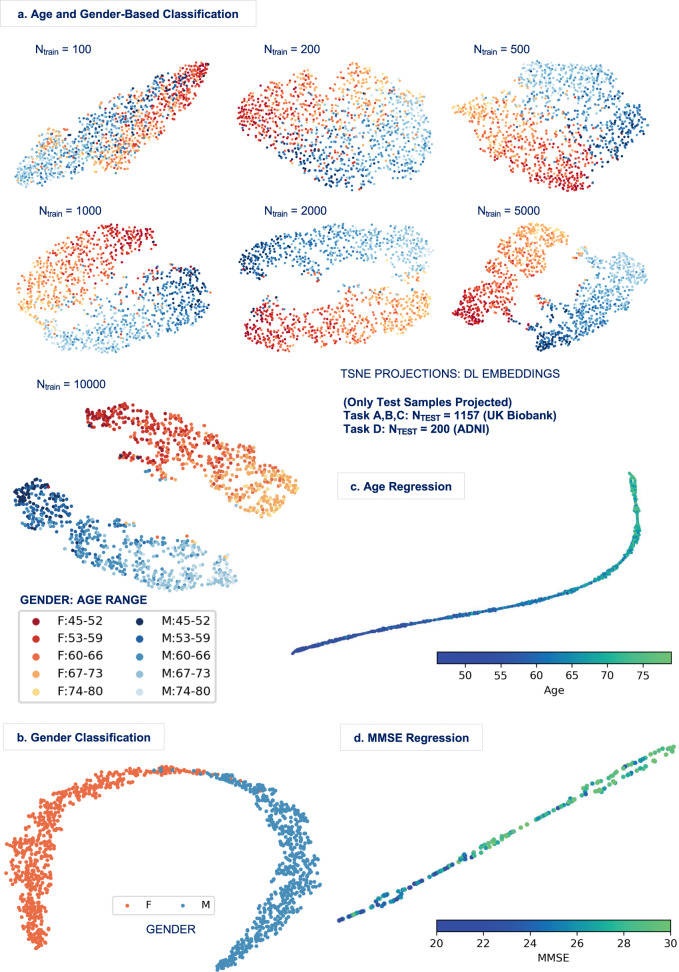
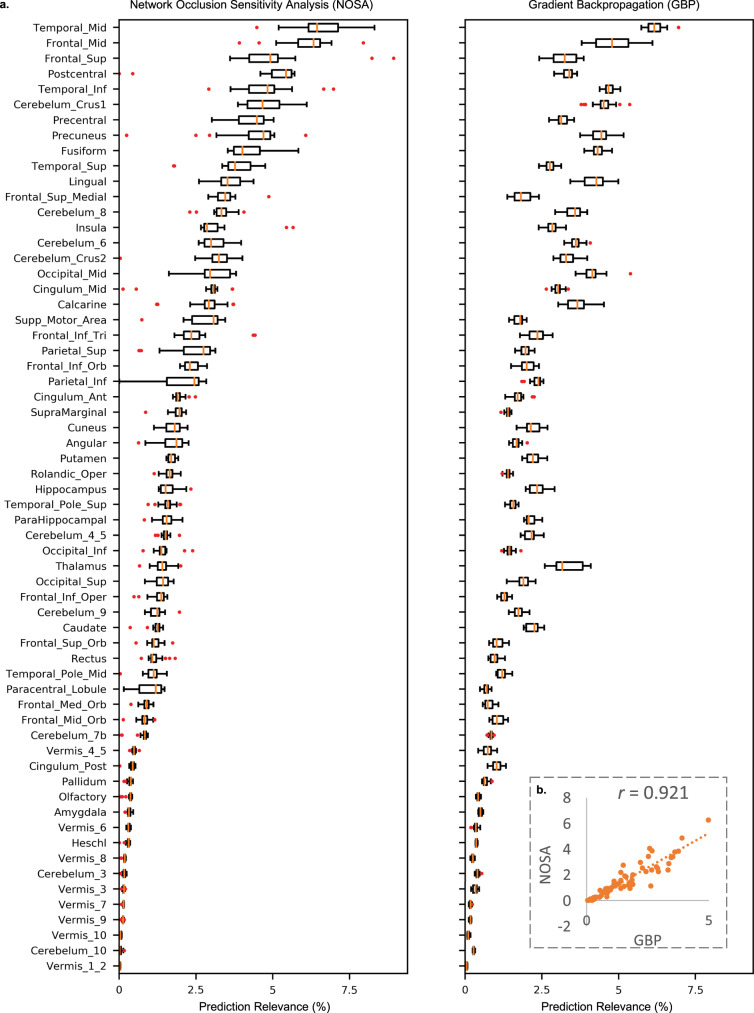
Recent critical commentaries unfavorably compare deep learning (DL) with standard machine learning (SML) approaches for brain imaging data analysis. However, their conclusions are often based on pre-engineered features depriving DL of its main advantage - representation learning. We conduct a large-scale systematic comparison profiled in multiple classification and regression tasks on structural MRI images and show the importance of representation learning for DL. Results show that if trained following prevalent DL practices, DL methods have the potential to scale particularly well and substantially improve compared to SML methods, while also presenting a lower asymptotic complexity in relative computational time, despite being more complex. We also demonstrate that DL embeddings span comprehensible task-specific projection spectra and that DL consistently localizes task-discriminative brain biomarkers. Our findings highlight the presence of nonlinearities in neuroimaging data that DL can exploit to generate superior task-discriminative representations for characterizing the human brain.
Conflict of interest statement
The authors declare no competing interests.
Figures




References
-
- Blum AL, Langley P. Selection of relevant features and examples in machine learning. Artif. Intell. 1997;97:245–271. doi: 10.1016/S0004-3702(97)00063-5. - DOI
-
- Schölkopf, B. in Proceedings of the 13th International Conference on Neural Information Processing Systems 283–289 (MIT Press, Denver, CO, 2000).
-
- Goodfellow, I., Bengio, Y. & Courville, A. Deep Learning. (The MIT Press, 2016).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
