

A Manufacturing-Oriented Intelligent Vision System Based on Deep Neural Network for Object Recognition and 6D Pose Estimation
- PMID: 33488378
- PMCID: PMC7817625
- DOI: 10.3389/fnbot.2020.616775
A Manufacturing-Oriented Intelligent Vision System Based on Deep Neural Network for Object Recognition and 6D Pose Estimation
Abstract
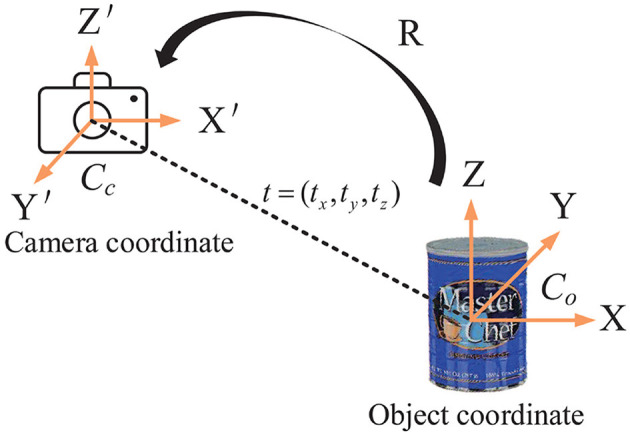
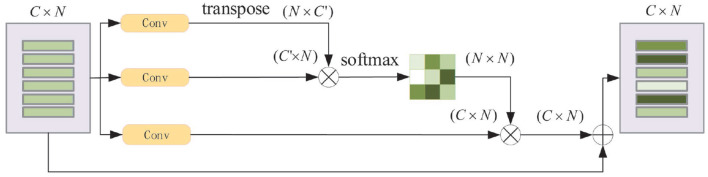
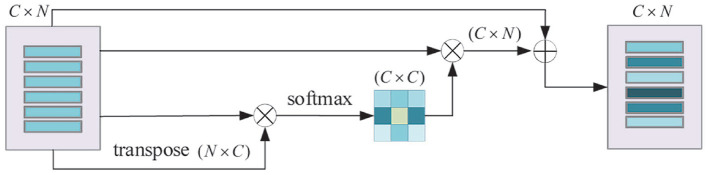
Nowadays, intelligent robots are widely applied in the manufacturing industry, in various working places or assembly lines. In most manufacturing tasks, determining the category and pose of parts is important, yet challenging, due to complex environments. This paper presents a new two-stage intelligent vision system based on a deep neural network with RGB-D image inputs for object recognition and 6D pose estimation. A dense-connected network fusing multi-scale features is first built to segment the objects from the background. The 2D pixels and 3D points in cropped object regions are then fed into a pose estimation network to make object pose predictions based on fusion of color and geometry features. By introducing the channel and position attention modules, the pose estimation network presents an effective feature extraction method, by stressing important features whilst suppressing unnecessary ones. Comparative experiments with several state-of-the-art networks conducted on two well-known benchmark datasets, YCB-Video and LineMOD, verified the effectiveness and superior performance of the proposed method. Moreover, we built a vision-guided robotic grasping system based on the proposed method using a Kinova Jaco2 manipulator with an RGB-D camera installed. Grasping experiments proved that the robot system can effectively implement common operations such as picking up and moving objects, thereby demonstrating its potential to be applied in all kinds of real-time manufacturing applications.
Keywords: 6D pose estimation; deep neural network; intelligent manufacturing; object recognition; semantic segmentation.
Copyright © 2021 Liang, Chen, Liang, Feng, Wang and Wu.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures











References
-
- Brachmann E., Krull A., Michel F., Gumhold S., Shotton J., Rother C. (2014). Learning 6D object pose estimation using 3D object coordinates, in European Conference on Computer Vision (ECCV) (Cham: Springer; ), 536–551. 10.1007/978-3-319-10605-2_35 - DOI
-
- Chen L. C., Papandreou G., Schroff F., Adam H. (2017b). Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587.
-
- Drozdzal M., Vorontsov E., Chartrand G., Kadoury S., Pal C. (2016). The importance of skip connections in biomedical image segmentation, in Deep Learning and Data Labeling for Medical Applications (Cham: Springer; ), 179–187. 10.1007/978-3-319-46976-8_19 - DOI
LinkOut - more resources
Full Text Sources
Other Literature Sources