

Estimating the cumulative incidence of SARS-CoV-2 with imperfect serological tests: Exploiting cutoff-free approaches
- PMID: 33635863
- PMCID: PMC7946301
- DOI: 10.1371/journal.pcbi.1008728
Estimating the cumulative incidence of SARS-CoV-2 with imperfect serological tests: Exploiting cutoff-free approaches
Abstract
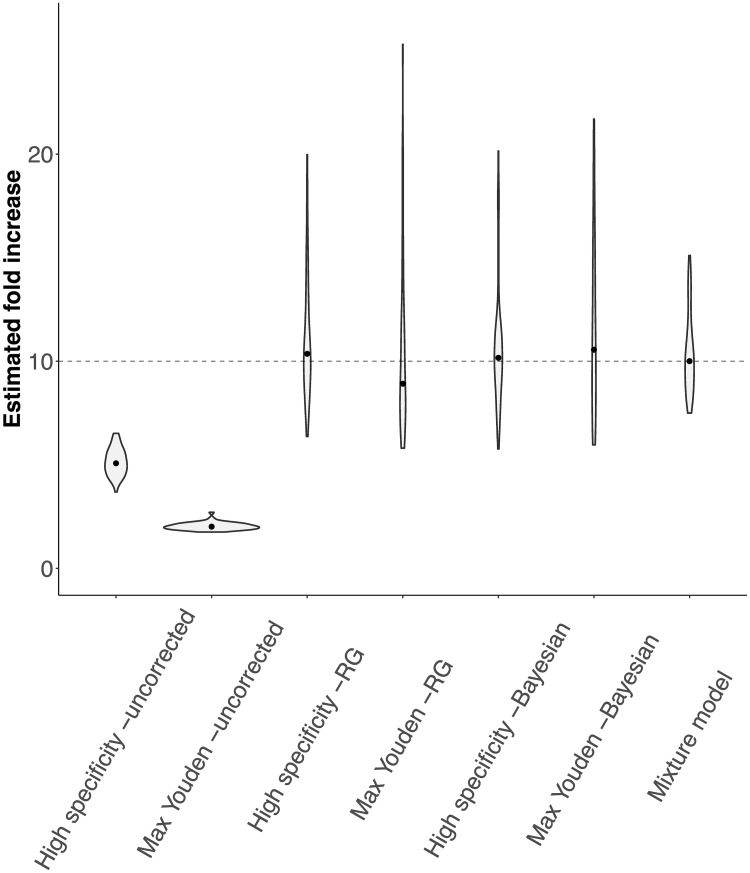
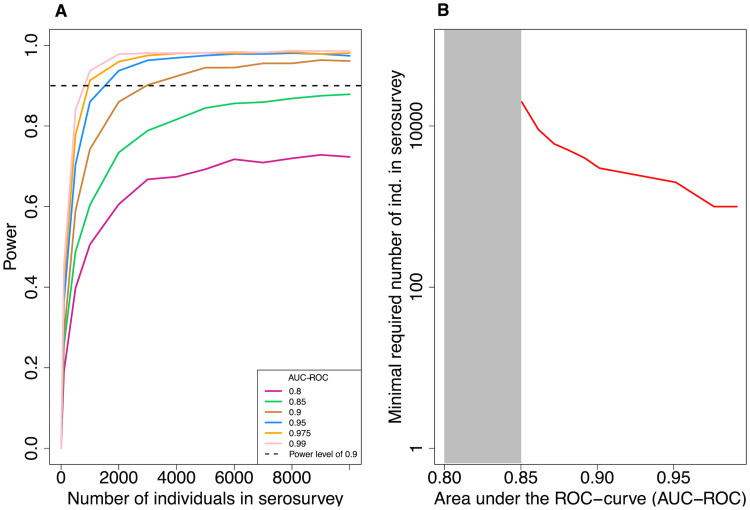
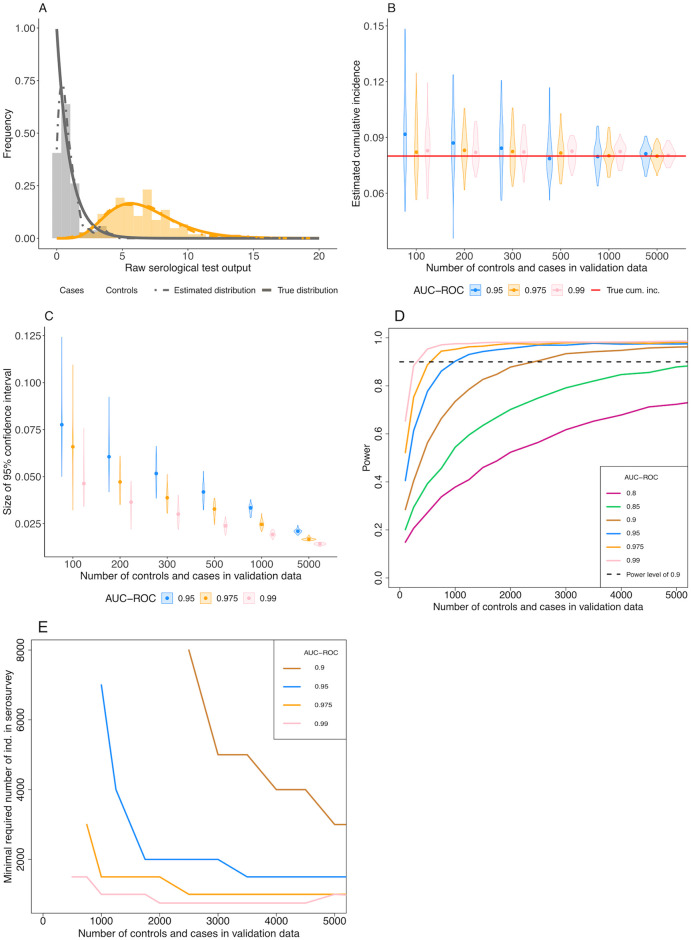
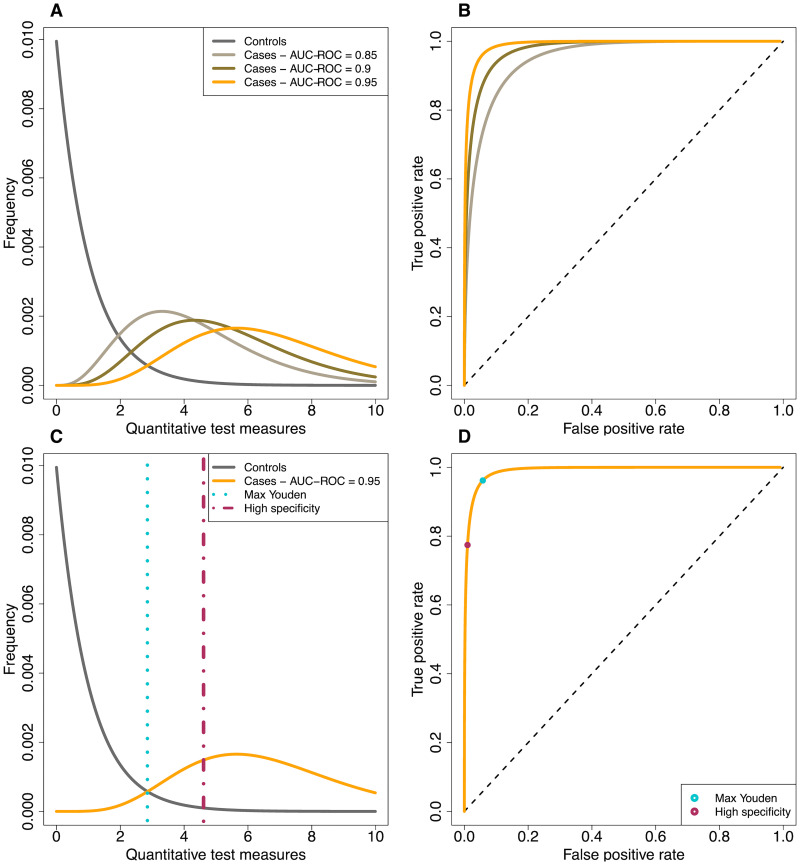
Large-scale serological testing in the population is essential to determine the true extent of the current SARS-CoV-2 pandemic. Serological tests measure antibody responses against pathogens and use predefined cutoff levels that dichotomize the quantitative test measures into sero-positives and negatives and use this as a proxy for past infection. With the imperfect assays that are currently available to test for past SARS-CoV-2 infection, the fraction of seropositive individuals in serosurveys is a biased estimator of the cumulative incidence and is usually corrected to account for the sensitivity and specificity. Here we use an inference method-referred to as mixture-model approach-for the estimation of the cumulative incidence that does not require to define cutoffs by integrating the quantitative test measures directly into the statistical inference procedure. We confirm that the mixture model outperforms the methods based on cutoffs, leading to less bias and error in estimates of the cumulative incidence. We illustrate how the mixture model can be used to optimize the design of serosurveys with imperfect serological tests. We also provide guidance on the number of control and case sera that are required to quantify the test's ambiguity sufficiently to enable the reliable estimation of the cumulative incidence. Lastly, we show how this approach can be used to estimate the cumulative incidence of classes of infections with an unknown distribution of quantitative test measures. This is a very promising application of the mixture-model approach that could identify the elusive fraction of asymptomatic SARS-CoV-2 infections. An R-package implementing the inference methods used in this paper is provided. Our study advocates using serological tests without cutoffs, especially if they are used to determine parameters characterizing populations rather than individuals. This approach circumvents some of the shortcomings of cutoff-based methods at exactly the low cumulative incidence levels and test accuracies that we are currently facing in SARS-CoV-2 serosurveys.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures



Similar articles
-
Evaluating a SARS-CoV-2 screening strategy based on serological tests.Epidemiol Prev. 2020 Sep-Dec;44(5-6 Suppl 2):193-199. doi: 10.19191/EP20.5-6.S2.118. Epidemiol Prev. 2020. PMID: 33412810 English.
-
Single-Dilution COVID-19 Antibody Test with Qualitative and Quantitative Readouts.mSphere. 2021 Apr 21;6(2):e00224-21. doi: 10.1128/mSphere.00224-21. mSphere. 2021. PMID: 33883259 Free PMC article.
-
Serological Assays for Assessing Postvaccination SARS-CoV-2 Antibody Response.Microbiol Spectr. 2021 Oct 31;9(2):e0073321. doi: 10.1128/Spectrum.00733-21. Epub 2021 Sep 29. Microbiol Spectr. 2021. PMID: 34585943 Free PMC article.
-
Serological antibody testing in the COVID-19 pandemic: their molecular basis and applications.Biochem Soc Trans. 2020 Dec 18;48(6):2851-2863. doi: 10.1042/BST20200744. Biochem Soc Trans. 2020. PMID: 33170924 Review.
-
In vitro diagnostics of coronavirus disease 2019: Technologies and application.J Microbiol Immunol Infect. 2021 Apr;54(2):164-174. doi: 10.1016/j.jmii.2020.05.016. Epub 2020 Jun 5. J Microbiol Immunol Infect. 2021. PMID: 32513617 Free PMC article. Review.
Cited by
-
Correcting for Antibody Waning in Cumulative Incidence Estimation From Sequential Serosurveys.Am J Epidemiol. 2024 May 7;193(5):777-786. doi: 10.1093/aje/kwad226. Am J Epidemiol. 2024. PMID: 38012125 Free PMC article.
-
A Bayesian approach to estimating COVID-19 incidence and infection fatality rates.Biostatistics. 2024 Apr 15;25(2):354-384. doi: 10.1093/biostatistics/kxad003. Biostatistics. 2024. PMID: 36881693 Free PMC article.
-
Estimating SARS-CoV-2 infection probabilities with serological data and a Bayesian mixture model.Sci Rep. 2024 Apr 25;14(1):9503. doi: 10.1038/s41598-024-60060-3. Sci Rep. 2024. PMID: 38664455 Free PMC article.
-
A Mixture Model for Estimating SARS-CoV-2 Seroprevalence in Chennai, India.Am J Epidemiol. 2023 Sep 1;192(9):1552-1561. doi: 10.1093/aje/kwad103. Am J Epidemiol. 2023. PMID: 37084085 Free PMC article.
-
Estimating cutoff values for diagnostic tests to achieve target specificity using extreme value theory.BMC Med Res Methodol. 2024 Feb 8;24(1):30. doi: 10.1186/s12874-023-02139-5. BMC Med Res Methodol. 2024. PMID: 38331732 Free PMC article.
References
-
- Johns Hopkins Center for Health Security. Global Progress on COVID-19 Serology-Based Testing Johns Hopkins Center for Health Security. 2020 Apr 13. URL: http://www.centerforhealthsecurity.org/resources/COVID-19/serology/Serol....
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
