

Polygenic risk modeling with latent trait-related genetic components
- PMID: 33558700
- PMCID: PMC8298449
- DOI: 10.1038/s41431-021-00813-0
Polygenic risk modeling with latent trait-related genetic components
Abstract
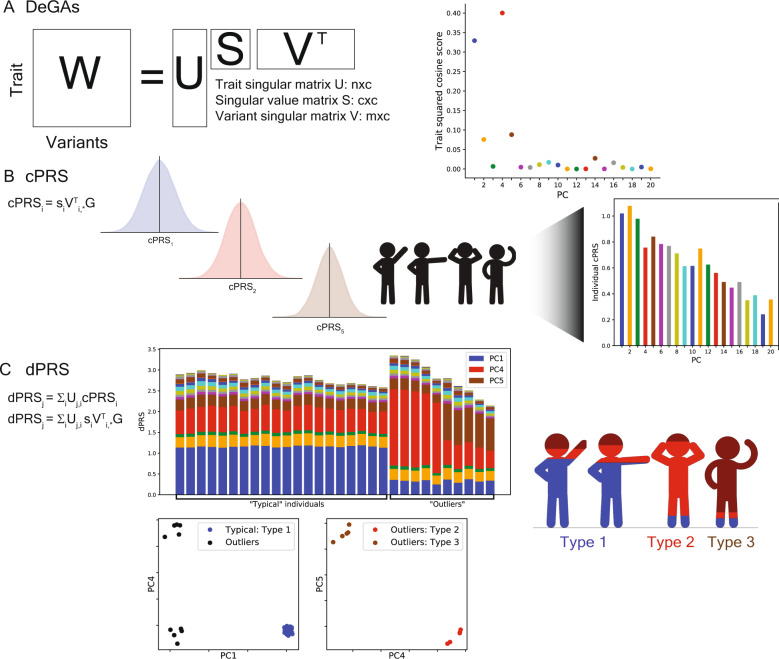
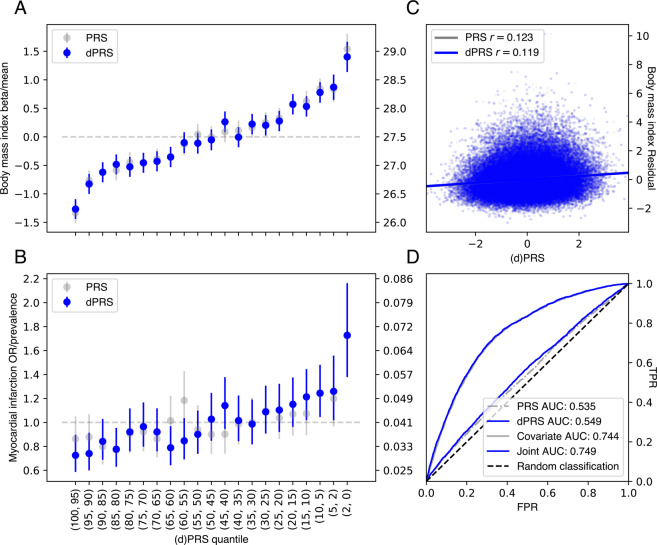
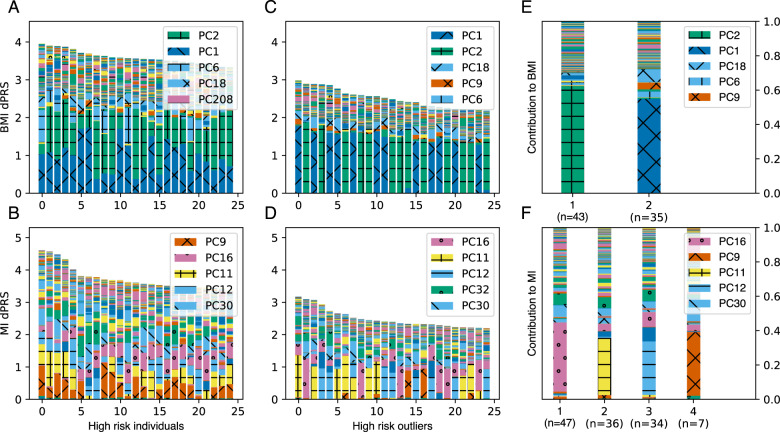
Polygenic risk models have led to significant advances in understanding complex diseases and their clinical presentation. While polygenic risk scores (PRS) can effectively predict outcomes, they do not generally account for disease subtypes or pathways which underlie within-trait diversity. Here, we introduce a latent factor model of genetic risk based on components from Decomposition of Genetic Associations (DeGAs), which we call the DeGAs polygenic risk score (dPRS). We compute DeGAs using genetic associations for 977 traits and find that dPRS performs comparably to standard PRS while offering greater interpretability. We show how to decompose an individual's genetic risk for a trait across DeGAs components, with examples for body mass index (BMI) and myocardial infarction (heart attack) in 337,151 white British individuals in the UK Biobank, with replication in a further set of 25,486 non-British white individuals. We find that BMI polygenic risk factorizes into components related to fat-free mass, fat mass, and overall health indicators like physical activity. Most individuals with high dPRS for BMI have strong contributions from both a fat-mass component and a fat-free mass component, whereas a few "outlier" individuals have strong contributions from only one of the two components. Overall, our method enables fine-scale interpretation of the drivers of genetic risk for complex traits.
© 2021. The Author(s), under exclusive licence to European Society of Human Genetics.
Conflict of interest statement
Some of the material in this work has been filed as a patent under Nonprovisional Application S19-332 (S31-06348).
Figures

References
-
- GBD 2017 Disease and Injury Incidence and Prevalence Collaborators Global, regional, and national incidence, prevalence, and years lived with disability for 354 diseases and injuries for 195 countries and territories, 1990-2017: a systematic analysis for the Global Burden of Disease Study 2017. Lancet. 2018;392:1789–858. doi: 10.1016/S0140-6736(18)32279-7. - DOI - PMC - PubMed
-
- Khera AV, Chaffin M, Zekavat SM, Collins RL, Roselli C, Natarajan P, et al. Whole-genome sequencing to characterize monogenic and polygenic contributions in patients hospitalized with early-onset myocardial infarction. Circulation. 2019;139:1593–602. doi: 10.1161/CIRCULATIONAHA.118.035658. - DOI - PMC - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
