

dearseq: a variance component score test for RNA-seq differential analysis that effectively controls the false discovery rate
- PMID: 33575637
- PMCID: PMC7676475
- DOI: 10.1093/nargab/lqaa093
dearseq: a variance component score test for RNA-seq differential analysis that effectively controls the false discovery rate
Abstract
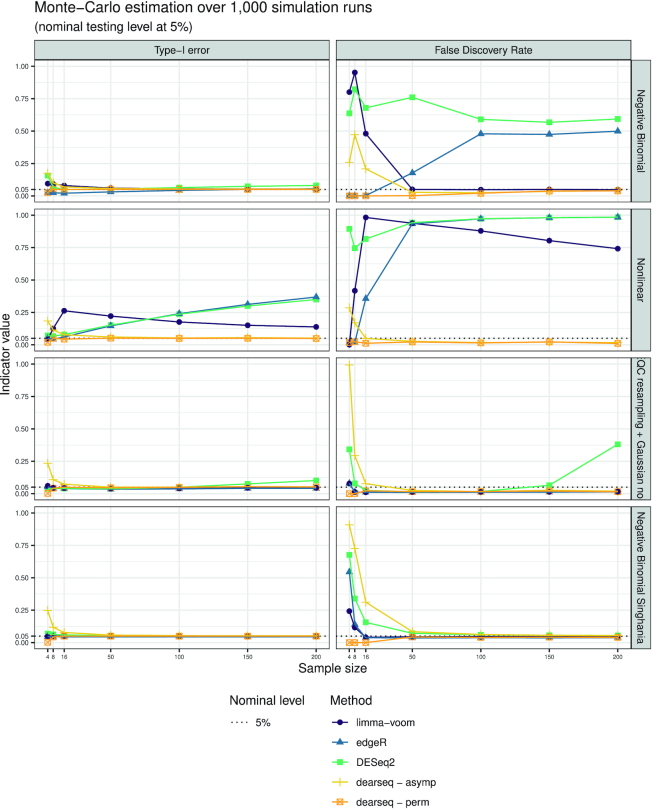
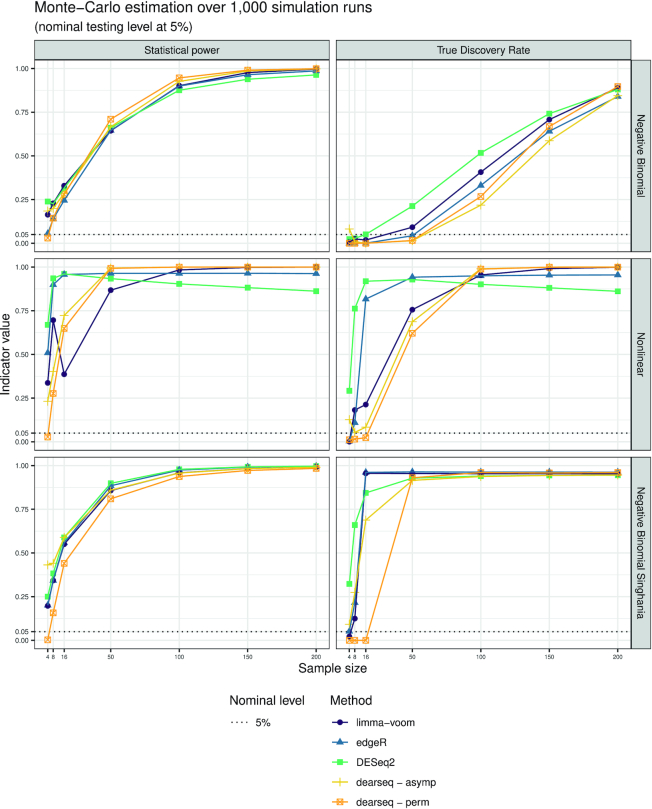
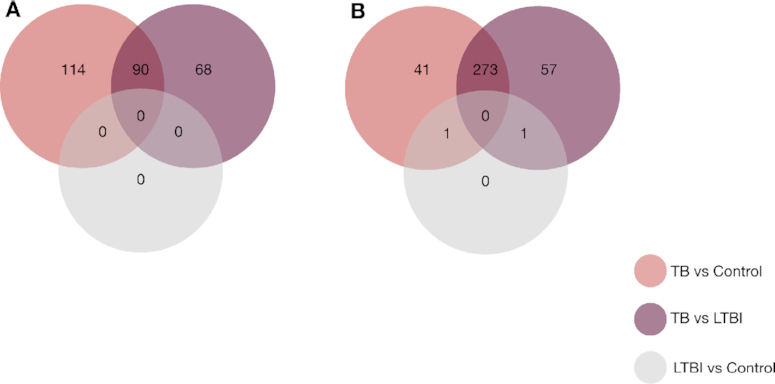
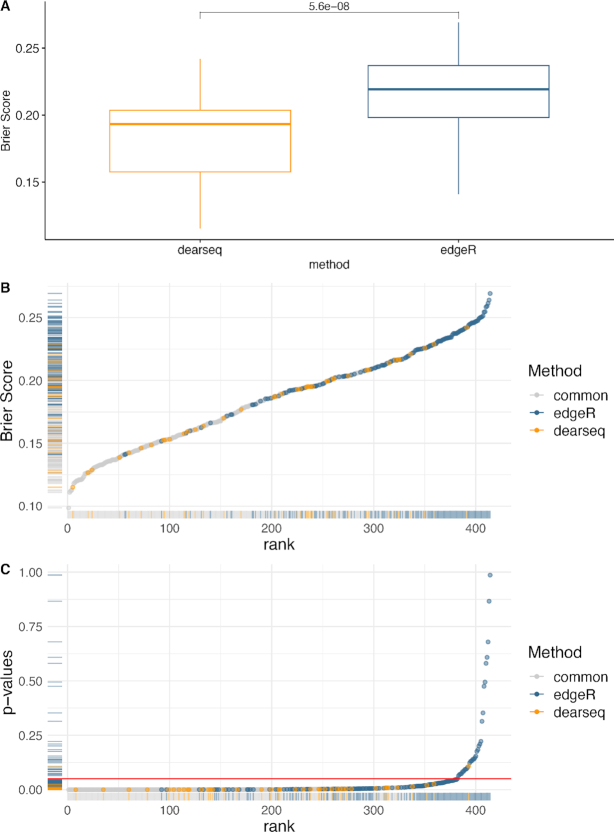
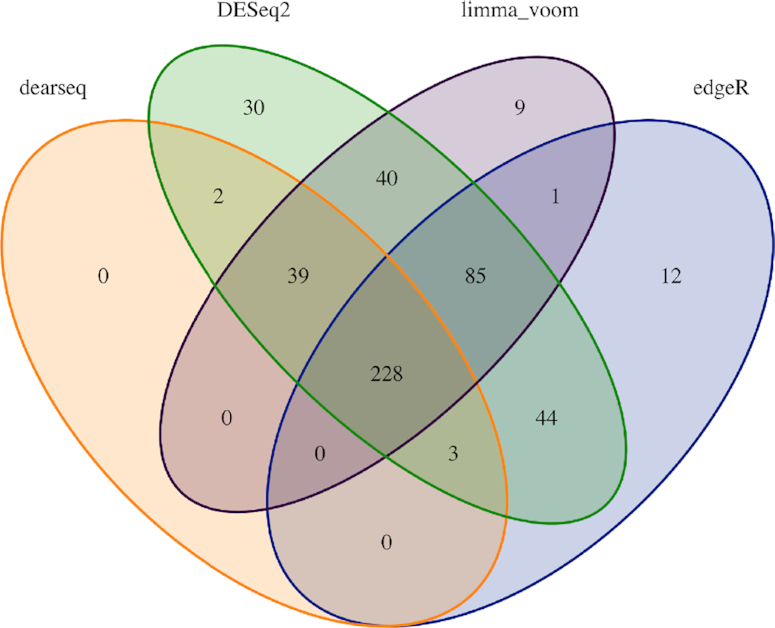
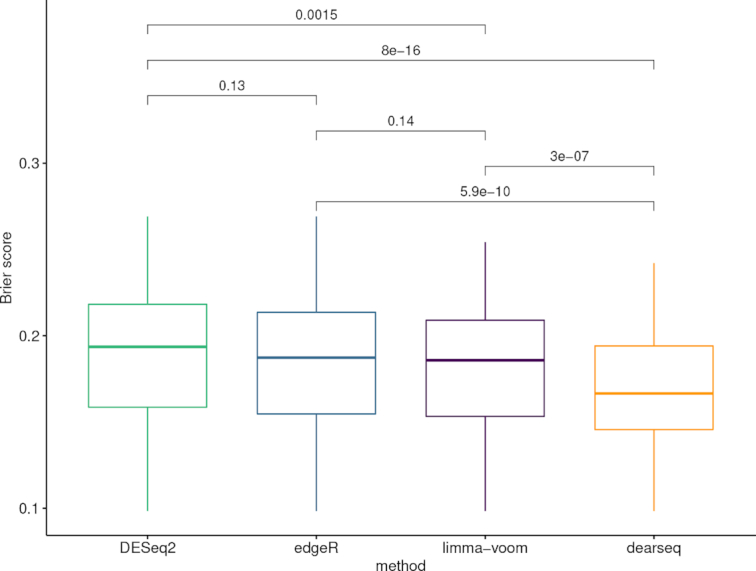
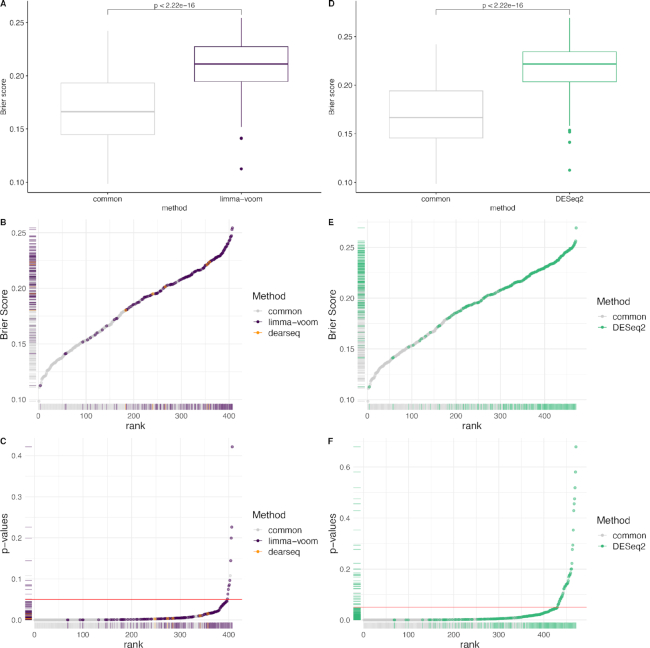
RNA-seq studies are growing in size and popularity. We provide evidence that the most commonly used methods for differential expression analysis (DEA) may yield too many false positive results in some situations. We present dearseq, a new method for DEA that controls the false discovery rate (FDR) without making any assumption about the true distribution of RNA-seq data. We show that dearseq controls the FDR while maintaining strong statistical power compared to the most popular methods. We demonstrate this behavior with mathematical proofs, simulations and a real data set from a study of tuberculosis, where our method produces fewer apparent false positives.
© The Author(s) 2019. Published by Oxford University Press on behalf of NAR Genomics and Bioinformatics.
Figures
References
-
- Benjamini Y., Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B Methodol. 1995; 57:289–300.
LinkOut - more resources
Full Text Sources
Other Literature Sources
