

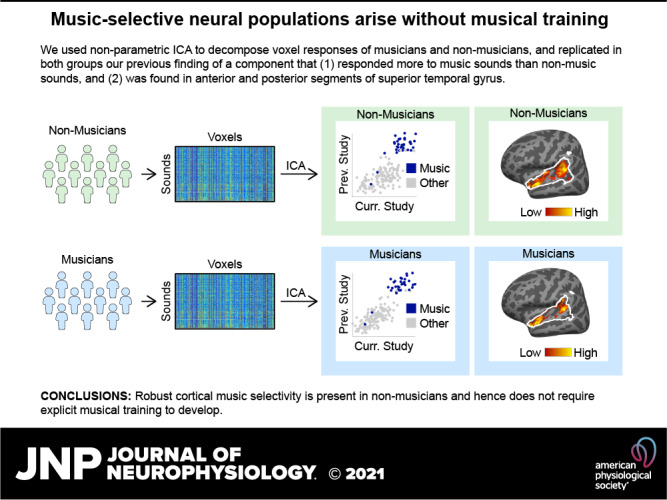
Music-selective neural populations arise without musical training
- PMID: 33596723
- PMCID: PMC8285655
- DOI: 10.1152/jn.00588.2020
Music-selective neural populations arise without musical training
Abstract
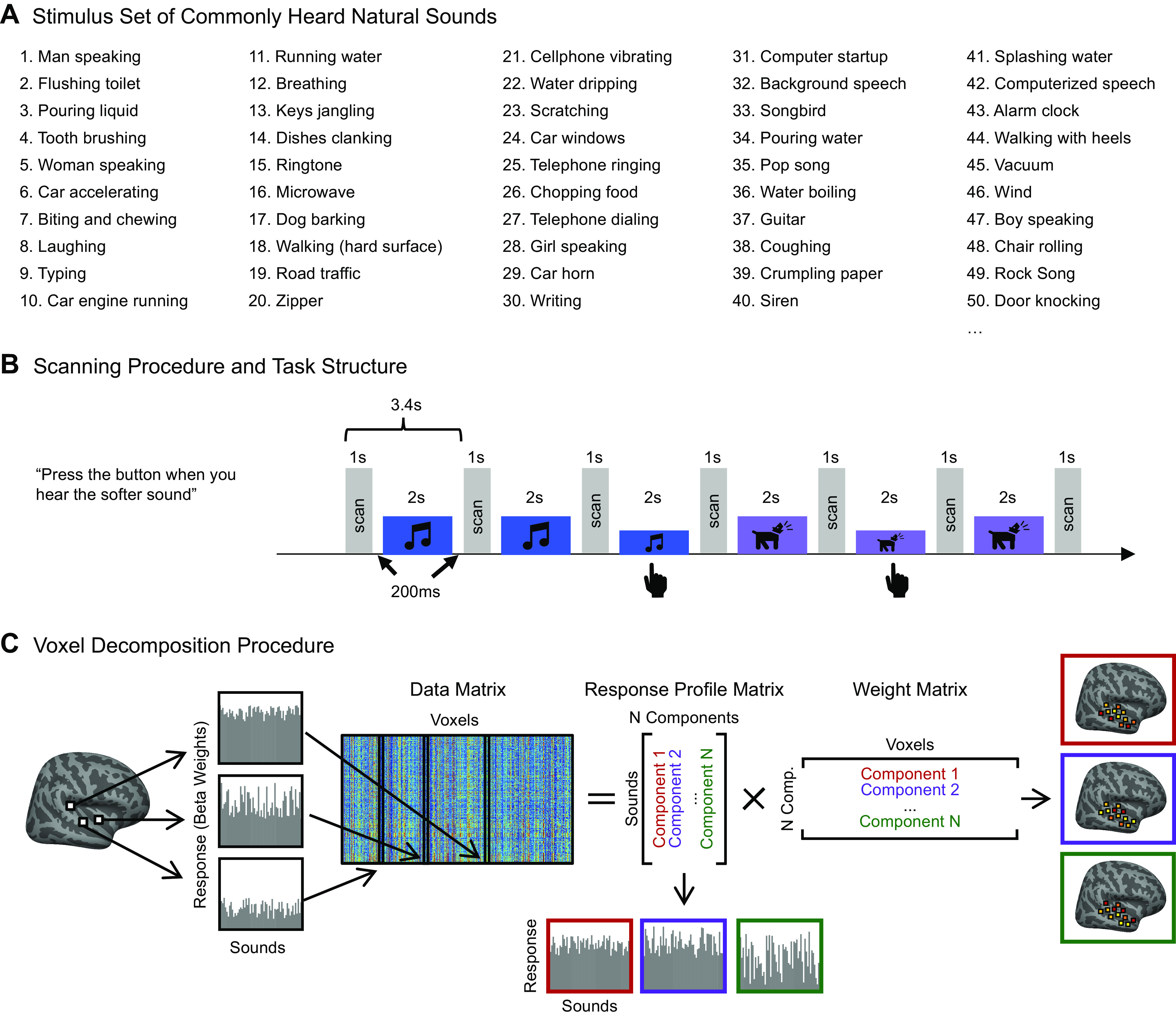
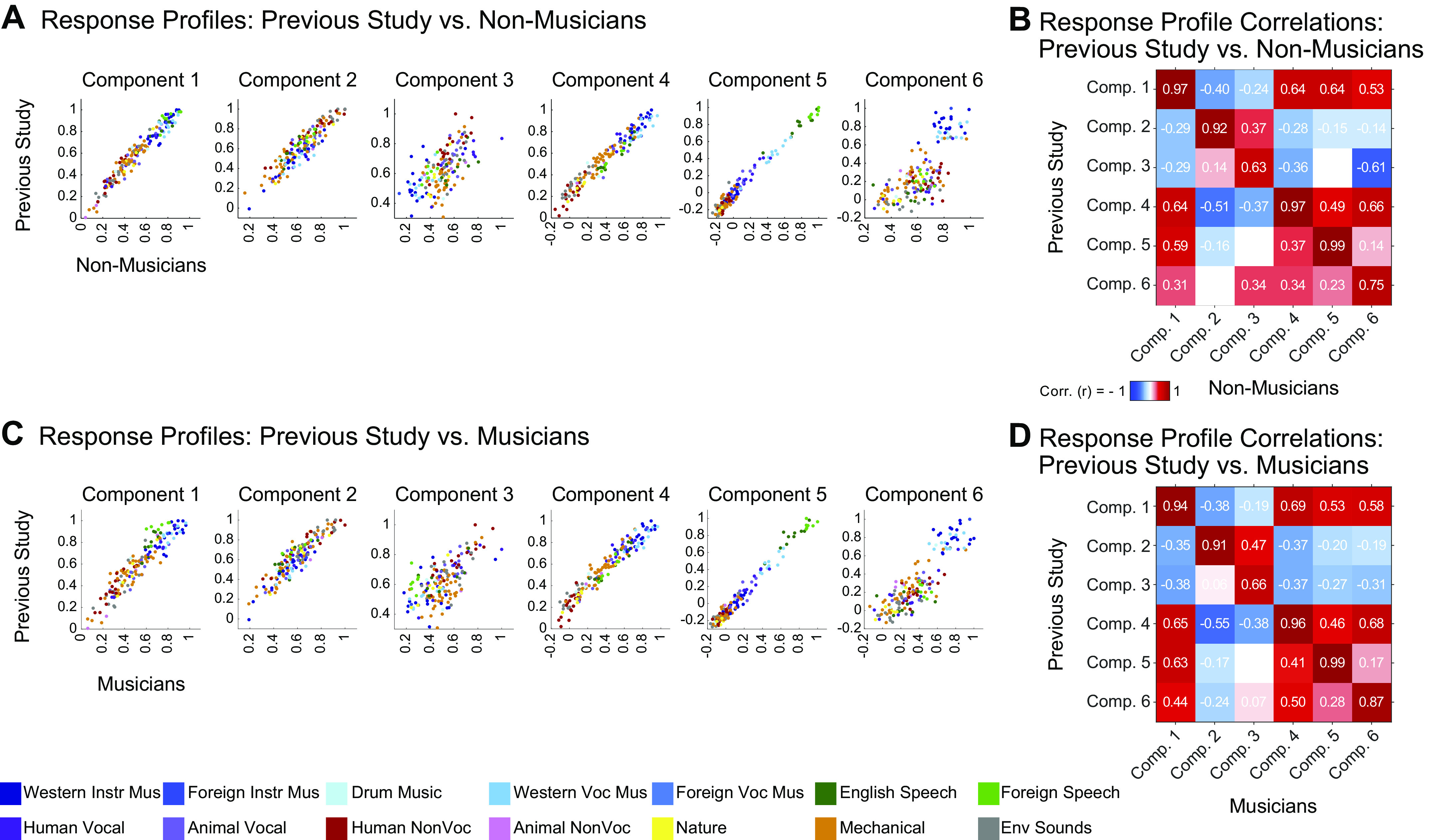
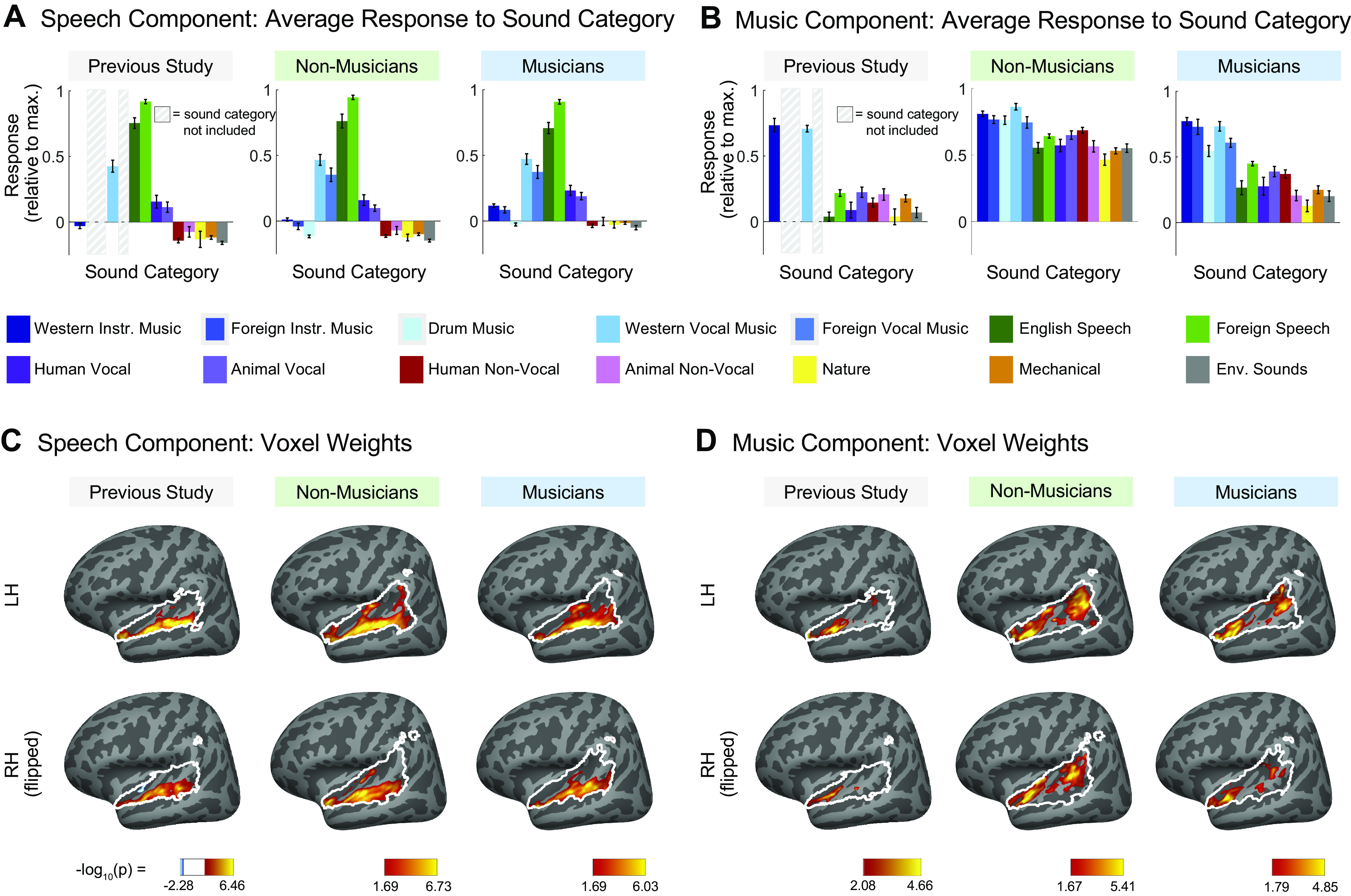
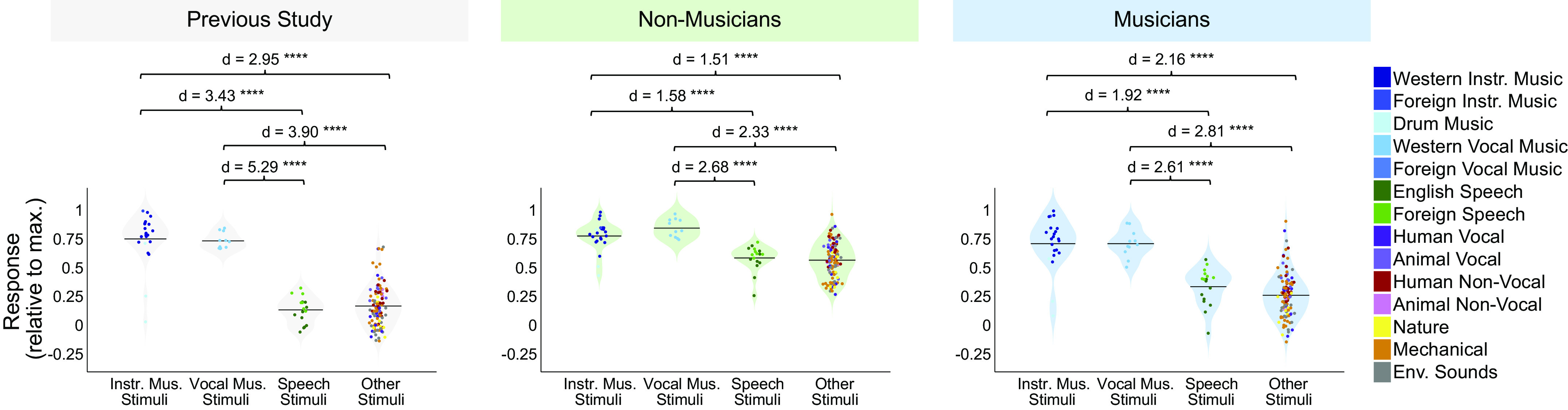
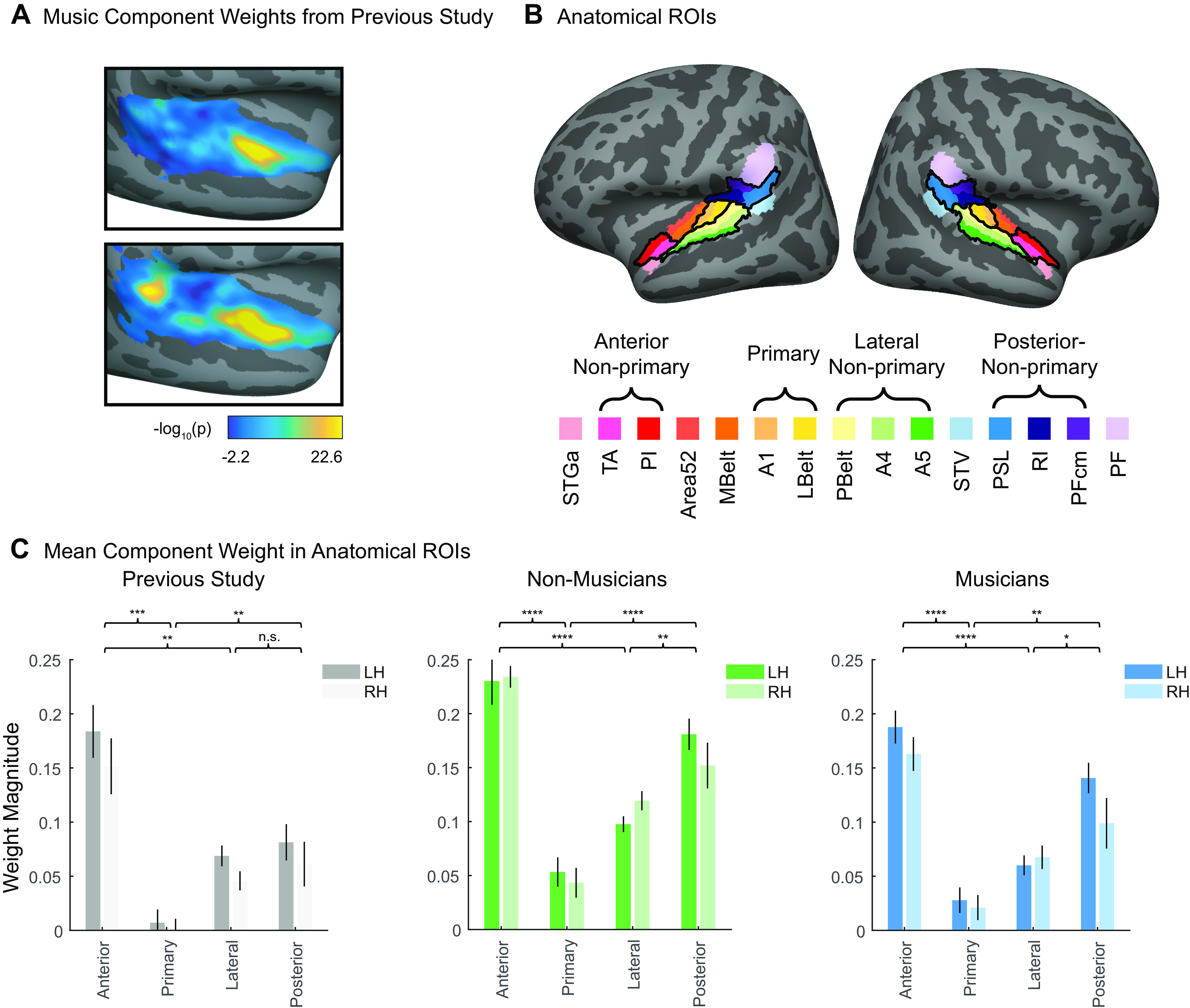
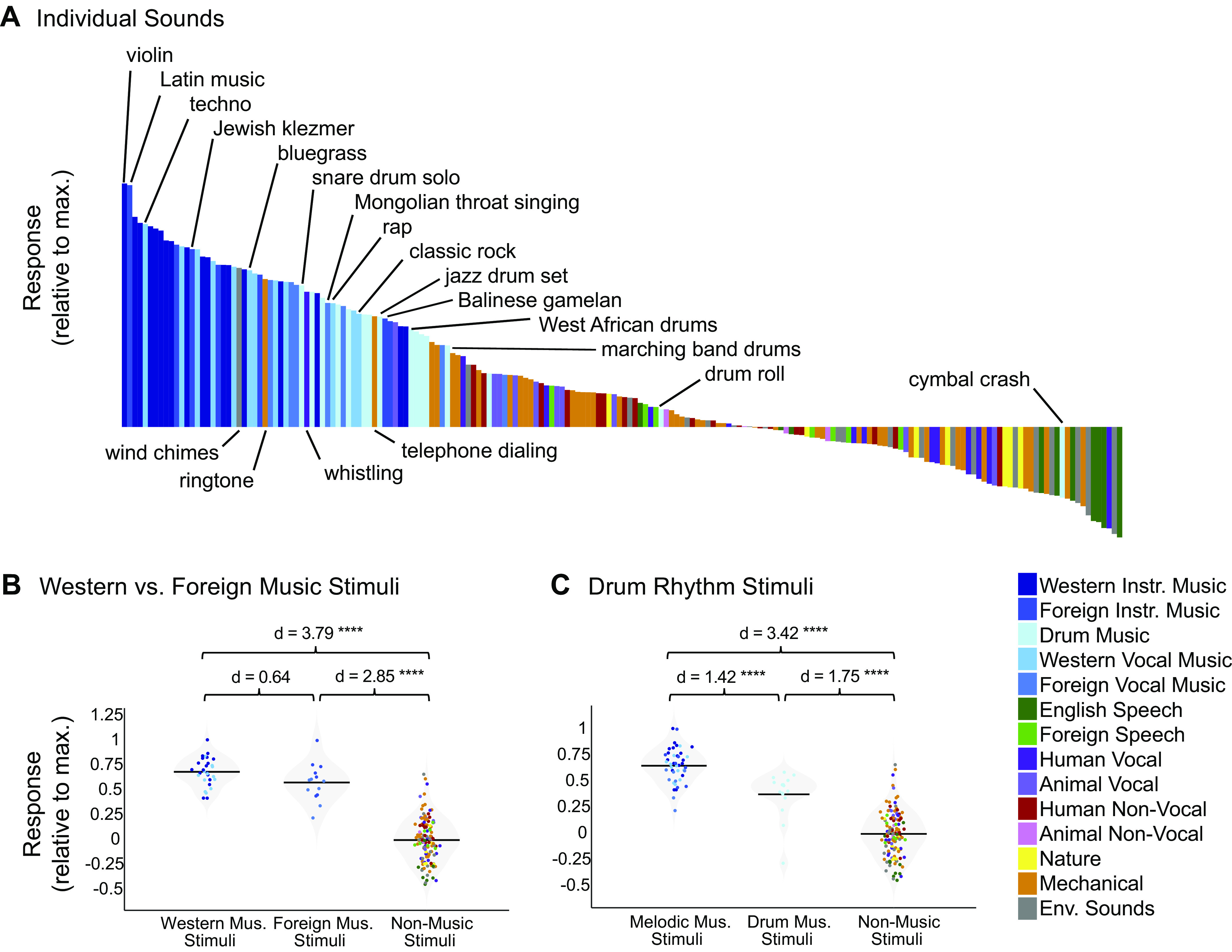
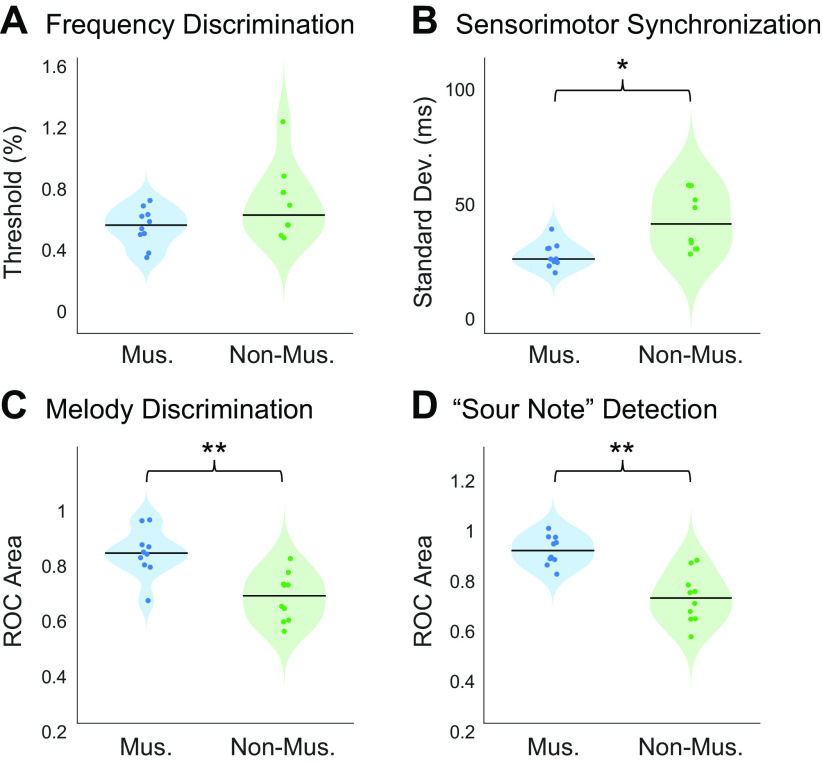
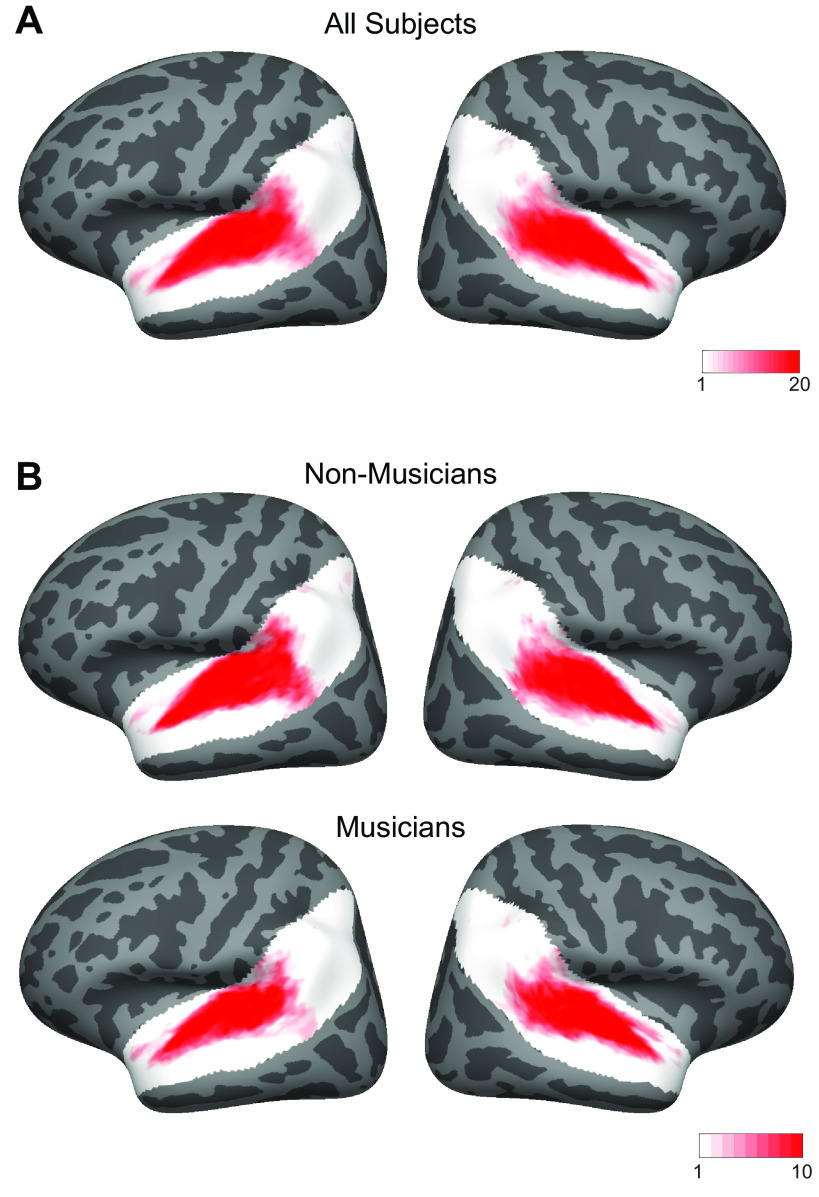
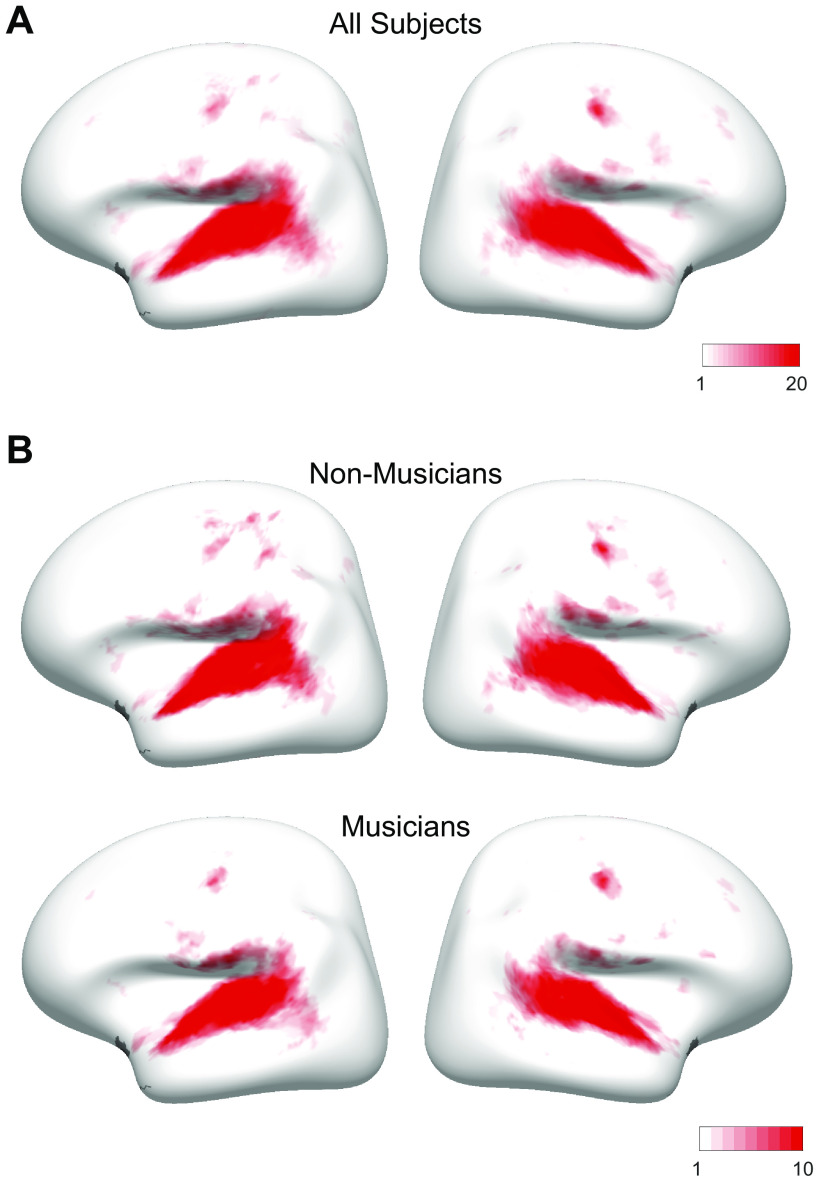
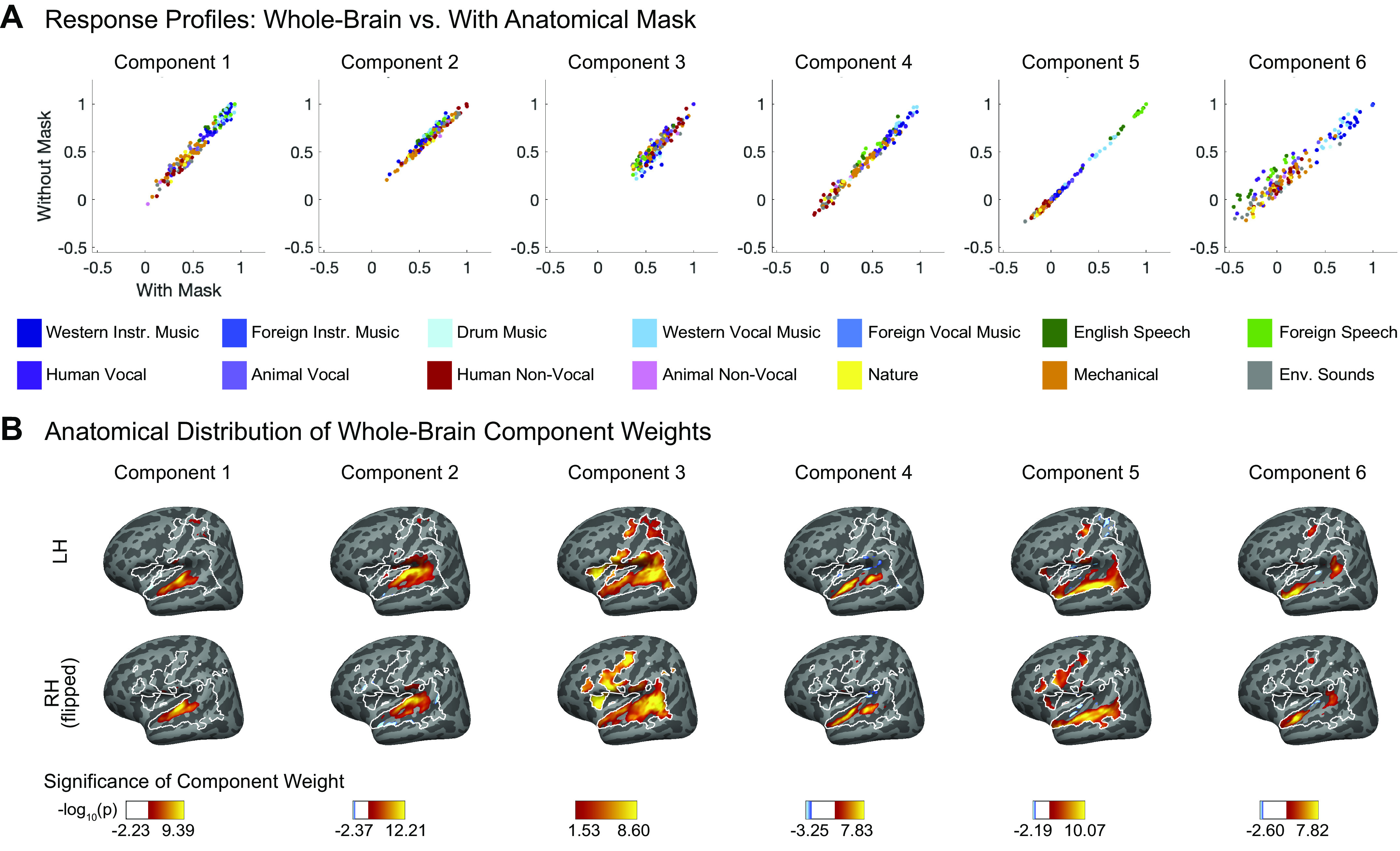
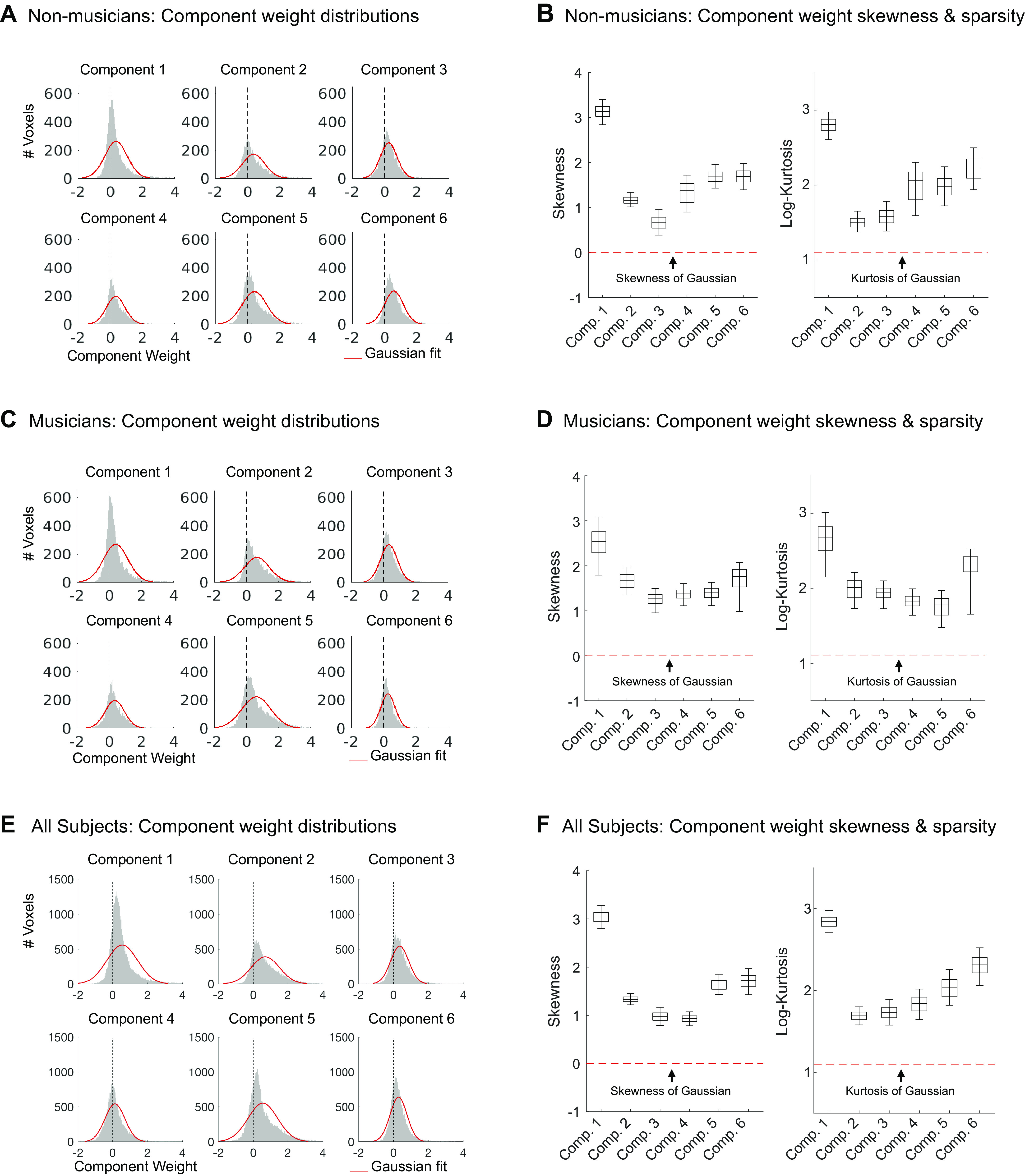
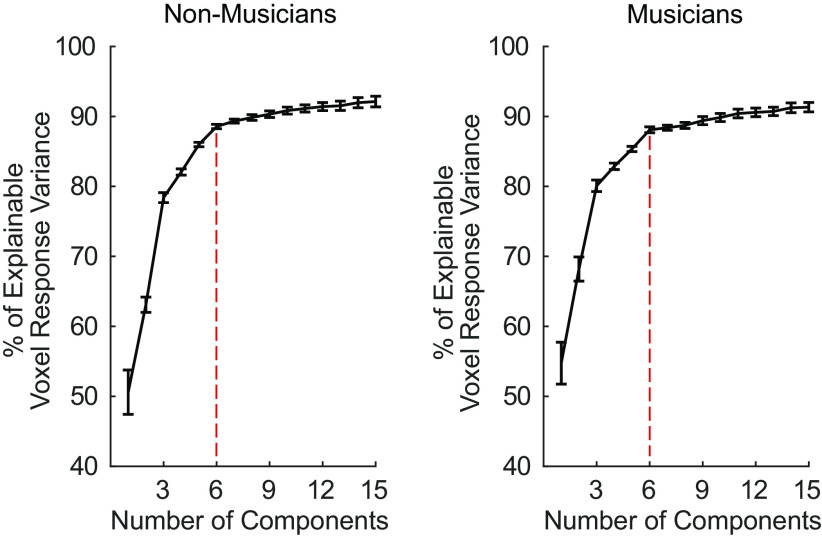
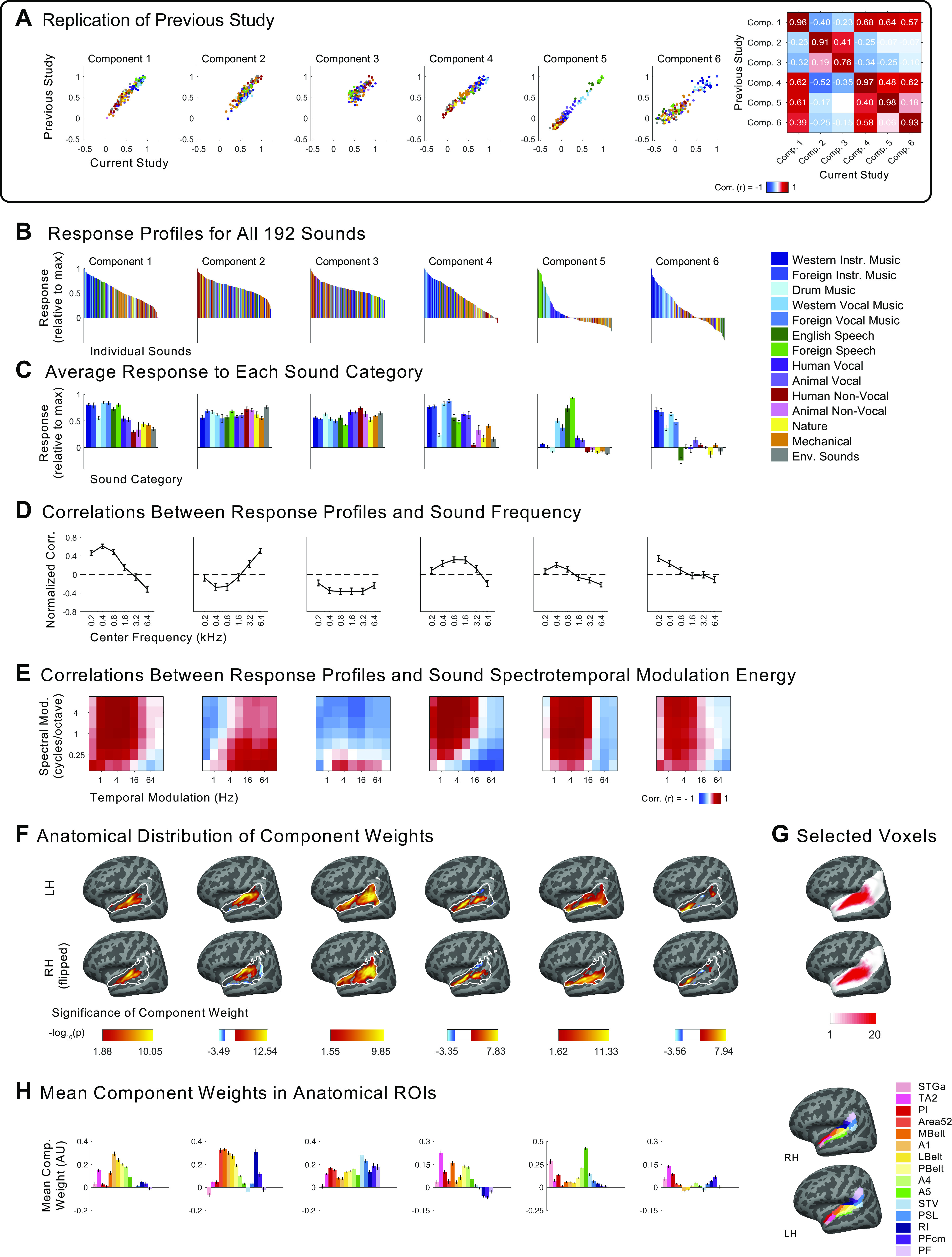
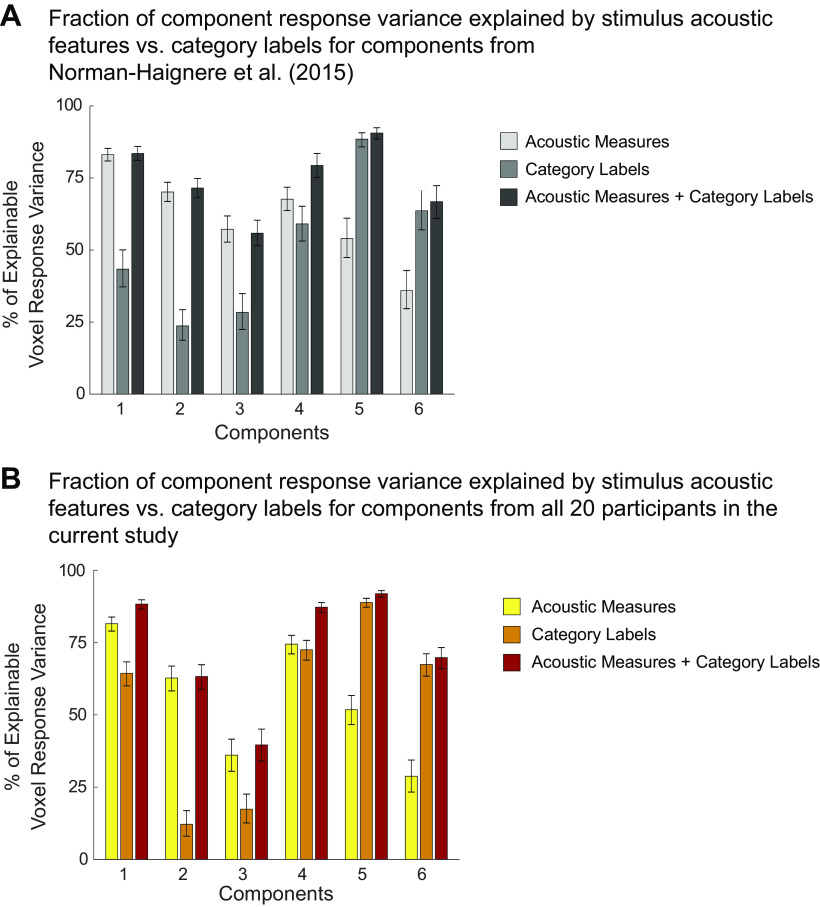
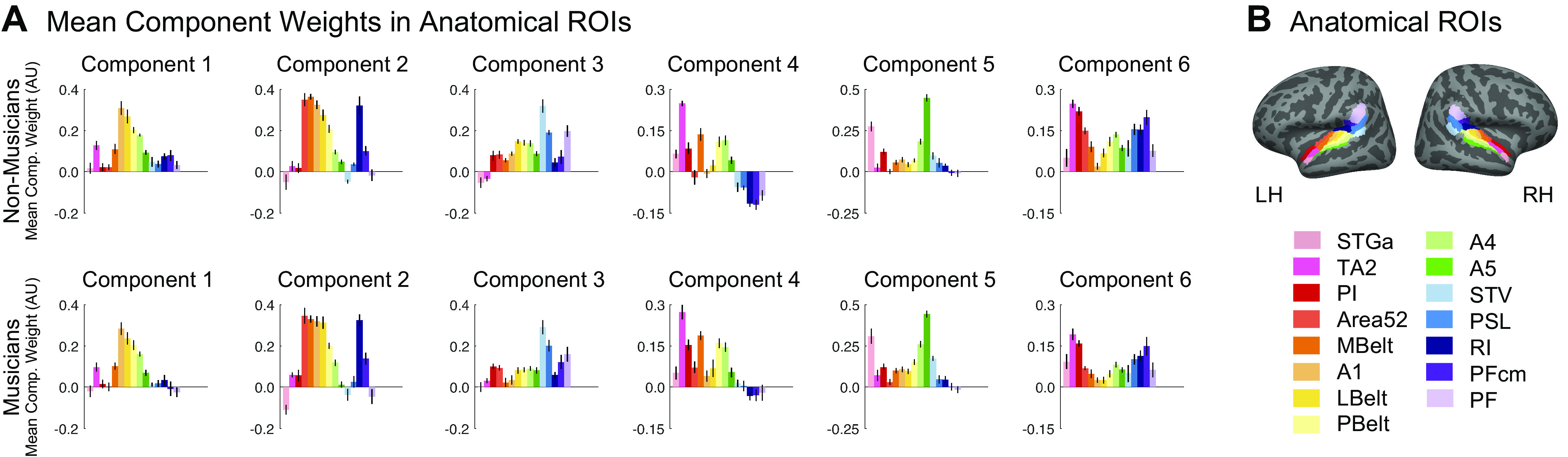
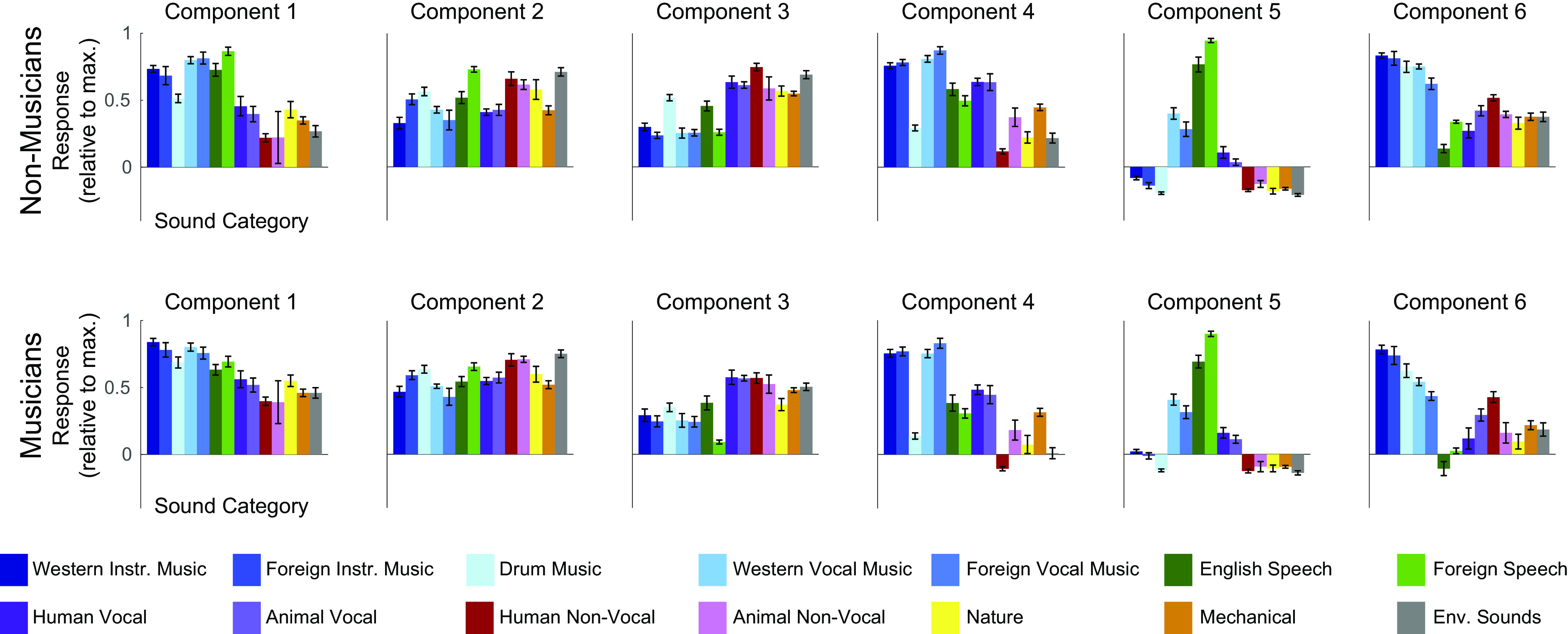
Recent work has shown that human auditory cortex contains neural populations anterior and posterior to primary auditory cortex that respond selectively to music. However, it is unknown how this selectivity for music arises. To test whether musical training is necessary, we measured fMRI responses to 192 natural sounds in 10 people with almost no musical training. When voxel responses were decomposed into underlying components, this group exhibited a music-selective component that was very similar in response profile and anatomical distribution to that previously seen in individuals with moderate musical training. We also found that musical genres that were less familiar to our participants (e.g., Balinese gamelan) produced strong responses within the music component, as did drum clips with rhythm but little melody, suggesting that these neural populations are broadly responsive to music as a whole. Our findings demonstrate that the signature properties of neural music selectivity do not require musical training to develop, showing that the music-selective neural populations are a fundamental and widespread property of the human brain.NEW & NOTEWORTHY We show that music-selective neural populations are clearly present in people without musical training, demonstrating that they are a fundamental and widespread property of the human brain. Additionally, we show music-selective neural populations respond strongly to music from unfamiliar genres as well as music with rhythm but little pitch information, suggesting that they are broadly responsive to music as a whole.
Keywords: auditory cortex; decomposition; expertise; fMRI; music.
Conflict of interest statement
No conflicts of interest, financial or otherwise, are declared by the authors.
Figures
Similar articles
-
Music listening engages specific cortical regions within the temporal lobes: differences between musicians and non-musicians.Cortex. 2014 Oct;59:126-37. doi: 10.1016/j.cortex.2014.07.013. Epub 2014 Aug 12. Cortex. 2014. PMID: 25173956
-
Capturing the musical brain with Lasso: Dynamic decoding of musical features from fMRI data.Neuroimage. 2014 Mar;88:170-80. doi: 10.1016/j.neuroimage.2013.11.017. Epub 2013 Nov 19. Neuroimage. 2014. PMID: 24269803
-
Functional asymmetry in primary auditory cortex for processing musical sounds: temporal pattern analysis of fMRI time series.Neuroreport. 2011 Jul 13;22(10):470-3. doi: 10.1097/WNR.0b013e3283475828. Neuroreport. 2011. PMID: 21642880
-
Effects of musical training on the auditory cortex in children.Ann N Y Acad Sci. 2003 Nov;999:506-13. doi: 10.1196/annals.1284.061. Ann N Y Acad Sci. 2003. PMID: 14681174 Review.
-
Structural and functional neural correlates of music perception.Anat Rec A Discov Mol Cell Evol Biol. 2006 Apr;288(4):435-46. doi: 10.1002/ar.a.20316. Anat Rec A Discov Mol Cell Evol Biol. 2006. PMID: 16550543 Review.
Cited by
-
Music in Noise: Neural Correlates Underlying Noise Tolerance in Music-Induced Emotion.Cereb Cortex Commun. 2021 Oct 13;2(4):tgab061. doi: 10.1093/texcom/tgab061. eCollection 2021. Cereb Cortex Commun. 2021. PMID: 34746792 Free PMC article.
-
Intraoperative cortical localization of music and language reveals signatures of structural complexity in posterior temporal cortex.iScience. 2023 Jun 28;26(7):107223. doi: 10.1016/j.isci.2023.107223. eCollection 2023 Jul 21. iScience. 2023. PMID: 37485361 Free PMC article.
-
Spontaneous emergence of rudimentary music detectors in deep neural networks.Nat Commun. 2024 Jan 2;15(1):148. doi: 10.1038/s41467-023-44516-0. Nat Commun. 2024. PMID: 38168097 Free PMC article.
-
Rostro-caudal networks for sound processing in the primate brain.Front Neurosci. 2022 Dec 15;16:1076374. doi: 10.3389/fnins.2022.1076374. eCollection 2022. Front Neurosci. 2022. PMID: 36590301 Free PMC article. Review.
-
Preliminary Evidence for Global Properties in Human Listeners During Natural Auditory Scene Perception.Open Mind (Camb). 2024 Mar 26;8:333-365. doi: 10.1162/opmi_a_00131. eCollection 2024. Open Mind (Camb). 2024. PMID: 38571530 Free PMC article.
References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources