

Genomic mechanisms of climate adaptation in polyploid bioenergy switchgrass
- PMID: 33505029
- PMCID: PMC7886653
- DOI: 10.1038/s41586-020-03127-1
Genomic mechanisms of climate adaptation in polyploid bioenergy switchgrass
Abstract
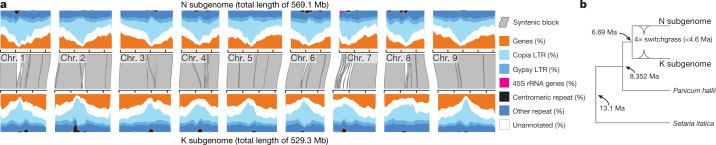
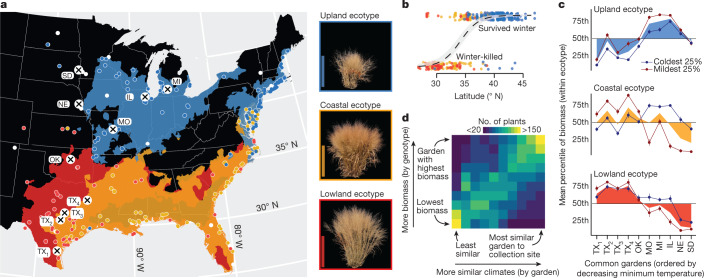
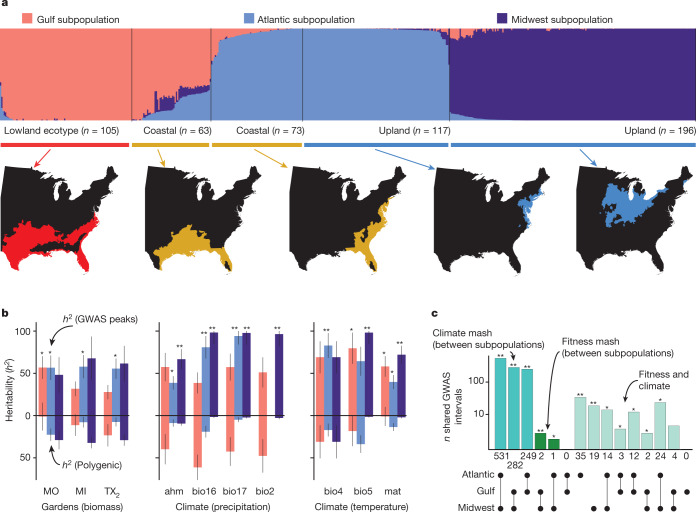
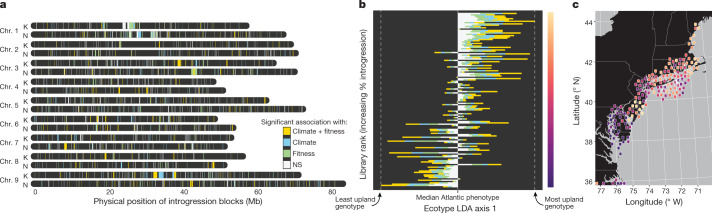
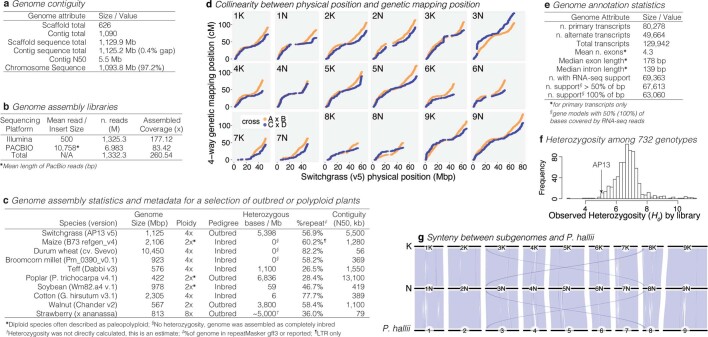
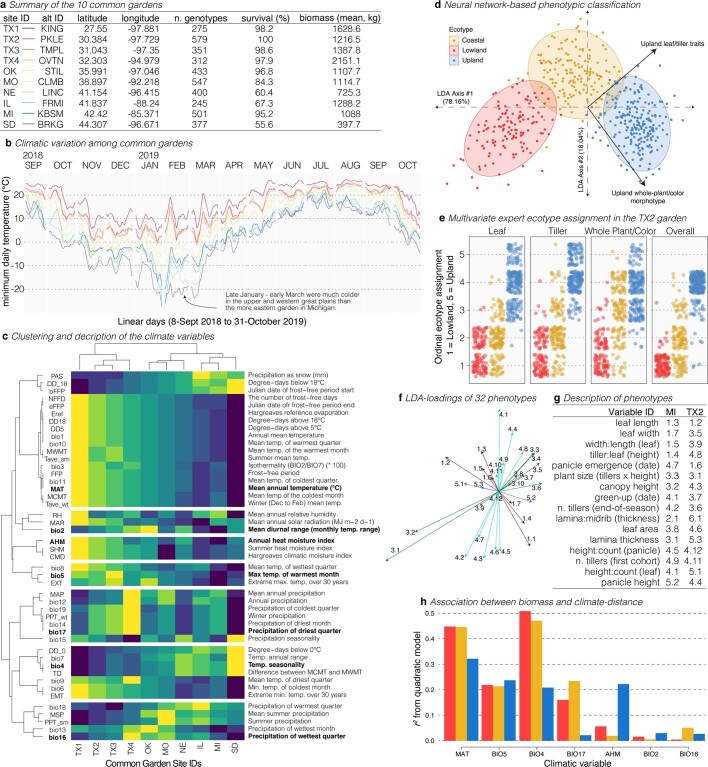
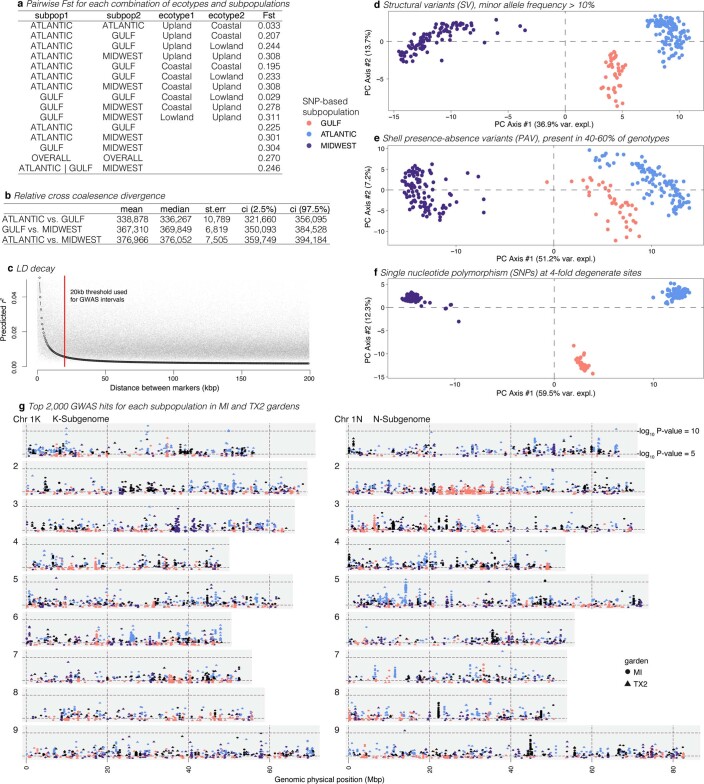
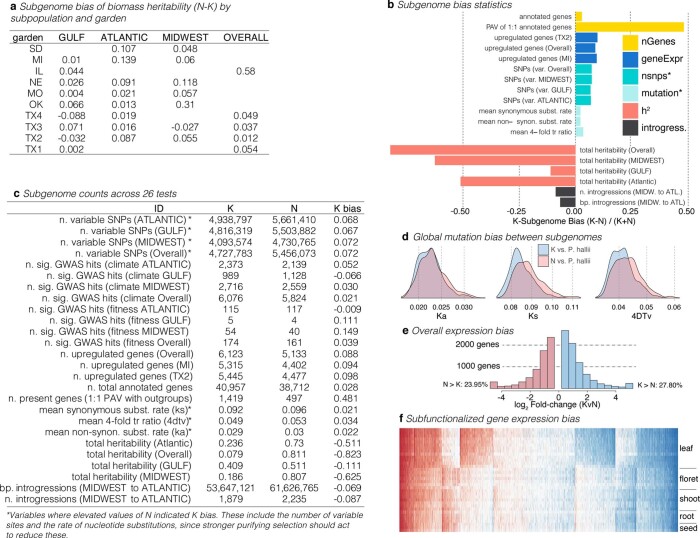
Long-term climate change and periodic environmental extremes threaten food and fuel security1 and global crop productivity2-4. Although molecular and adaptive breeding strategies can buffer the effects of climatic stress and improve crop resilience5, these approaches require sufficient knowledge of the genes that underlie productivity and adaptation6-knowledge that has been limited to a small number of well-studied model systems. Here we present the assembly and annotation of the large and complex genome of the polyploid bioenergy crop switchgrass (Panicum virgatum). Analysis of biomass and survival among 732 resequenced genotypes, which were grown across 10 common gardens that span 1,800 km of latitude, jointly revealed extensive genomic evidence of climate adaptation. Climate-gene-biomass associations were abundant but varied considerably among deeply diverged gene pools. Furthermore, we found that gene flow accelerated climate adaptation during the postglacial colonization of northern habitats through introgression of alleles from a pre-adapted northern gene pool. The polyploid nature of switchgrass also enhanced adaptive potential through the fractionation of gene function, as there was an increased level of heritable genetic diversity on the nondominant subgenome. In addition to investigating patterns of climate adaptation, the genome resources and gene-trait associations developed here provide breeders with the necessary tools to increase switchgrass yield for the sustainable production of bioenergy.
Conflict of interest statement
The authors declare no competing interests.
Figures
Comment in
-
Multiple genomes give switchgrass an advantage.Nature. 2021 Feb;590(7846):394-395. doi: 10.1038/d41586-021-00212-x. Nature. 2021. PMID: 33526900 No abstract available.
References
-
- Challinor AJ, et al. A meta-analysis of crop yield under climate change and adaptation. Nat. Clim. Chang. 2014;4:287–291. doi: 10.1038/nclimate2153. - DOI
-
- Porter, J. R. et al. in Climate Change 2014: Impacts, Adaptation, and Vulnerability. Part A: Global and Sectoral Aspects (Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change) (eds Field, C. B. et al.) 485–533 (Cambridge Univ. Press, 2014).
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
