

The inverse variance-flatness relation in stochastic gradient descent is critical for finding flat minima
- PMID: 33619091
- PMCID: PMC7936325
- DOI: 10.1073/pnas.2015617118
The inverse variance-flatness relation in stochastic gradient descent is critical for finding flat minima
Abstract
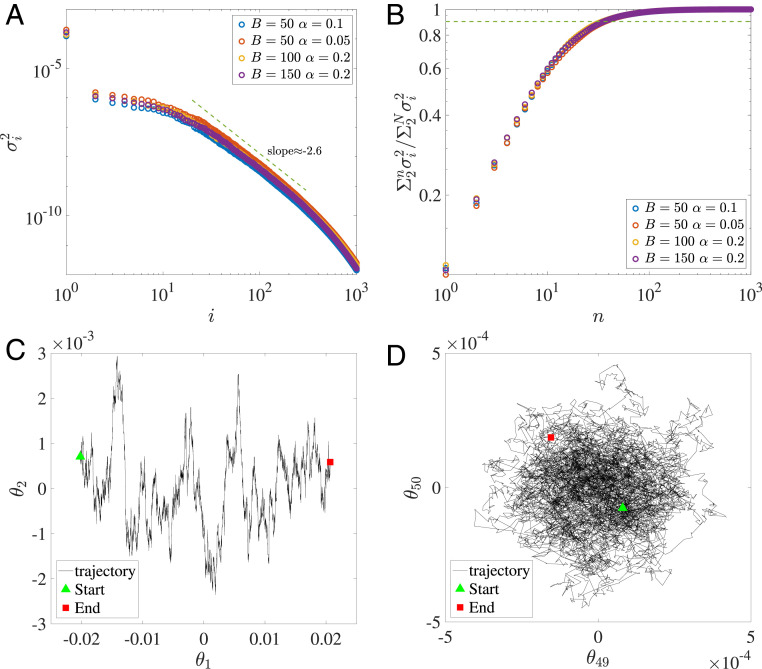
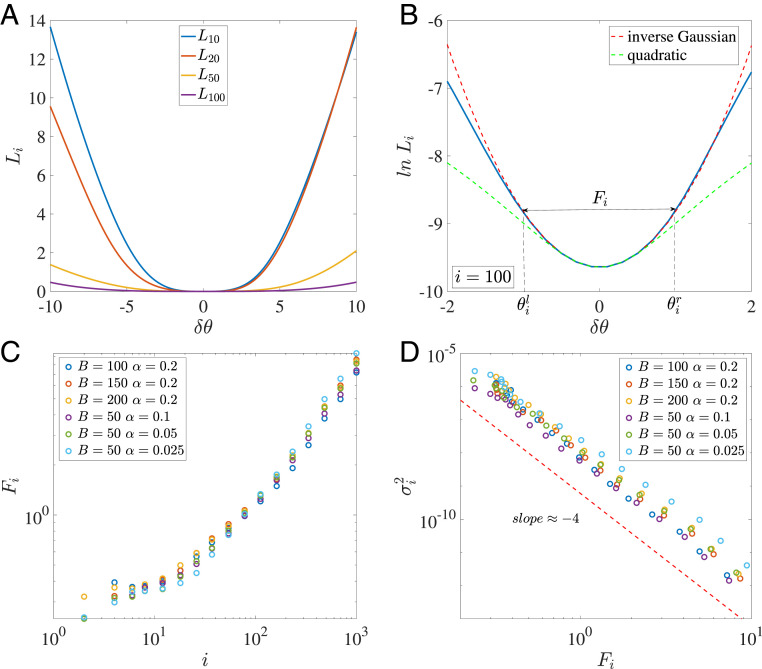
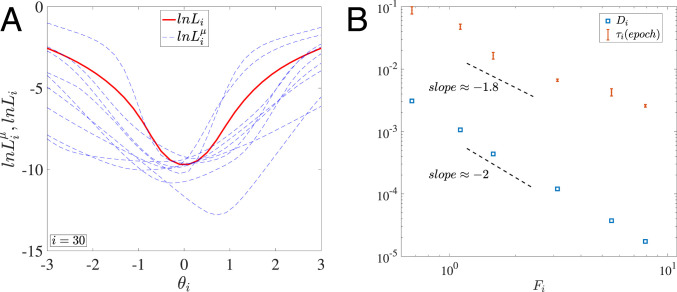
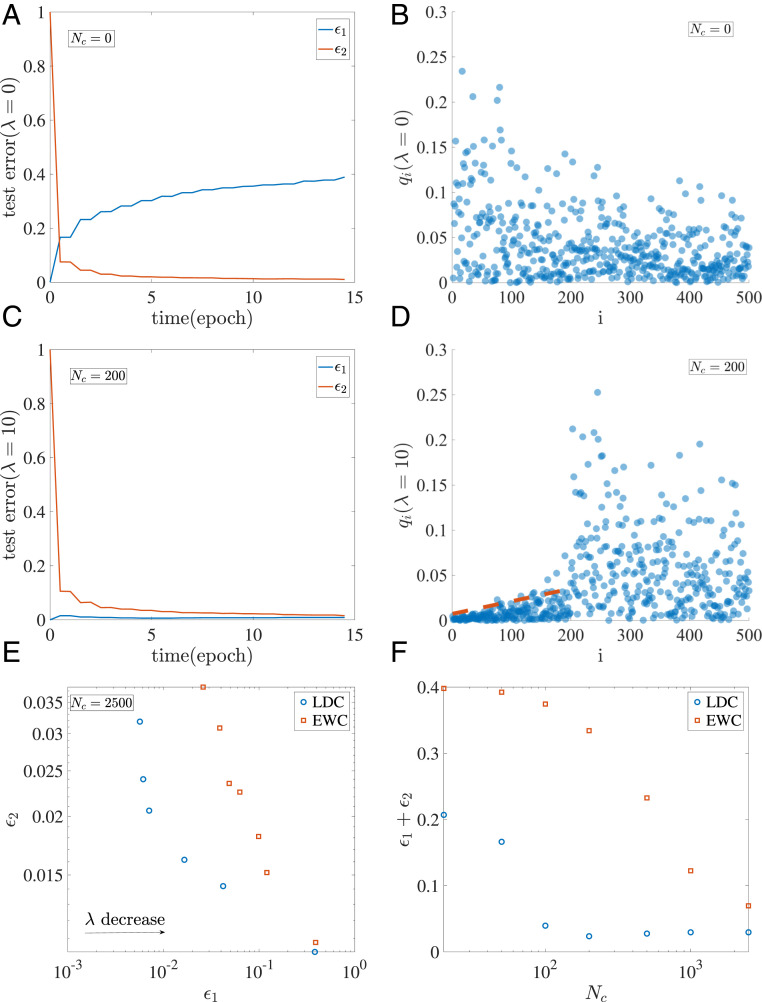
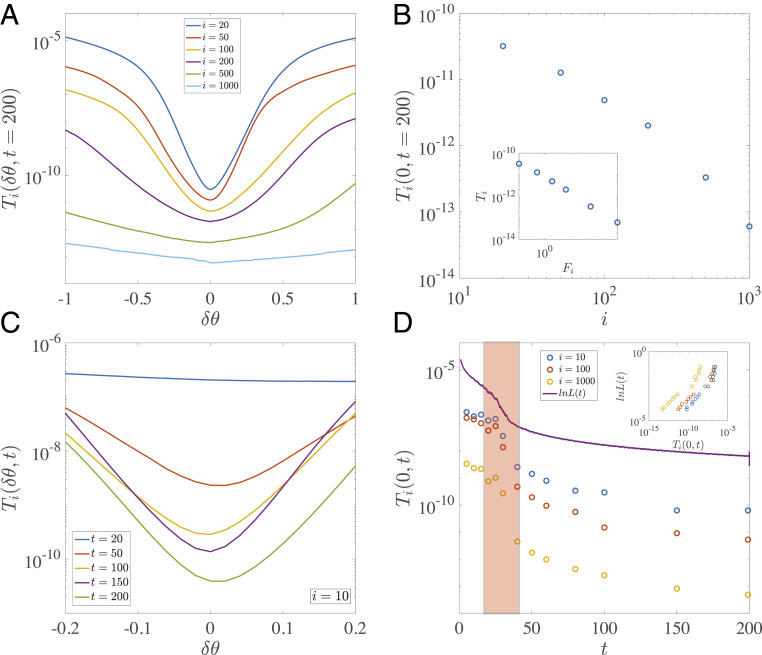
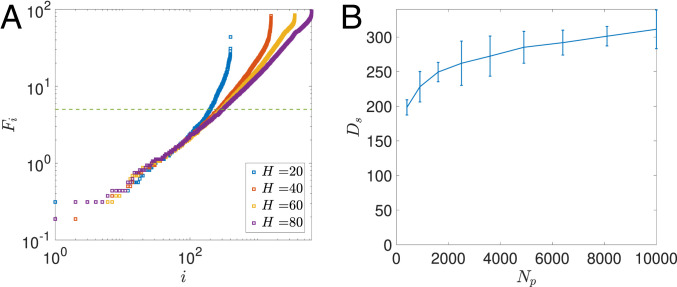
Despite tremendous success of the stochastic gradient descent (SGD) algorithm in deep learning, little is known about how SGD finds generalizable solutions at flat minima of the loss function in high-dimensional weight space. Here, we investigate the connection between SGD learning dynamics and the loss function landscape. A principal component analysis (PCA) shows that SGD dynamics follow a low-dimensional drift-diffusion motion in the weight space. Around a solution found by SGD, the loss function landscape can be characterized by its flatness in each PCA direction. Remarkably, our study reveals a robust inverse relation between the weight variance and the landscape flatness in all PCA directions, which is the opposite to the fluctuation-response relation (aka Einstein relation) in equilibrium statistical physics. To understand the inverse variance-flatness relation, we develop a phenomenological theory of SGD based on statistical properties of the ensemble of minibatch loss functions. We find that both the anisotropic SGD noise strength (temperature) and its correlation time depend inversely on the landscape flatness in each PCA direction. Our results suggest that SGD serves as a landscape-dependent annealing algorithm. The effective temperature decreases with the landscape flatness so the system seeks out (prefers) flat minima over sharp ones. Based on these insights, an algorithm with landscape-dependent constraints is developed to mitigate catastrophic forgetting efficiently when learning multiple tasks sequentially. In general, our work provides a theoretical framework to understand learning dynamics, which may eventually lead to better algorithms for different learning tasks.
Keywords: generalization; loss landscape; machine learning; statistical physics; stochastic gradient descent.
Conflict of interest statement
The authors declare no competing interest.
Figures
Similar articles
-
Stochastic Gradient Descent Introduces an Effective Landscape-Dependent Regularization Favoring Flat Solutions.Phys Rev Lett. 2023 Jun 9;130(23):237101. doi: 10.1103/PhysRevLett.130.237101. Phys Rev Lett. 2023. PMID: 37354404
-
Anomalous diffusion dynamics of learning in deep neural networks.Neural Netw. 2022 May;149:18-28. doi: 10.1016/j.neunet.2022.01.019. Epub 2022 Feb 3. Neural Netw. 2022. PMID: 35182851
-
A mean field view of the landscape of two-layer neural networks.Proc Natl Acad Sci U S A. 2018 Aug 14;115(33):E7665-E7671. doi: 10.1073/pnas.1806579115. Epub 2018 Jul 27. Proc Natl Acad Sci U S A. 2018. PMID: 30054315 Free PMC article.
-
Shaping the learning landscape in neural networks around wide flat minima.Proc Natl Acad Sci U S A. 2020 Jan 7;117(1):161-170. doi: 10.1073/pnas.1908636117. Epub 2019 Dec 23. Proc Natl Acad Sci U S A. 2020. PMID: 31871189 Free PMC article.
-
Machine learning and deep learning methods that use omics data for metastasis prediction.Comput Struct Biotechnol J. 2021 Sep 4;19:5008-5018. doi: 10.1016/j.csbj.2021.09.001. eCollection 2021. Comput Struct Biotechnol J. 2021. PMID: 34589181 Free PMC article. Review.
Cited by
-
On the different regimes of stochastic gradient descent.Proc Natl Acad Sci U S A. 2024 Feb 27;121(9):e2316301121. doi: 10.1073/pnas.2316301121. Epub 2024 Feb 20. Proc Natl Acad Sci U S A. 2024. PMID: 38377198 Free PMC article.
-
Topology, vorticity, and limit cycle in a stabilized Kuramoto-Sivashinsky equation.Proc Natl Acad Sci U S A. 2022 Dec 6;119(49):e2211359119. doi: 10.1073/pnas.2211359119. Epub 2022 Dec 2. Proc Natl Acad Sci U S A. 2022. PMID: 36459639 Free PMC article.
-
Machine learning meets physics: A two-way street.Proc Natl Acad Sci U S A. 2024 Jul 2;121(27):e2403580121. doi: 10.1073/pnas.2403580121. Epub 2024 Jun 24. Proc Natl Acad Sci U S A. 2024. PMID: 38913898 Free PMC article. No abstract available.
-
Thermodynamics of the Ising Model Encoded in Restricted Boltzmann Machines.Entropy (Basel). 2022 Nov 22;24(12):1701. doi: 10.3390/e24121701. Entropy (Basel). 2022. PMID: 36554106 Free PMC article.
-
Understanding cytoskeletal avalanches using mechanical stability analysis.Proc Natl Acad Sci U S A. 2021 Oct 12;118(41):e2110239118. doi: 10.1073/pnas.2110239118. Proc Natl Acad Sci U S A. 2021. PMID: 34611021 Free PMC article.
References
-
- LeCun Y., Bengio Y., Hinton G., Deep learning. Nature 521, 436–444 (2015). - PubMed
-
- Robbins H., Monro S., A stochastic approximation method. Ann. Math. Stat. 22, 400–407 (1951).
-
- Bottou L. “Large-scale machine learning with stochastic gradient descent” in Proceedings of COMPSTAT’2010, Lechevallier Y., Saporta G., Eds. (Physica-Verlag HD, Heidelberg, Germany, 2010), pp. 177–186.
-
- Hinton G. E., van Camp D., “Keeping the neural networks simple by minimizing the description length of the weights” in Proceedings of the Sixth Annual Conference on Computational Learning Theory, COLT ‘93, L. Pitt, Ed. (ACM, New York, NY, 1993), pp. 5–13.
-
- Hochreiter S., Schmidhuber J., Flat minima. Neural Comput. 9, 1–42 (1997). - PubMed
LinkOut - more resources
Full Text Sources
Other Literature Sources
