

Structured sequences emerge from random pool when replicated by templated ligation
- PMID: 33593911
- PMCID: PMC7923349
- DOI: 10.1073/pnas.2018830118
Structured sequences emerge from random pool when replicated by templated ligation
Abstract
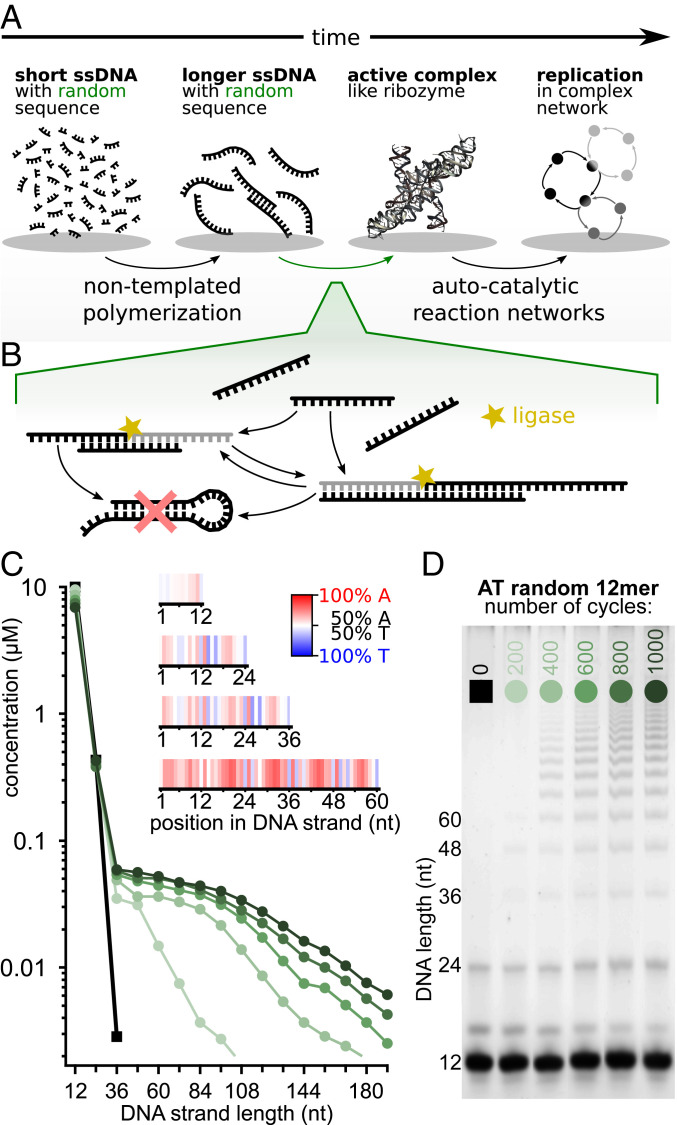
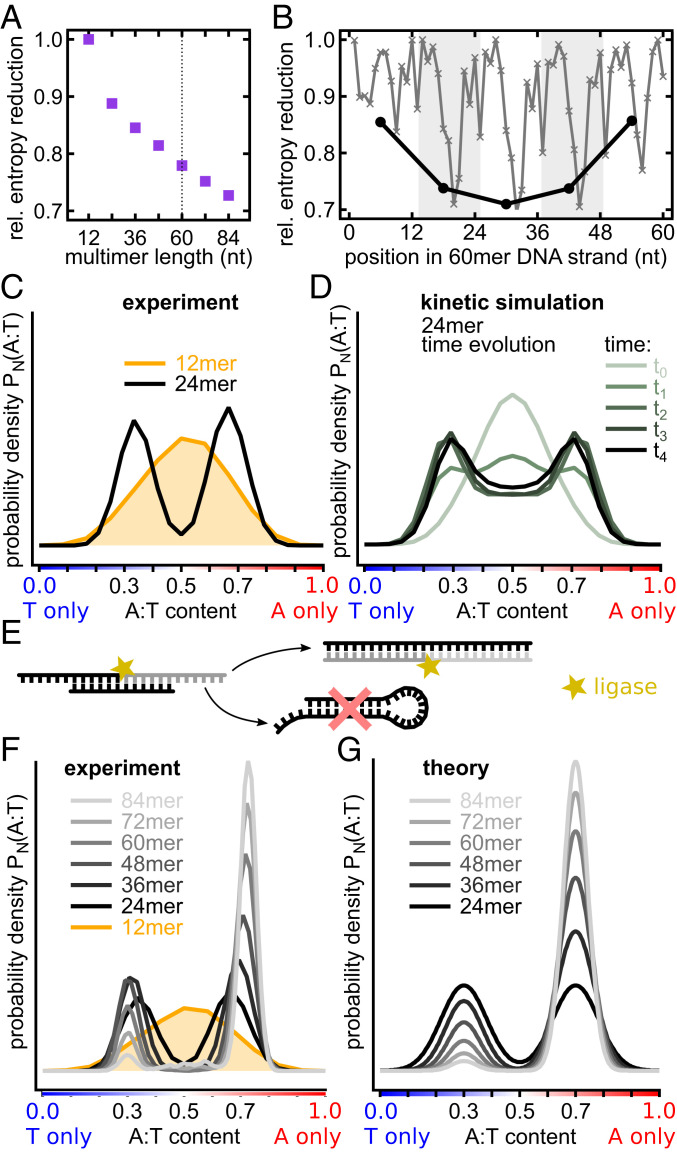
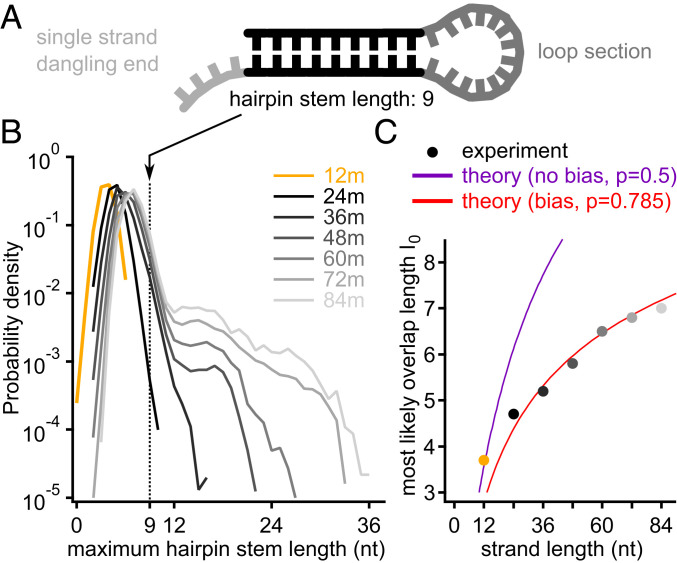
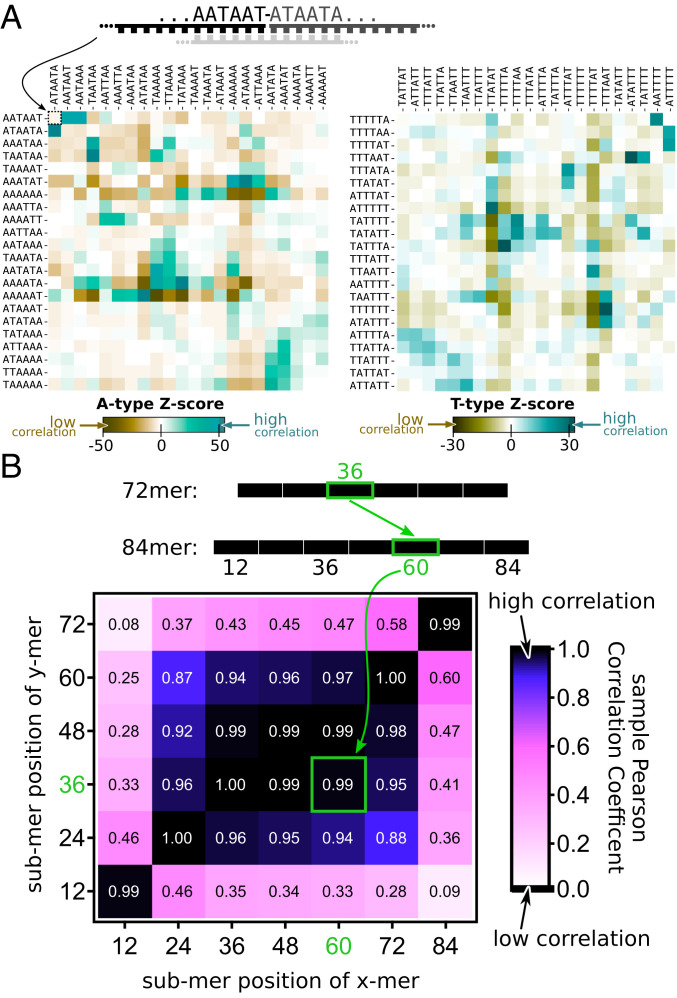
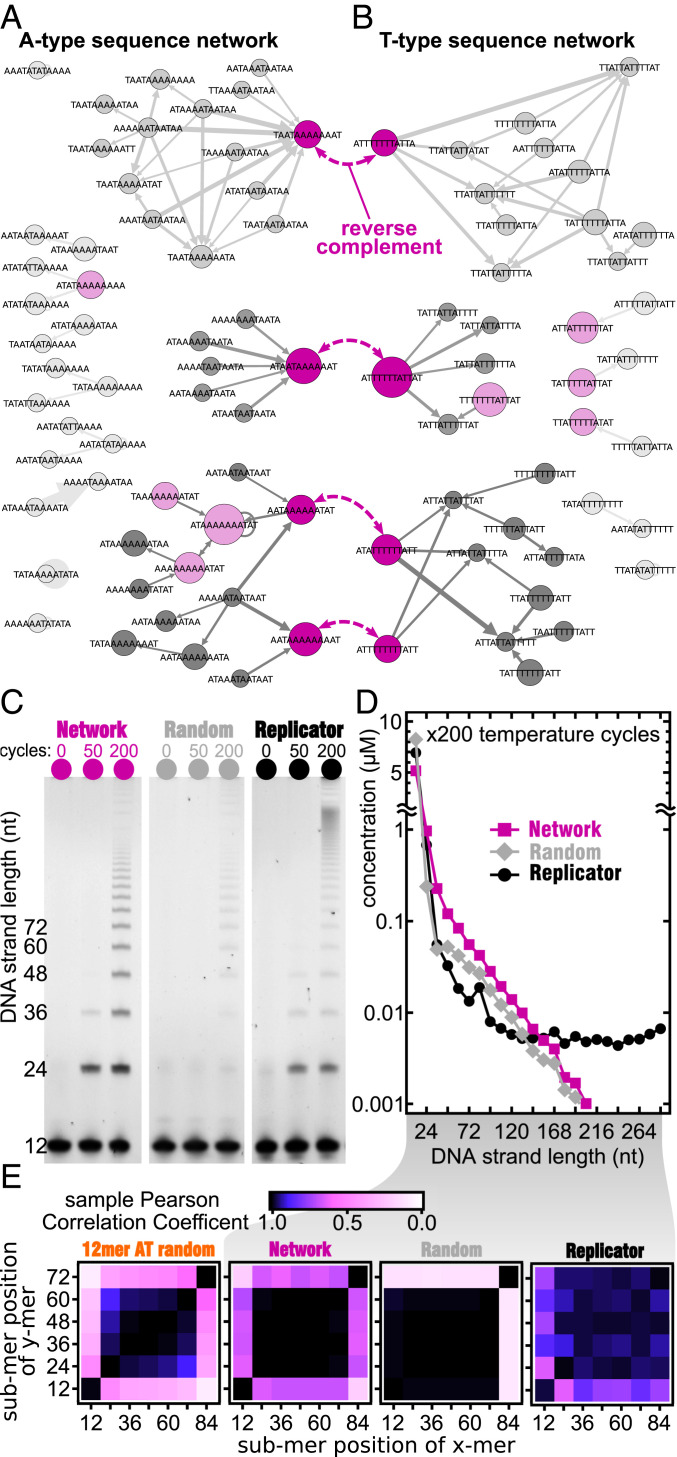
The central question in the origin of life is to understand how structure can emerge from randomness. The Eigen theory of replication states, for sequences that are copied one base at a time, that the replication fidelity has to surpass an error threshold to avoid that replicated specific sequences become random because of the incorporated replication errors [M. Eigen, Naturwissenschaften 58 (10), 465-523 (1971)]. Here, we showed that linking short oligomers from a random sequence pool in a templated ligation reaction reduced the sequence space of product strands. We started from 12-mer oligonucleotides with two bases in all possible combinations and triggered enzymatic ligation under temperature cycles. Surprisingly, we found the robust creation of long, highly structured sequences with low entropy. At the ligation site, complementary and alternating sequence patterns developed. However, between the ligation sites, we found either an A-rich or a T-rich sequence within a single oligonucleotide. Our modeling suggests that avoidance of hairpins was the likely cause for these two complementary sequence pools. What emerged was a network of complementary sequences that acted both as templates and substrates of the reaction. This self-selecting ligation reaction could be restarted by only a few majority sequences. The findings showed that replication by random templated ligation from a random sequence input will lead to a highly structured, long, and nonrandom sequence pool. This is a favorable starting point for a subsequent Darwinian evolution searching for higher catalytic functions in an RNA world scenario.
Keywords: DNA replication; Darwinian evolution; origin of life; sequence entropy; templated ligation.
Copyright © 2021 the Author(s). Published by PNAS.
Conflict of interest statement
The authors declare no competing interest.
Figures
Similar articles
-
Surprising fidelity of template-directed chemical ligation of oligonucleotides.Chem Biol. 1997 Aug;4(8):595-605. doi: 10.1016/s1074-5521(97)90245-3. Chem Biol. 1997. PMID: 9281525
-
The fidelity of template-directed oligonucleotide ligation and the inevitability of polymerase function.Orig Life Evol Biosph. 1999 Aug;29(4):375-90. doi: 10.1023/a:1006544611320. Orig Life Evol Biosph. 1999. PMID: 10472627
-
Thermodynamic and Kinetic Sequence Selection in Enzyme-Free Polymer Self-Assembly inside a Non-equilibrium RNA Reactor.Life (Basel). 2022 Apr 10;12(4):567. doi: 10.3390/life12040567. Life (Basel). 2022. PMID: 35455058 Free PMC article.
-
Circular oligonucleotides: new concepts in oligonucleotide design.Annu Rev Biophys Biomol Struct. 1996;25:1-28. doi: 10.1146/annurev.bb.25.060196.000245. Annu Rev Biophys Biomol Struct. 1996. PMID: 8800462 Review.
-
Molecular replication.Nature. 1992 Jul 16;358(6383):203-9. doi: 10.1038/358203a0. Nature. 1992. PMID: 1630488 Review.
Cited by
-
The protometabolic nature of prebiotic chemistry.Chem Soc Rev. 2023 Oct 30;52(21):7359-7388. doi: 10.1039/d3cs00594a. Chem Soc Rev. 2023. PMID: 37855729 Free PMC article. Review.
-
Prebiotic Foam Environments to Oligomerize and Accumulate RNA.Chembiochem. 2022 Dec 16;23(24):e202200423. doi: 10.1002/cbic.202200423. Epub 2022 Nov 18. Chembiochem. 2022. PMID: 36354762 Free PMC article.
-
Computer simulations of Template-Directed RNA Synthesis driven by temperature cycling in diverse sequence mixtures.PLoS Comput Biol. 2022 Aug 24;18(8):e1010458. doi: 10.1371/journal.pcbi.1010458. eCollection 2022 Aug. PLoS Comput Biol. 2022. PMID: 36001640 Free PMC article.
-
Self-Reproduction and Darwinian Evolution in Autocatalytic Chemical Reaction Systems.Life (Basel). 2021 Apr 1;11(4):308. doi: 10.3390/life11040308. Life (Basel). 2021. PMID: 33916135 Free PMC article. Review.
-
The Combinatorial Fusion Cascade to Generate the Standard Genetic Code.Life (Basel). 2021 Sep 16;11(9):975. doi: 10.3390/life11090975. Life (Basel). 2021. PMID: 34575125 Free PMC article.
References
-
- Crick F. H. C., The origin of the genetic code. J. Mol. Biol. 38, 367–379 (1968). - PubMed
-
- Orgel L. E., Evolution of the genetic apparatus: A review. Cold Spring Harb. Symp. Quant. Biol. 52, 9–16 (1987). - PubMed
-
- Walter G., The RNA world. Nature 319, 618 (1986).
-
- Attwater J., Wochner A., Pinheiro V. B., Coulson A., Holliger P., Ice as a protocellular medium for RNA replication. Nat. Commun. 1, 76 (2010). - PubMed
-
- Joyce G. F., Toward an alternative biology. Science 336, 307–308 (2012). - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
