

Multiomics Data Collection, Visualization, and Utilization for Guiding Metabolic Engineering
- PMID: 33634086
- PMCID: PMC7902046
- DOI: 10.3389/fbioe.2021.612893
Multiomics Data Collection, Visualization, and Utilization for Guiding Metabolic Engineering
Abstract
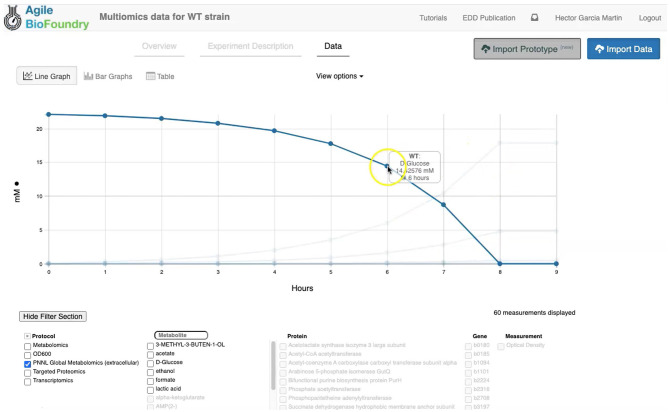
Biology has changed radically in the past two decades, growing from a purely descriptive science into also a design science. The availability of tools that enable the precise modification of cells, as well as the ability to collect large amounts of multimodal data, open the possibility of sophisticated bioengineering to produce fuels, specialty and commodity chemicals, materials, and other renewable bioproducts. However, despite new tools and exponentially increasing data volumes, synthetic biology cannot yet fulfill its true potential due to our inability to predict the behavior of biological systems. Here, we showcase a set of computational tools that, combined, provide the ability to store, visualize, and leverage multiomics data to predict the outcome of bioengineering efforts. We show how to upload, visualize, and output multiomics data, as well as strain information, into online repositories for several isoprenol-producing strain designs. We then use these data to train machine learning algorithms that recommend new strain designs that are correctly predicted to improve isoprenol production by 23%. This demonstration is done by using synthetic data, as provided by a novel library, that can produce credible multiomics data for testing algorithms and computational tools. In short, this paper provides a step-by-step tutorial to leverage these computational tools to improve production in bioengineered strains.
Keywords: biofuels; flux analysis; machine learning; metabolic engineering; multiomics analysis; synthetic biology.
Copyright © 2021 Roy, Radivojevic, Forrer, Marti, Jonnalagadda, Backman, Morrell, Plahar, Kim, Hillson and Garcia Martin.
Conflict of interest statement
NH declares financial interests in TeselaGen Biotechnologies, and Ansa Biotechnologies. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures








References
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous