

Bayesian binding and fusion models explain illusion and enhancement effects in audiovisual speech perception
- PMID: 33606815
- PMCID: PMC7895372
- DOI: 10.1371/journal.pone.0246986
Bayesian binding and fusion models explain illusion and enhancement effects in audiovisual speech perception
Abstract
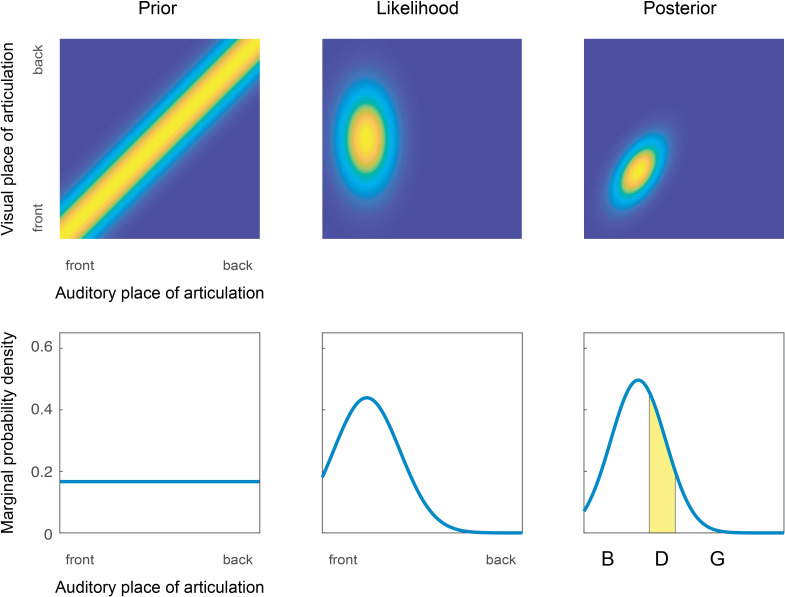
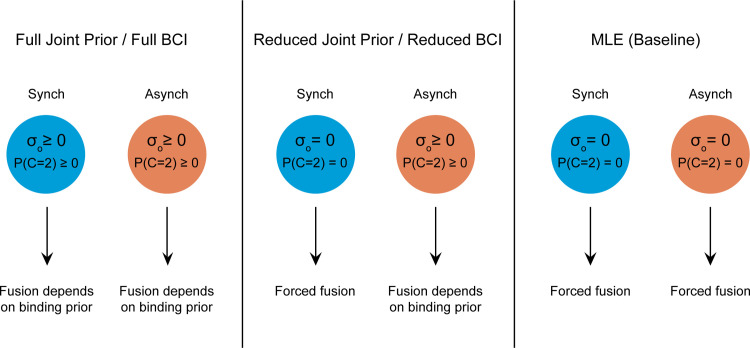
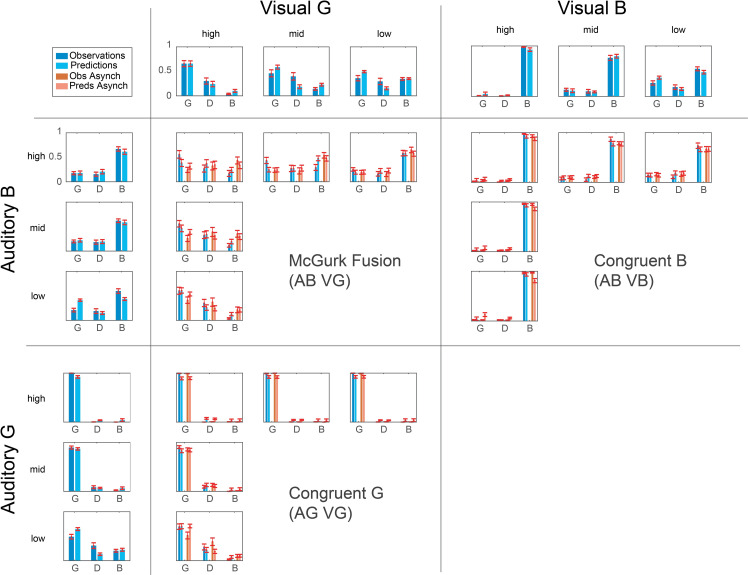
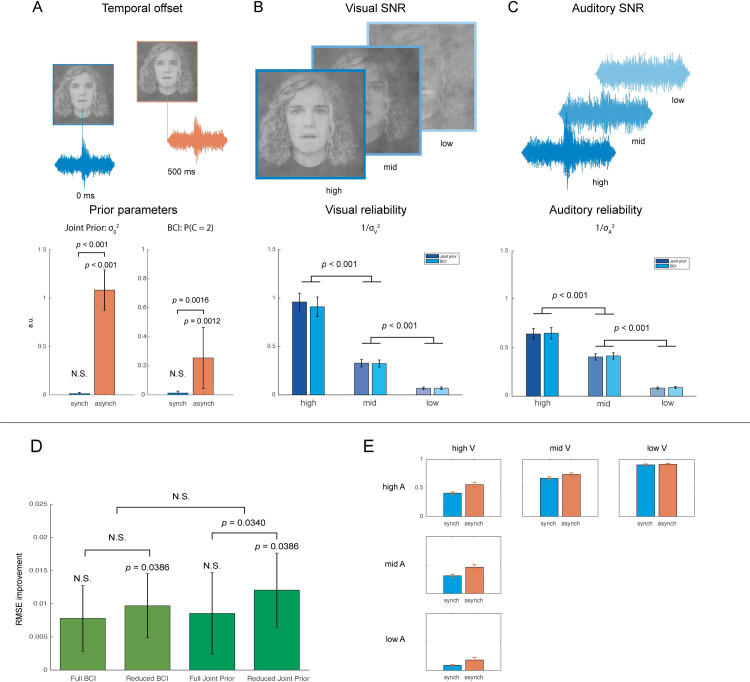
Speech is perceived with both the ears and the eyes. Adding congruent visual speech improves the perception of a faint auditory speech stimulus, whereas adding incongruent visual speech can alter the perception of the utterance. The latter phenomenon is the case of the McGurk illusion, where an auditory stimulus such as e.g. "ba" dubbed onto a visual stimulus such as "ga" produces the illusion of hearing "da". Bayesian models of multisensory perception suggest that both the enhancement and the illusion case can be described as a two-step process of binding (informed by prior knowledge) and fusion (informed by the information reliability of each sensory cue). However, there is to date no study which has accounted for how they each contribute to audiovisual speech perception. In this study, we expose subjects to both congruent and incongruent audiovisual speech, manipulating the binding and the fusion stages simultaneously. This is done by varying both temporal offset (binding) and auditory and visual signal-to-noise ratio (fusion). We fit two Bayesian models to the behavioural data and show that they can both account for the enhancement effect in congruent audiovisual speech, as well as the McGurk illusion. This modelling approach allows us to disentangle the effects of binding and fusion on behavioural responses. Moreover, we find that these models have greater predictive power than a forced fusion model. This study provides a systematic and quantitative approach to measuring audiovisual integration in the perception of the McGurk illusion as well as congruent audiovisual speech, which we hope will inform future work on audiovisual speech perception.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Sumby WH, Pollack I. Visual Contribution to Speech Intelligibility in Noise. J Acoust Soc Am. 1954;26: 212–215. 10.1121/1.1907309 - DOI
-
- Massaro DW. Perceiving talking faces: from speech perception to a behavioral principle. Cambridge, Mass: MIT Press; 1998.
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
