

Highly elevated polygenic risk scores are better predictors of myocardial infarction risk early in life than later
- PMID: 33509272
- PMCID: PMC7845089
- DOI: 10.1186/s13073-021-00828-8
Highly elevated polygenic risk scores are better predictors of myocardial infarction risk early in life than later
Abstract
Background: Several polygenic risk scores (PRS) have been developed for cardiovascular risk prediction, but the additive value of including PRS together with conventional risk factors for risk prediction is questionable. This study assesses the clinical utility of including four PRS generated from 194, 46K, 1.5M, and 6M SNPs, along with conventional risk factors, to predict risk of ischemic heart disease (IHD), myocardial infarction (MI), and first MI event on or before age 50 (early MI).
Methods: A cross-validated logistic regression (LR) algorithm was trained either on ~ 440K European ancestry individuals from the UK Biobank (UKB), or the full UKB population, including as features different combinations of conventional established-at-birth risk factors (ancestry, sex) and risk factors that are non-fixed over an individual's lifespan (age, BMI, hypertension, hyperlipidemia, diabetes, smoking, family history), with and without also including PRS. The algorithm was trained separately with IHD, MI, and early MI as prediction labels.
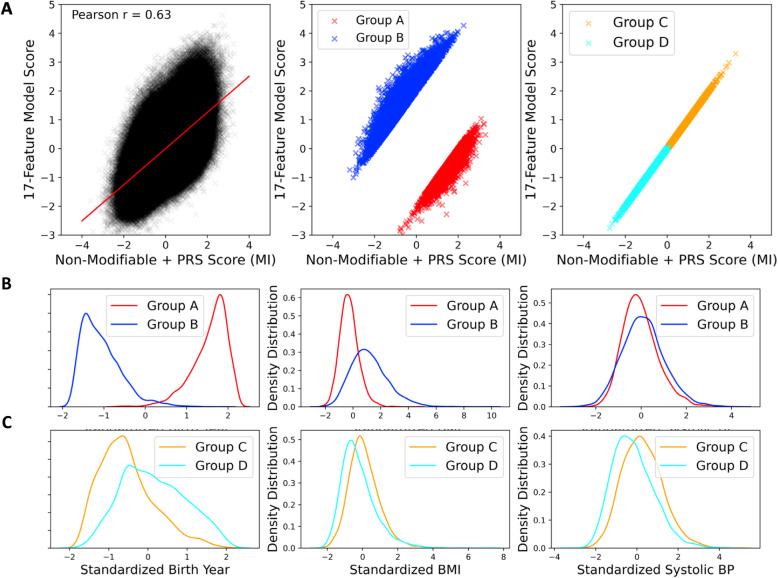
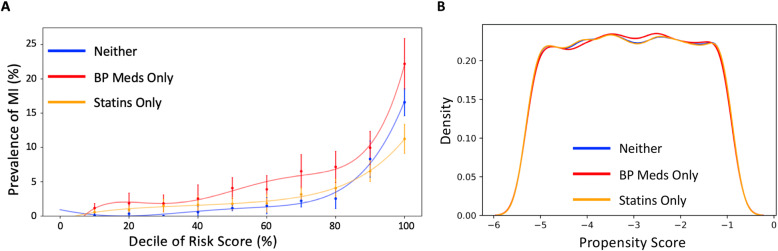
Results: When LR was trained using risk factors established-at-birth, adding the four PRS significantly improved the area under the curve (AUC) for IHD (0.62 to 0.67) and MI (0.67 to 0.73), as well as for early MI (0.70 to 0.79). When LR was trained using all risk factors, adding the four PRS only resulted in a significantly higher disease prevalence in the 98th and 99th percentiles of both the IHD and MI scores.
Conclusions: PRS improve cardiovascular risk stratification early in life when knowledge of later-life risk factors is unavailable. However, by middle age, when many risk factors are known, the improvement attributed to PRS is marginal for the general population.
Keywords: Coronary artery disease; Ischemic heart disease; Myocardial infarction; Polygenic risk scores; Risk assessment.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures
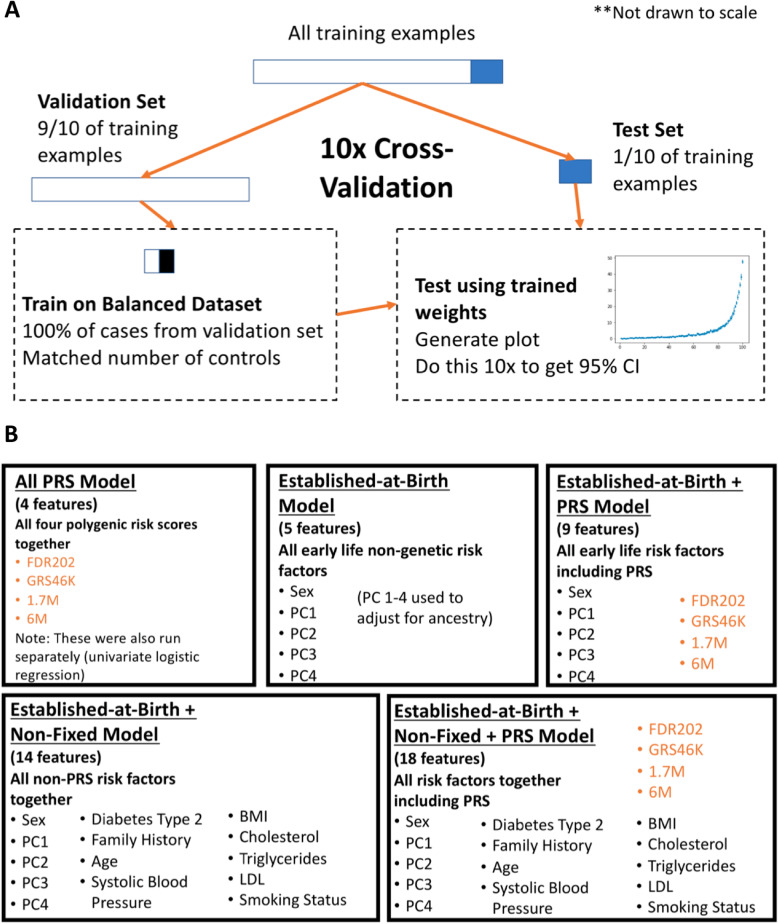
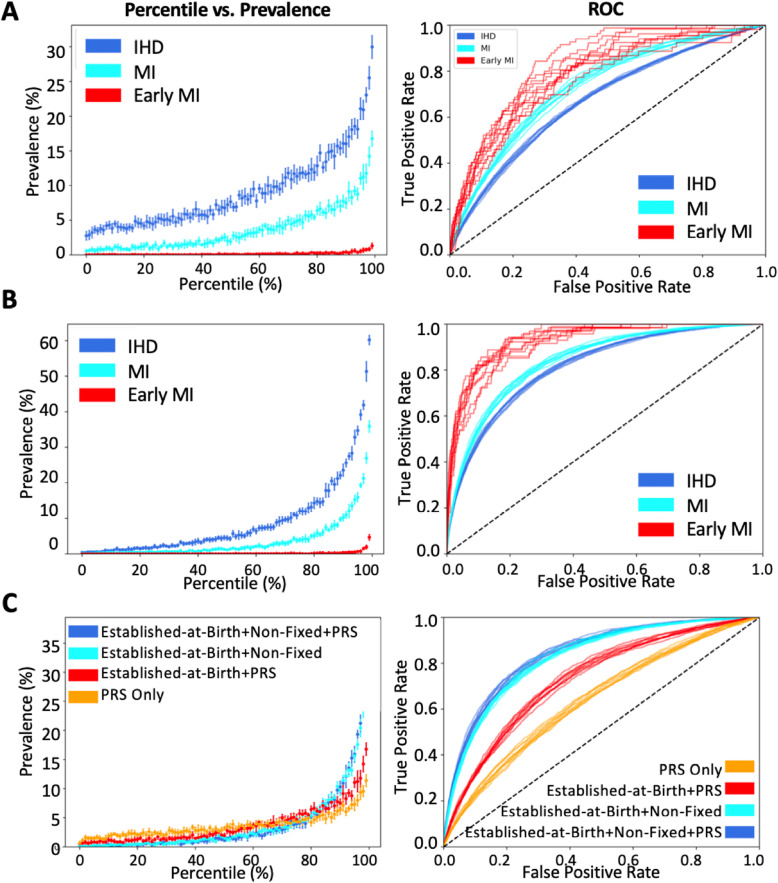
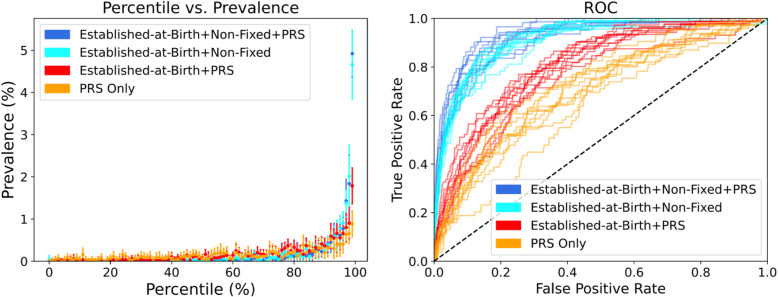
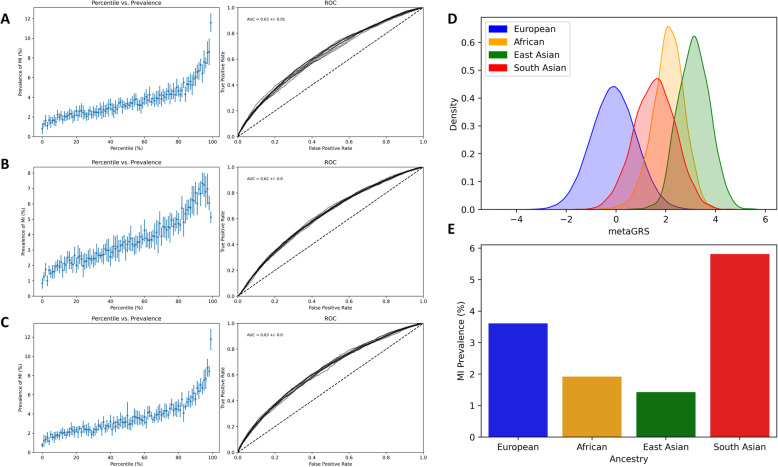
References
-
- Naldi L, Matzopoulos R, Birbeck G, Pahari B, Adair T, Lipshultz SE, et al. Global and regional mortality from 235 causes of death for 20 age groups in 1990 and 2010: a systematic analysis for the Global Burden of Disease Study 2010. Lancet. 2012;380:2095–2128. doi: 10.1016/S0140-6736(12)61728-0. - DOI - PMC - PubMed
-
- Vos T, Allen C, Arora M, Barber RM, Brown A, Carter A, et al. Global, regional, and national incidence, prevalence, and years lived with disability for 310 diseases and injuries, 1990–2015: a systematic analysis for the Global Burden of Disease Study 2015. Lancet. 2016;388:1545–1602. doi: 10.1016/S0140-6736(16)31678-6. - DOI - PMC - PubMed
-
- Centers for Disease Control and Prevention (CDC) Prevalence of coronary heart disease--United States, 2006–2010. MMWR Morb Mortal Wkly Rep. 2011;60:1377–1381. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
