

Machine learning identifies candidates for drug repurposing in Alzheimer's disease
- PMID: 33589615
- PMCID: PMC7884393
- DOI: 10.1038/s41467-021-21330-0
Machine learning identifies candidates for drug repurposing in Alzheimer's disease
Abstract
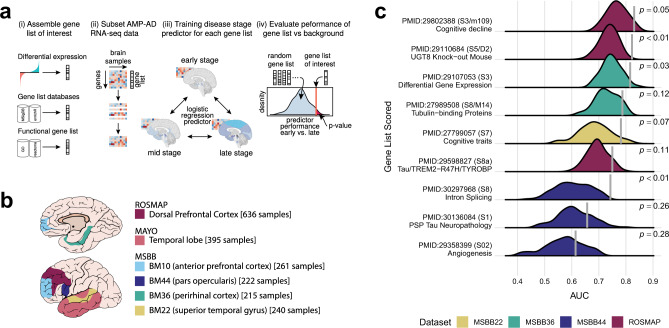
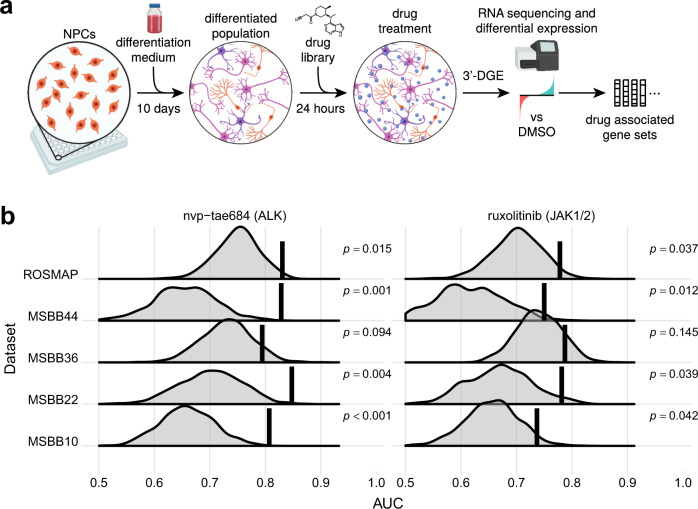
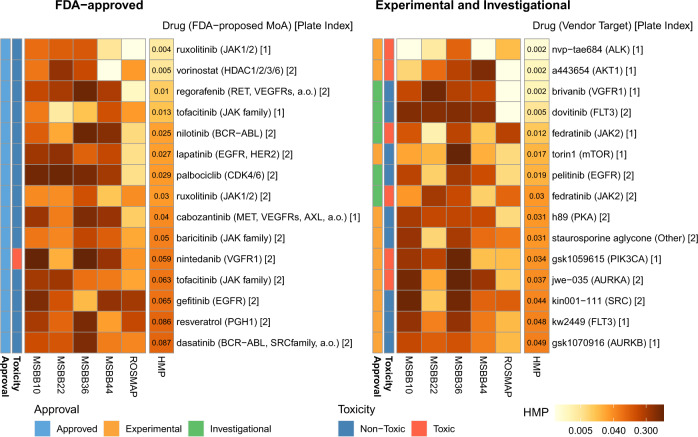
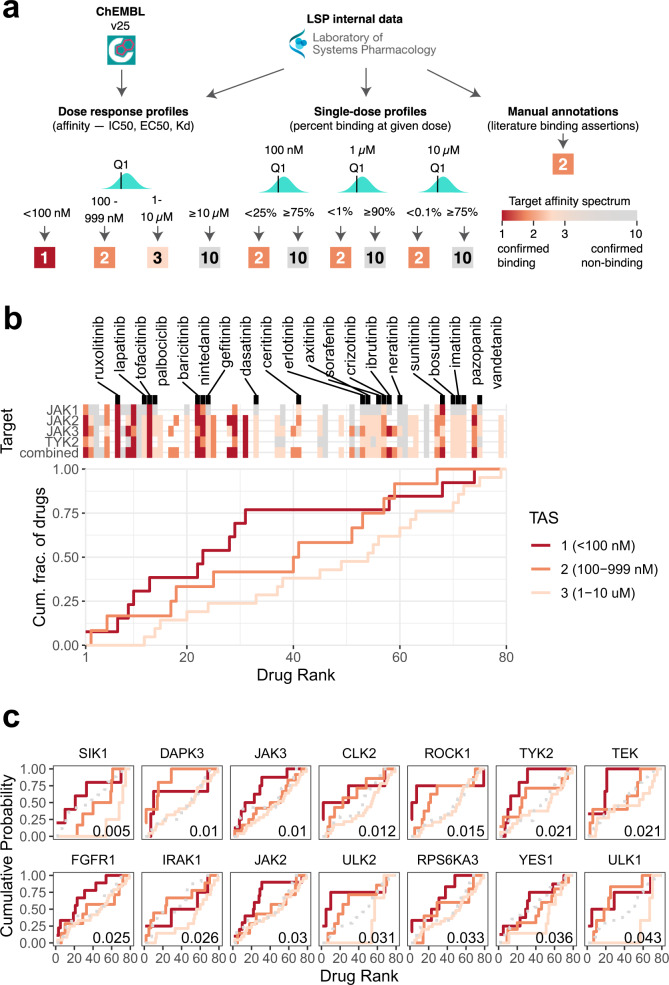
Clinical trials of novel therapeutics for Alzheimer's Disease (AD) have consumed a large amount of time and resources with largely negative results. Repurposing drugs already approved by the Food and Drug Administration (FDA) for another indication is a more rapid and less expensive option. We present DRIAD (Drug Repurposing In AD), a machine learning framework that quantifies potential associations between the pathology of AD severity (the Braak stage) and molecular mechanisms as encoded in lists of gene names. DRIAD is applied to lists of genes arising from perturbations in differentiated human neural cell cultures by 80 FDA-approved and clinically tested drugs, producing a ranked list of possible repurposing candidates. Top-scoring drugs are inspected for common trends among their targets. We propose that the DRIAD method can be used to nominate drugs that, after additional validation and identification of relevant pharmacodynamic biomarker(s), could be readily evaluated in a clinical trial.
Conflict of interest statement
The authors declare the following competing interests. P.K.S. is a member of the SAB or Board of Directors of Applied Biomath, RareCyte, NanoString and Glencoe Software and has equity in some of these companies. In the last 5 years, the Sorger lab has received research funding from Novartis and Merck. P.K.S. declares that none of these relationships are directly or indirectly related to the content of this manuscript. B.T.H. has stock in Novartis and Dewpoint. N.T.J. is an employee of H3 Biomedicine, a subsidiary of Eisai Inc. that develops therapies for Alzheimer’s. S.R., P.K.S., M.W.A., and A.S. are inventors on a patent application (WO/2017/173451) for novel targets in neurodegenerative diseases. All other authors (C.H., P.T., N.M., S.B., K.E., G.Z.) declare no competing interests.
Figures
Similar articles
-
Medical genetics-based drug repurposing for Alzheimer's disease.Brain Res Bull. 2015 Jan;110:26-9. doi: 10.1016/j.brainresbull.2014.11.003. Epub 2014 Nov 22. Brain Res Bull. 2015. PMID: 25446738 Review.
-
Xanomeline derivative EUK1001 attenuates Alzheimer's disease pathology in a triple transgenic mouse model.Mol Med Rep. 2017 Nov;16(5):7835-7840. doi: 10.3892/mmr.2017.7502. Epub 2017 Sep 18. Mol Med Rep. 2017. PMID: 28944835
-
Citalopram restores short-term memory deficit and non-cognitive behaviors in APP/PS1 mice while halting the advance of Alzheimer's disease-like pathology.Neuropharmacology. 2018 Mar 15;131:475-486. doi: 10.1016/j.neuropharm.2017.12.021. Epub 2017 Dec 11. Neuropharmacology. 2018. PMID: 29241655
-
AlphaScreen Identifies MSUT2 Inhibitors for Tauopathy-Targeting Therapeutic Discovery.SLAS Discov. 2021 Mar;26(3):400-409. doi: 10.1177/2472555220958387. Epub 2020 Sep 28. SLAS Discov. 2021. PMID: 32981422 Free PMC article.
-
Liver X receptors in lipid metabolism: opportunities for drug discovery.Nat Rev Drug Discov. 2014 Jun;13(6):433-44. doi: 10.1038/nrd4280. Epub 2014 May 16. Nat Rev Drug Discov. 2014. PMID: 24833295 Review.
Cited by
-
Applications of artificial intelligence in dementia research.Camb Prism Precis Med. 2022 Dec 6;1:e9. doi: 10.1017/pcm.2022.10. eCollection 2023. Camb Prism Precis Med. 2022. PMID: 38550934 Free PMC article. Review.
-
Recent trends in artificial intelligence-driven identification and development of anti-neurodegenerative therapeutic agents.Mol Divers. 2021 Aug;25(3):1517-1539. doi: 10.1007/s11030-021-10274-8. Epub 2021 Jul 19. Mol Divers. 2021. PMID: 34282519
-
Tackling neurodegeneration in vitro with omics: a path towards new targets and drugs.Front Mol Neurosci. 2024 Jun 17;17:1414886. doi: 10.3389/fnmol.2024.1414886. eCollection 2024. Front Mol Neurosci. 2024. PMID: 38952421 Free PMC article. Review.
-
CREB3L2-ATF4 heterodimerization defines a transcriptional hub of Alzheimer's disease gene expression linked to neuropathology.Sci Adv. 2023 Mar 3;9(9):eadd2671. doi: 10.1126/sciadv.add2671. Epub 2023 Mar 3. Sci Adv. 2023. PMID: 36867706 Free PMC article.
-
DDIT: An Online Predictor for Multiple Clinical Phenotypic Drug-Disease Associations.Front Pharmacol. 2022 Jan 19;12:772026. doi: 10.3389/fphar.2021.772026. eCollection 2021. Front Pharmacol. 2022. PMID: 35126114 Free PMC article.
References
-
- Alzheimer’s Association. 2019 Alzheimer’s disease facts and figures. Alzheimers Dement. 15, 321–387 (2019).
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Molecular Biology Databases
